 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale Robustness Analysis of Video Action Recognition Models
Jul 04, 2022



We have seen a great progress in video action recognition in recent years. There are several models based on convolutional neural network (CNN) with some recent transformer based approaches which provide state-of-the-art performance on existing benchmark datasets. However, large-scale robustness has not been studied for these models which is a critical aspect for real-world applications. In this work we perform a large-scale robustness analysis of these existing models for video action recognition. We mainly focus on robustness against distribution shifts due to real-world perturbations instead of adversarial perturbations. We propose four different benchmark datasets, HMDB-51P, UCF-101P, Kinetics-400P, and SSv2P and study the robustness of six different state-of-the-art action recognition models against 90 different perturbations. The study reveals some interesting findings, 1) transformer based models are consistently more robust against most of the perturbations when compared with CNN based models, 2) Pretraining helps Transformer based models to be more robust to different perturbations than CNN based models, and 3) All of the studied models are robust to temporal perturbation on the Kinetics dataset, but not on SSv2; this suggests temporal information is much more important for action label prediction on SSv2 datasets than on the Kinetics dataset. We hope that this study will serve as a benchmark for future research in robust video action recognition. More details about the project are available at https://rose-ar.github.io/.
LARNet: Latent Action Representation for Human Action Synthesis
Oct 27, 2021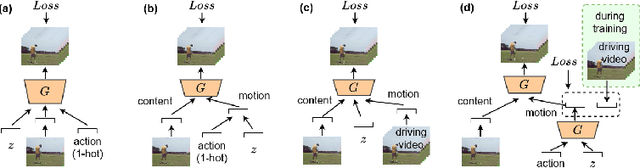
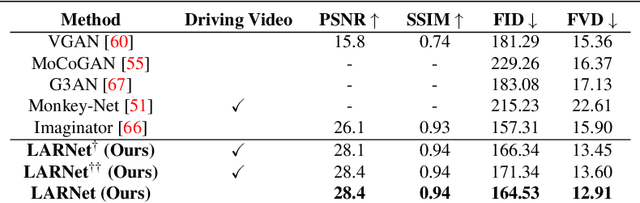
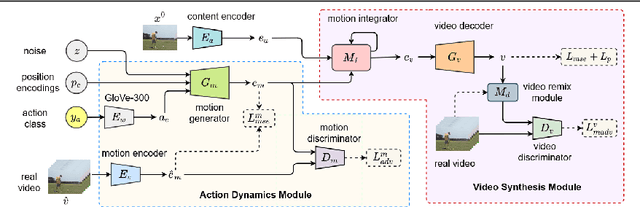
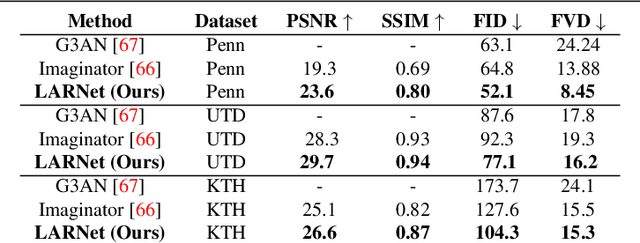
We present LARNet, a novel end-to-end approach for generating human action videos. A joint generative modeling of appearance and dynamics to synthesize a video is very challenging and therefore recent works in video synthesis have proposed to decompose these two factors. However, these methods require a driving video to model the video dynamics. In this work, we propose a generative approach instead, which explicitly learns action dynamics in latent space avoiding the need of a driving video during inference. The generated action dynamics is integrated with the appearance using a recurrent hierarchical structure which induces motion at different scales to focus on both coarse as well as fine level action details. In addition, we propose a novel mix-adversarial loss function which aims at improving the temporal coherency of synthesized videos. We evaluate the proposed approach on four real-world human action datasets demonstrating the effectiveness of the proposed approach in generating human actions. Code available at https://github.com/aayushjr/larnet.
"Knights": First Place Submission for VIPriors21 Action Recognition Challenge at ICCV 2021
Oct 14, 2021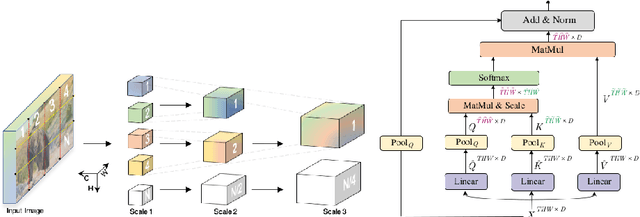
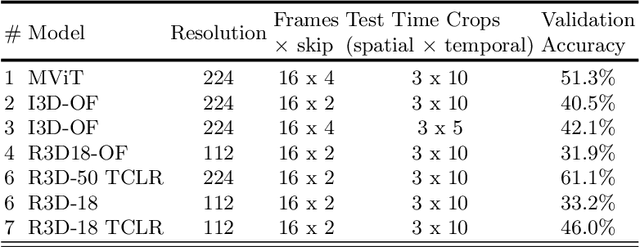
This technical report presents our approach "Knights" to solve the action recognition task on a small subset of Kinetics-400 i.e. Kinetics400ViPriors without using any extra-data. Our approach has 3 main components: state-of-the-art Temporal Contrastive self-supervised pretraining, video transformer models, and optical flow modality. Along with the use of standard test-time augmentation, our proposed solution achieves 73% on Kinetics400ViPriors test set, which is the best among all of the other entries Visual Inductive Priors for Data-Efficient Computer Vision's Action Recognition Challenge, ICCV 2021.