Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Knights": First Place Submission for VIPriors21 Action Recognition Challenge at ICCV 2021
Paper and Code
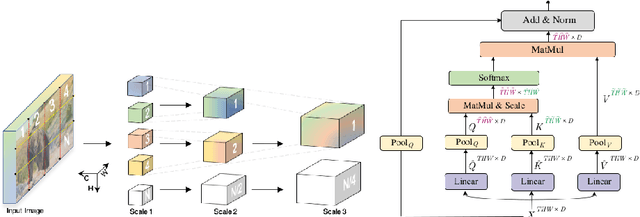
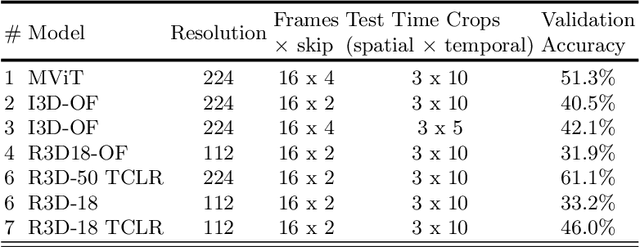
This technical report presents our approach "Knights" to solve the action recognition task on a small subset of Kinetics-400 i.e. Kinetics400ViPriors without using any extra-data. Our approach has 3 main components: state-of-the-art Temporal Contrastive self-supervised pretraining, video transformer models, and optical flow modality. Along with the use of standard test-time augmentation, our proposed solution achieves 73% on Kinetics400ViPriors test set, which is the best among all of the other entries Visual Inductive Priors for Data-Efficient Computer Vision's Action Recognition Challenge, ICCV 2021.
* Challenge results are available at
https://vipriors.github.io/challenges/#action-recognition
View paper on