 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgocentric RGB+Depth Action Recognition in Industry-Like Settings
Sep 25, 2023
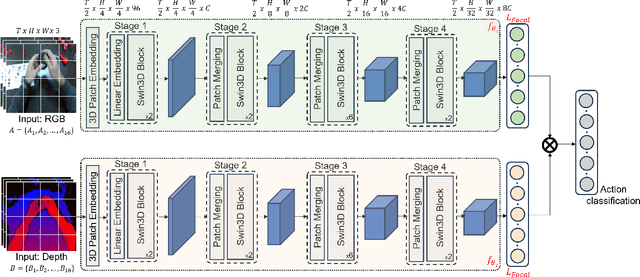
Action recognition from an egocentric viewpoint is a crucial perception task in robotics and enables a wide range of human-robot interactions. While most computer vision approaches prioritize the RGB camera, the Depth modality - which can further amplify the subtleties of actions from an egocentric perspective - remains underexplored. Our work focuses on recognizing actions from egocentric RGB and Depth modalities in an industry-like environment. To study this problem, we consider the recent MECCANO dataset, which provides a wide range of assembling actions. Our framework is based on the 3D Video SWIN Transformer to encode both RGB and Depth modalities effectively. To address the inherent skewness in real-world multimodal action occurrences, we propose a training strategy using an exponentially decaying variant of the focal loss modulating factor. Additionally, to leverage the information in both RGB and Depth modalities, we opt for late fusion to combine the predictions from each modality. We thoroughly evaluate our method on the action recognition task of the MECCANO dataset, and it significantly outperforms the prior work. Notably, our method also secured first place at the multimodal action recognition challenge at ICIAP 2023.
Ensemble Modeling for Multimodal Visual Action Recognition
Aug 10, 2023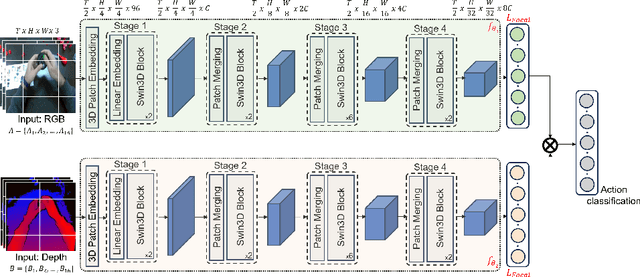
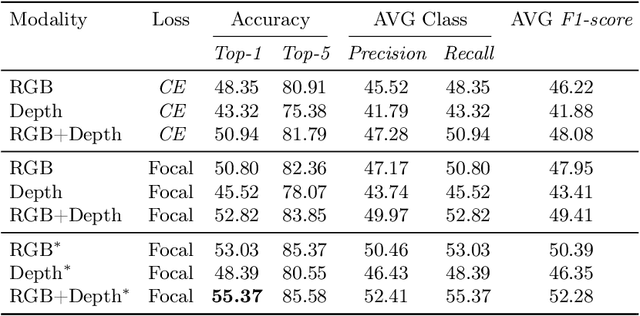
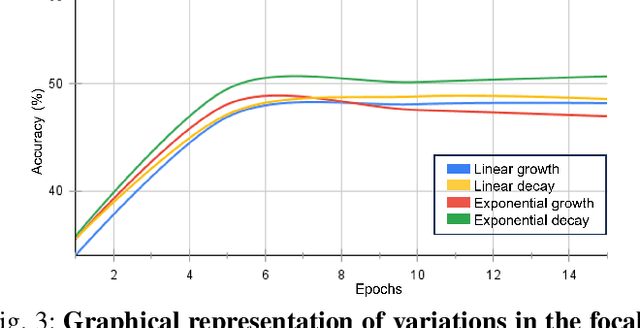
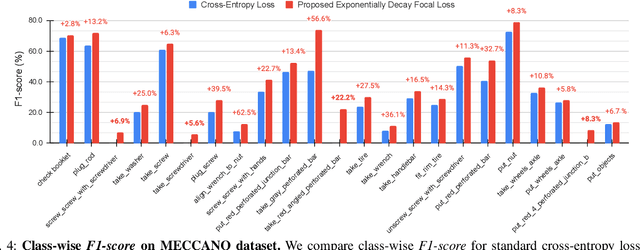
In this work, we propose an ensemble modeling approach for multimodal action recognition. We independently train individual modality models using a variant of focal loss tailored to handle the long-tailed distribution of the MECCANO [21] dataset. Based on the underlying principle of focal loss, which captures the relationship between tail (scarce) classes and their prediction difficulties, we propose an exponentially decaying variant of focal loss for our current task. It initially emphasizes learning from the hard misclassified examples and gradually adapts to the entire range of examples in the dataset. This annealing process encourages the model to strike a balance between focusing on the sparse set of hard samples, while still leveraging the information provided by the easier ones. Additionally, we opt for the late fusion strategy to combine the resultant probability distributions from RGB and Depth modalities for final action prediction. Experimental evaluations on the MECCANO dataset demonstrate the effectiveness of our approach.
"Knights": First Place Submission for VIPriors21 Action Recognition Challenge at ICCV 2021
Oct 14, 2021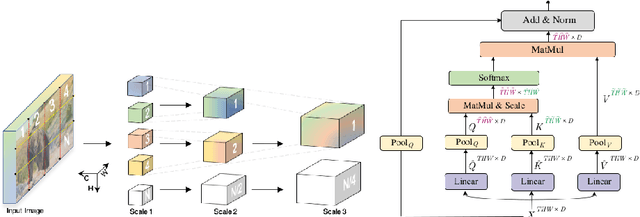
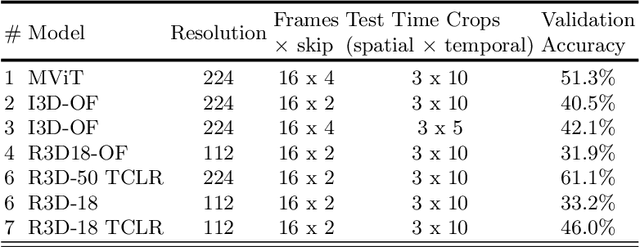
This technical report presents our approach "Knights" to solve the action recognition task on a small subset of Kinetics-400 i.e. Kinetics400ViPriors without using any extra-data. Our approach has 3 main components: state-of-the-art Temporal Contrastive self-supervised pretraining, video transformer models, and optical flow modality. Along with the use of standard test-time augmentation, our proposed solution achieves 73% on Kinetics400ViPriors test set, which is the best among all of the other entries Visual Inductive Priors for Data-Efficient Computer Vision's Action Recognition Challenge, ICCV 2021.
TCLR: Temporal Contrastive Learning for Video Representation
Feb 04, 2021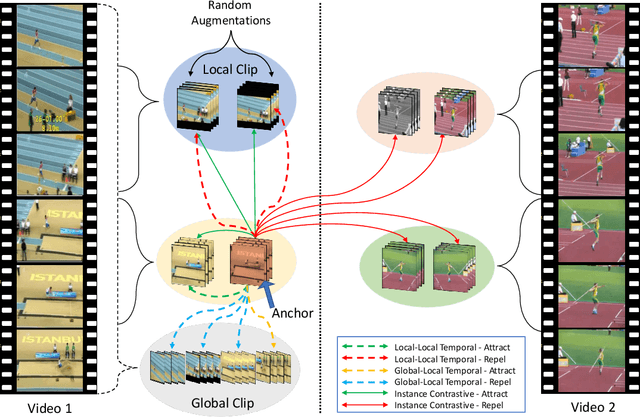
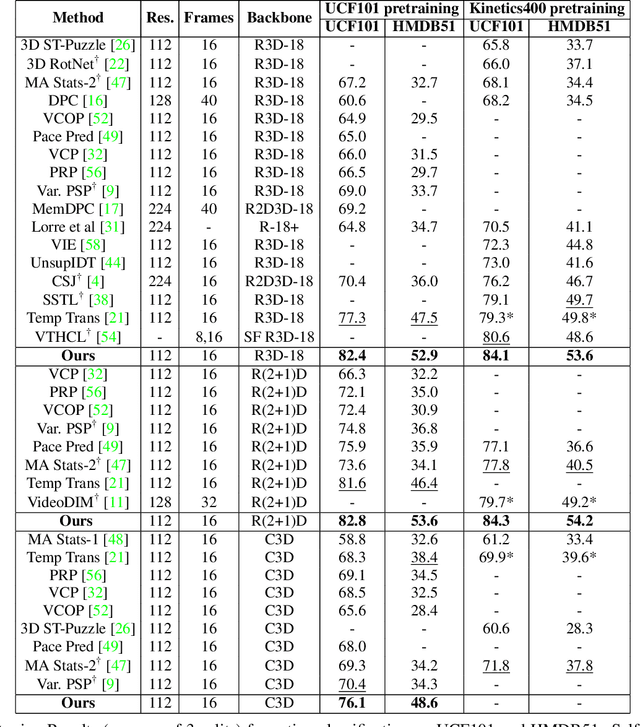
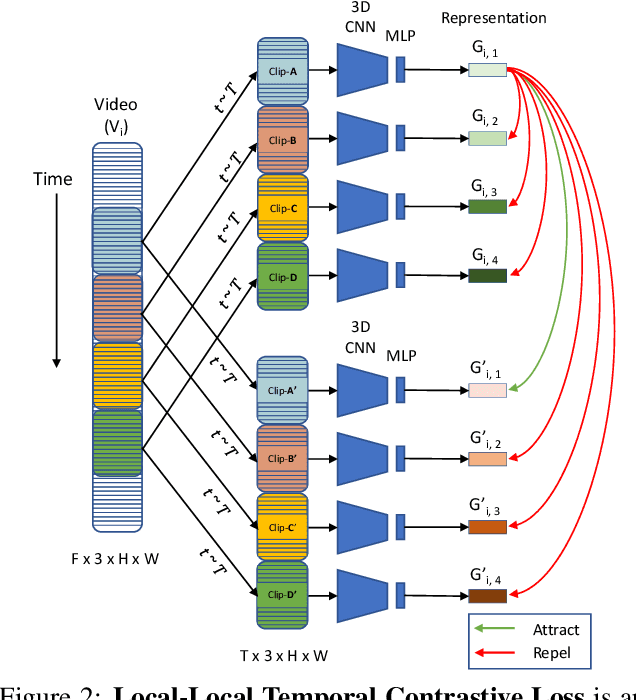

Contrastive learning has nearly closed the gap between supervised and self-supervised learning of image representations. Existing extensions of contrastive learning to the domain of video data however do not explicitly attempt to represent the internal distinctiveness across the temporal dimension of video clips. We develop a new temporal contrastive learning framework consisting of two novel losses to improve upon existing contrastive self-supervised video representation learning methods. The first loss adds the task of discriminating between non-overlapping clips from the same video, whereas the second loss aims to discriminate between timesteps of the feature map of an input clip in order to increase the temporal diversity of the features. Temporal contrastive learning achieves significant improvement over the state-of-the-art results in downstream video understanding tasks such as action recognition, limited-label action classification, and nearest-neighbor video retrieval on video datasets across multiple 3D CNN architectures. With the commonly used 3D-ResNet-18 architecture, we achieve 82.4% (+5.1% increase over the previous best) top-1 accuracy on UCF101 and 52.9% (+5.4% increase) on HMDB51 action classification, and 56.2% (+11.7% increase) Top-1 Recall on UCF101 nearest neighbor video retrieval.
Gabriella: An Online System for Real-Time Activity Detection in Untrimmed Security Videos
May 19, 2020

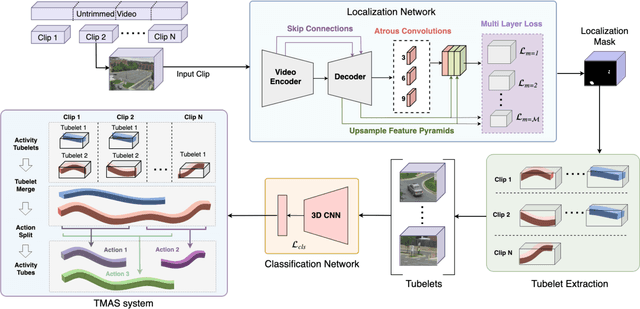
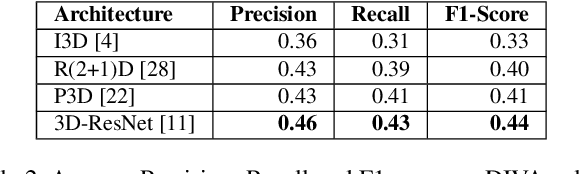
Activity detection in security videos is a difficult problem due to multiple factors such as large field of view, presence of multiple activities, varying scales and viewpoints, and its untrimmed nature. The existing research in activity detection is mainly focused on datasets, such as UCF-101, JHMDB, THUMOS, and AVA, which partially address these issues. The requirement of processing the security videos in real-time makes this even more challenging. In this work we propose Gabriella, a real-time online system to perform activity detection on untrimmed security videos. The proposed method consists of three stages: tubelet extraction, activity classification, and online tubelet merging. For tubelet extraction, we propose a localization network which takes a video clip as input and spatio-temporally detects potential foreground regions at multiple scales to generate action tubelets. We propose a novel Patch-Dice loss to handle large variations in actor size. Our online processing of videos at a clip level drastically reduces the computation time in detecting activities. The detected tubelets are assigned activity class scores by the classification network and merged together using our proposed Tubelet-Merge Action-Split (TMAS) algorithm to form the final action detections. The TMAS algorithm efficiently connects the tubelets in an online fashion to generate action detections which are robust against varying length activities. We perform our experiments on the VIRAT and MEVA (Multiview Extended Video with Activities) datasets and demonstrate the effectiveness of the proposed approach in terms of speed (~100 fps) and performance with state-of-the-art results. The code and models will be made publicly available.