 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePunching Bag vs. Punching Person: Motion Transferability in Videos
Jul 31, 2025Action recognition models demonstrate strong generalization, but can they effectively transfer high-level motion concepts across diverse contexts, even within similar distributions? For example, can a model recognize the broad action "punching" when presented with an unseen variation such as "punching person"? To explore this, we introduce a motion transferability framework with three datasets: (1) Syn-TA, a synthetic dataset with 3D object motions; (2) Kinetics400-TA; and (3) Something-Something-v2-TA, both adapted from natural video datasets. We evaluate 13 state-of-the-art models on these benchmarks and observe a significant drop in performance when recognizing high-level actions in novel contexts. Our analysis reveals: 1) Multimodal models struggle more with fine-grained unknown actions than with coarse ones; 2) The bias-free Syn-TA proves as challenging as real-world datasets, with models showing greater performance drops in controlled settings; 3) Larger models improve transferability when spatial cues dominate but struggle with intensive temporal reasoning, while reliance on object and background cues hinders generalization. We further explore how disentangling coarse and fine motions can improve recognition in temporally challenging datasets. We believe this study establishes a crucial benchmark for assessing motion transferability in action recognition. Datasets and relevant code: https://github.com/raiyaan-abdullah/Motion-Transfer.
PV-S3: Advancing Automatic Photovoltaic Defect Detection using Semi-Supervised Semantic Segmentation of Electroluminescence Images
Apr 21, 2024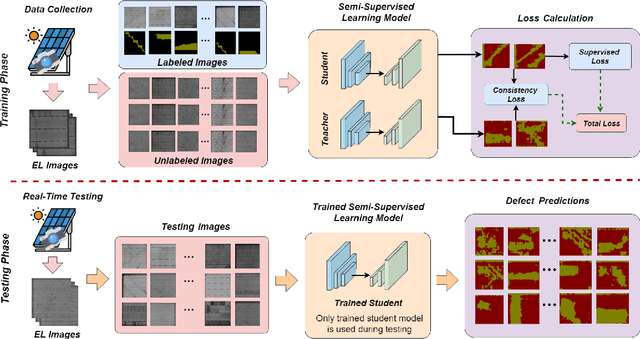
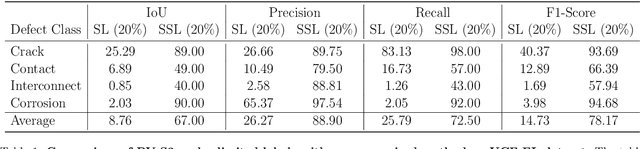
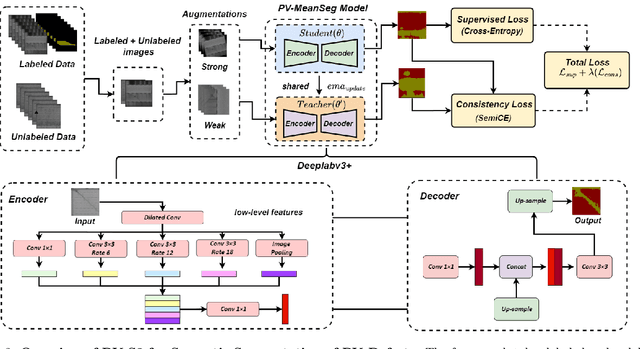
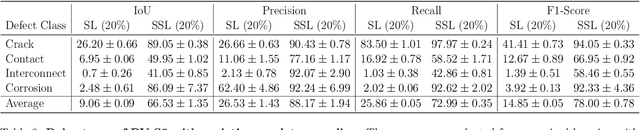
Photovoltaic (PV) systems allow us to tap into all abundant solar energy, however they require regular maintenance for high efficiency and to prevent degradation. Traditional manual health check, using Electroluminescence (EL) imaging, is expensive and logistically challenging making automated defect detection essential. Current automation approaches require extensive manual expert labeling, which is time-consuming, expensive, and prone to errors. We propose PV-S3 (Photovoltaic-Semi Supervised Segmentation), a Semi-Supervised Learning approach for semantic segmentation of defects in EL images that reduces reliance on extensive labeling. PV-S3 is a Deep learning model trained using a few labeled images along with numerous unlabeled images. We introduce a novel Semi Cross-Entropy loss function to train PV-S3 which addresses the challenges specific to automated PV defect detection, such as diverse defect types and class imbalance. We evaluate PV-S3 on multiple datasets and demonstrate its effectiveness and adaptability. With merely 20% labeled samples, we achieve an absolute improvement of 9.7% in IoU, 29.9% in Precision, 12.75% in Recall, and 20.42% in F1-Score over prior state-of-the-art supervised method (which uses 100% labeled samples) on UCF-EL dataset (largest dataset available for semantic segmentation of EL images) showing improvement in performance while reducing the annotation costs by 80%.
Large-scale Robustness Analysis of Video Action Recognition Models
Jul 04, 2022



We have seen a great progress in video action recognition in recent years. There are several models based on convolutional neural network (CNN) with some recent transformer based approaches which provide state-of-the-art performance on existing benchmark datasets. However, large-scale robustness has not been studied for these models which is a critical aspect for real-world applications. In this work we perform a large-scale robustness analysis of these existing models for video action recognition. We mainly focus on robustness against distribution shifts due to real-world perturbations instead of adversarial perturbations. We propose four different benchmark datasets, HMDB-51P, UCF-101P, Kinetics-400P, and SSv2P and study the robustness of six different state-of-the-art action recognition models against 90 different perturbations. The study reveals some interesting findings, 1) transformer based models are consistently more robust against most of the perturbations when compared with CNN based models, 2) Pretraining helps Transformer based models to be more robust to different perturbations than CNN based models, and 3) All of the studied models are robust to temporal perturbation on the Kinetics dataset, but not on SSv2; this suggests temporal information is much more important for action label prediction on SSv2 datasets than on the Kinetics dataset. We hope that this study will serve as a benchmark for future research in robust video action recognition. More details about the project are available at https://rose-ar.github.io/.
"Knights": First Place Submission for VIPriors21 Action Recognition Challenge at ICCV 2021
Oct 14, 2021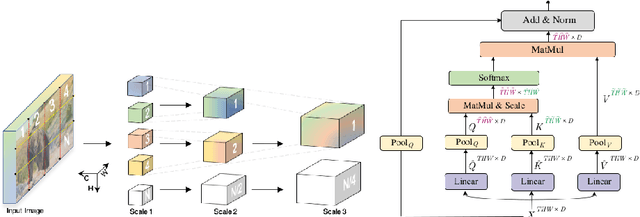
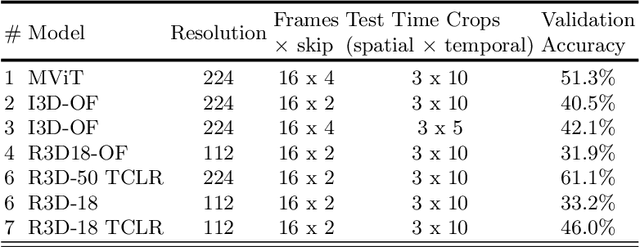
This technical report presents our approach "Knights" to solve the action recognition task on a small subset of Kinetics-400 i.e. Kinetics400ViPriors without using any extra-data. Our approach has 3 main components: state-of-the-art Temporal Contrastive self-supervised pretraining, video transformer models, and optical flow modality. Along with the use of standard test-time augmentation, our proposed solution achieves 73% on Kinetics400ViPriors test set, which is the best among all of the other entries Visual Inductive Priors for Data-Efficient Computer Vision's Action Recognition Challenge, ICCV 2021.
NoisyActions2M: A Multimedia Dataset for Video Understanding from Noisy Labels
Oct 13, 2021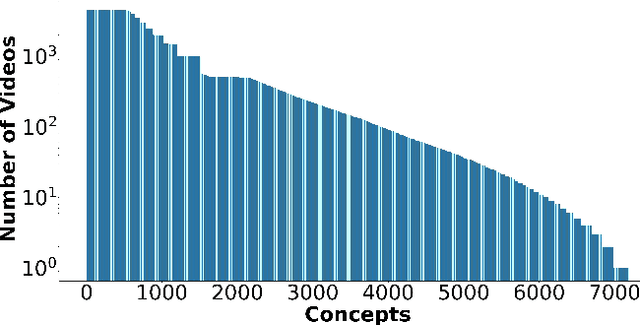
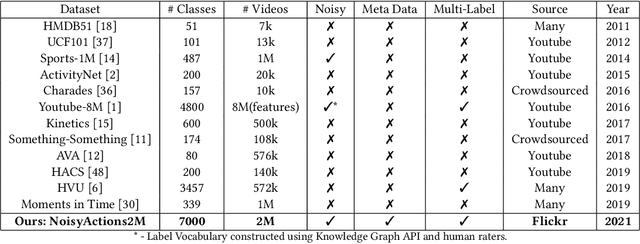
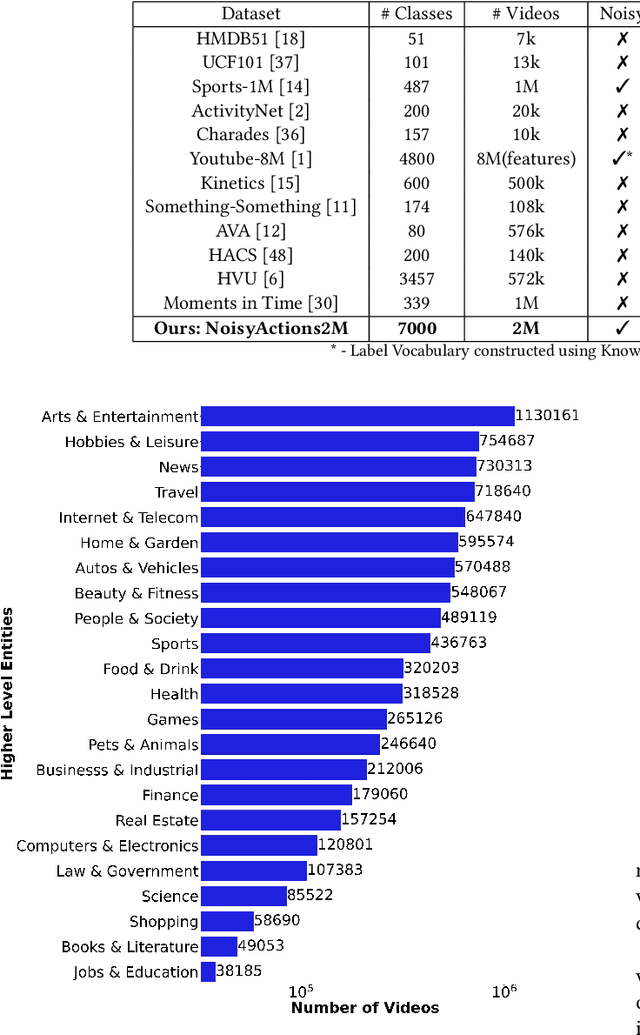
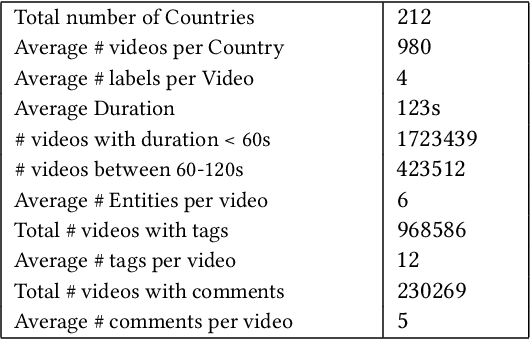
Deep learning has shown remarkable progress in a wide range of problems. However, efficient training of such models requires large-scale datasets, and getting annotations for such datasets can be challenging and costly. In this work, we explore the use of user-generated freely available labels from web videos for video understanding. We create a benchmark dataset consisting of around 2 million videos with associated user-generated annotations and other meta information. We utilize the collected dataset for action classification and demonstrate its usefulness with existing small-scale annotated datasets, UCF101 and HMDB51. We study different loss functions and two pretraining strategies, simple and self-supervised learning. We also show how a network pretrained on the proposed dataset can help against video corruption and label noise in downstream datasets. We present this as a benchmark dataset in noisy learning for video understanding. The dataset, code, and trained models will be publicly available for future research.
Modeling Multi-Label Action Dependencies for Temporal Action Localization
Mar 05, 2021

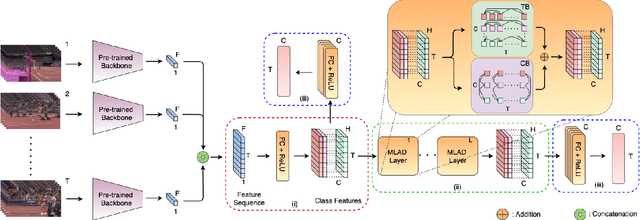
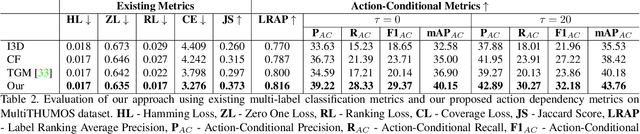
Real-world videos contain many complex actions with inherent relationships between action classes. In this work, we propose an attention-based architecture that models these action relationships for the task of temporal action localization in untrimmed videos. As opposed to previous works that leverage video-level co-occurrence of actions, we distinguish the relationships between actions that occur at the same time-step and actions that occur at different time-steps (i.e. those which precede or follow each other). We define these distinct relationships as action dependencies. We propose to improve action localization performance by modeling these action dependencies in a novel attention-based Multi-Label Action Dependency (MLAD)layer. The MLAD layer consists of two branches: a Co-occurrence Dependency Branch and a Temporal Dependency Branch to model co-occurrence action dependencies and temporal action dependencies, respectively. We observe that existing metrics used for multi-label classification do not explicitly measure how well action dependencies are modeled, therefore, we propose novel metrics that consider both co-occurrence and temporal dependencies between action classes. Through empirical evaluation and extensive analysis, we show improved performance over state-of-the-art methods on multi-label action localization benchmarks(MultiTHUMOS and Charades) in terms of f-mAP and our proposed metric.
Adversarial Learning for Personalized Tag Recommendation
Apr 01, 2020

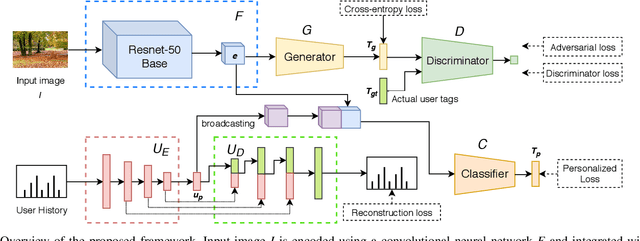

We have recently seen great progress in image classification due to the success of deep convolutional neural networks and the availability of large-scale datasets. Most of the existing work focuses on single-label image classification. However, there are usually multiple tags associated with an image. The existing works on multi-label classification are mainly based on lab curated labels. Humans assign tags to their images differently, which is mainly based on their interests and personal tagging behavior. In this paper, we address the problem of personalized tag recommendation and propose an end-to-end deep network which can be trained on large-scale datasets. The user-preference is learned within the network in an unsupervised way where the network performs joint optimization for user-preference and visual encoding. A joint training of user-preference and visual encoding allows the network to efficiently integrate the visual preference with tagging behavior for a better user recommendation. In addition, we propose the use of adversarial learning, which enforces the network to predict tags resembling user-generated tags. We demonstrate the effectiveness of the proposed model on two different large-scale and publicly available datasets, YFCC100M and NUS-WIDE. The proposed method achieves significantly better performance on both the datasets when compared to the baselines and other state-of-the-art methods. The code is publicly available at https://github.com/vyzuer/ALTReco.