 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVGraph: Learning Semantic Graphs from Instructional Videos
Jul 16, 2022
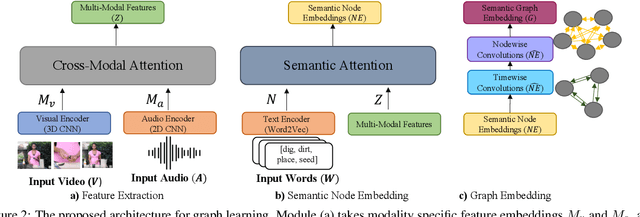
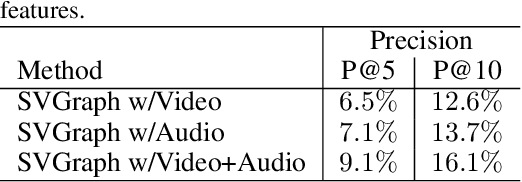
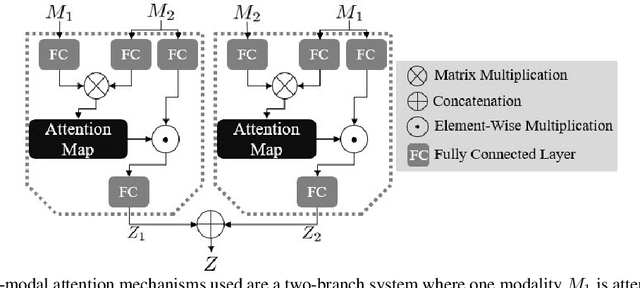
In this work, we focus on generating graphical representations of noisy, instructional videos for video understanding. We propose a self-supervised, interpretable approach that does not require any annotations for graphical representations, which would be expensive and time consuming to collect. We attempt to overcome "black box" learning limitations by presenting Semantic Video Graph or SVGraph, a multi-modal approach that utilizes narrations for semantic interpretability of the learned graphs. SVGraph 1) relies on the agreement between multiple modalities to learn a unified graphical structure with the help of cross-modal attention and 2) assigns semantic interpretation with the help of Semantic-Assignment, which captures the semantics from video narration. We perform experiments on multiple datasets and demonstrate the interpretability of SVGraph in semantic graph learning.
Multi-modal Robustness Analysis Against Language and Visual Perturbations
Jul 06, 2022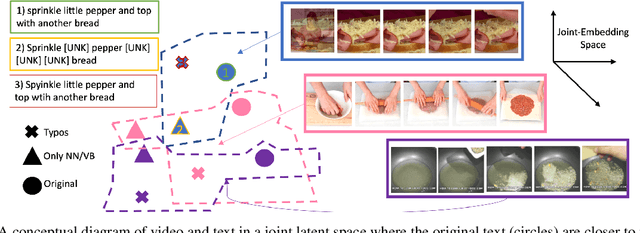

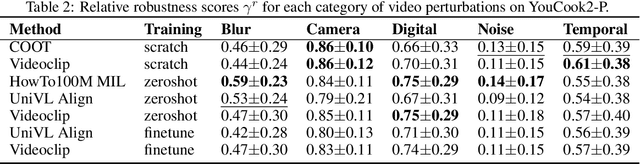
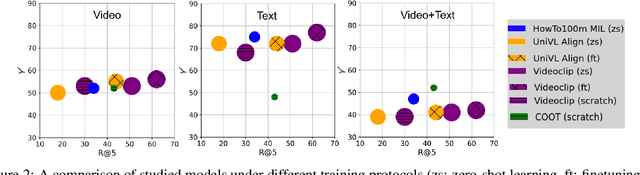
Joint visual and language modeling on large-scale datasets has recently shown a good progress in multi-modal tasks when compared to single modal learning. However, robustness of these approaches against real-world perturbations has not been studied. In this work, we perform the first extensive robustness study of such models against various real-world perturbations focusing on video and language. We focus on text-to-video retrieval and propose two large-scale benchmark datasets, MSRVTT-P and YouCook2-P, which utilize 90 different visual and 35 different textual perturbations. The study reveals some interesting findings: 1) The studied models are more robust when text is perturbed versus when video is perturbed 2) The transformer text encoder is more robust on non-semantic changing text perturbations and visual perturbations compared to word embedding approaches. 3) Using two-branch encoders in isolation is typically more robust than when architectures use cross-attention. We hope this study will serve as a benchmark and guide future research in robust multimodal learning.
Large-scale Robustness Analysis of Video Action Recognition Models
Jul 04, 2022



We have seen a great progress in video action recognition in recent years. There are several models based on convolutional neural network (CNN) with some recent transformer based approaches which provide state-of-the-art performance on existing benchmark datasets. However, large-scale robustness has not been studied for these models which is a critical aspect for real-world applications. In this work we perform a large-scale robustness analysis of these existing models for video action recognition. We mainly focus on robustness against distribution shifts due to real-world perturbations instead of adversarial perturbations. We propose four different benchmark datasets, HMDB-51P, UCF-101P, Kinetics-400P, and SSv2P and study the robustness of six different state-of-the-art action recognition models against 90 different perturbations. The study reveals some interesting findings, 1) transformer based models are consistently more robust against most of the perturbations when compared with CNN based models, 2) Pretraining helps Transformer based models to be more robust to different perturbations than CNN based models, and 3) All of the studied models are robust to temporal perturbation on the Kinetics dataset, but not on SSv2; this suggests temporal information is much more important for action label prediction on SSv2 datasets than on the Kinetics dataset. We hope that this study will serve as a benchmark for future research in robust video action recognition. More details about the project are available at https://rose-ar.github.io/.