 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVGraph: Learning Semantic Graphs from Instructional Videos
Paper and Code

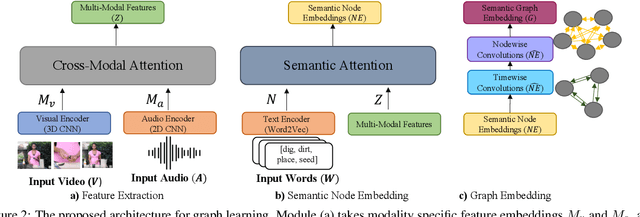
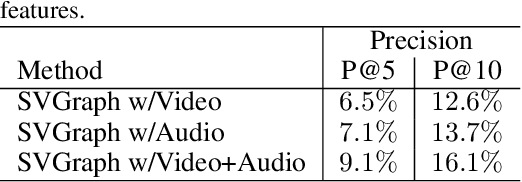
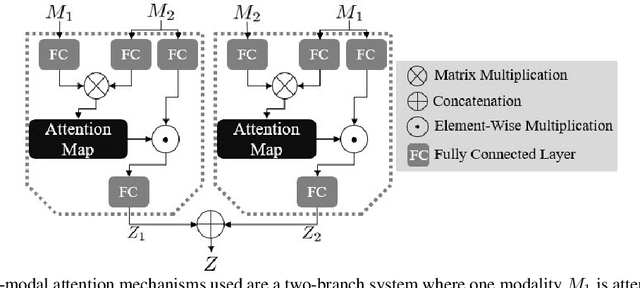
In this work, we focus on generating graphical representations of noisy, instructional videos for video understanding. We propose a self-supervised, interpretable approach that does not require any annotations for graphical representations, which would be expensive and time consuming to collect. We attempt to overcome "black box" learning limitations by presenting Semantic Video Graph or SVGraph, a multi-modal approach that utilizes narrations for semantic interpretability of the learned graphs. SVGraph 1) relies on the agreement between multiple modalities to learn a unified graphical structure with the help of cross-modal attention and 2) assigns semantic interpretation with the help of Semantic-Assignment, which captures the semantics from video narration. We perform experiments on multiple datasets and demonstrate the interpretability of SVGraph in semantic graph learning.