 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProDiG: Progressive Diffusion-Guided Gaussian Splatting for Aerial to Ground Reconstruction
Apr 02, 2026Generating ground-level views and coherent 3D site models from aerial-only imagery is challenging due to extreme viewpoint changes, missing intermediate observations, and large scale variations. Existing methods either refine renderings post-hoc, often producing geometrically inconsistent results, or rely on multi-altitude ground-truth, which is rarely available. Gaussian Splatting and diffusion-based refinements improve fidelity under small variations but fail under wide aerial-to-ground gaps. To address these limitations, we introduce ProDiG (Progressive Altitude Gaussian Splatting), a diffusion-guided framework that progressively transforms aerial 3D representations toward ground-level fidelity. ProDiG synthesizes intermediate-altitude views and refines the Gaussian representation at each stage using a geometry-aware causal attention module that injects epipolar structure into reference-view diffusion. A distance-adaptive Gaussian module dynamically adjusts Gaussian scale and opacity based on camera distance, ensuring stable reconstruction across large viewpoint gaps. Together, these components enable progressive, geometrically grounded refinement without requiring additional ground-truth viewpoints. Extensive experiments on synthetic and real-world datasets demonstrate that ProDiG produces visually realistic ground-level renderings and coherent 3D geometry, significantly outperforming existing approaches in terms of visual quality, geometric consistency, and robustness to extreme viewpoint changes.
VLA-Thinker: Boosting Vision-Language-Action Models through Thinking-with-Image Reasoning
Mar 15, 2026Vision-Language-Action (VLA) models have shown promising capabilities for embodied intelligence, but most existing approaches rely on text-based chain-of-thought reasoning where visual inputs are treated as static context. This limits the ability of the model to actively revisit the environment and resolve ambiguities during long-horizon tasks. We propose VLA-Thinker, a thinking-with-image reasoning framework that models perception as a dynamically invocable reasoning action. To train such a system, we introduce a two-stage training pipeline consisting of (1) an SFT cold-start phase with curated visual Chain-of-Thought data to activate structured reasoning and tool-use behaviors, and (2) GRPO-based reinforcement learning to align complete reasoning-action trajectories with task-level success. Extensive experiments on LIBERO and RoboTwin 2.0 benchmarks demonstrate that VLA-Thinker significantly improves manipulation performance, achieving 97.5% success rate on LIBERO and strong gains across long-horizon robotic tasks. Project and Codes: https://cywang735.github.io/VLA-Thinker/ .
Colors See Colors Ignore: Clothes Changing ReID with Color Disentanglement
Jul 09, 2025Clothes-Changing Re-Identification (CC-ReID) aims to recognize individuals across different locations and times, irrespective of clothing. Existing methods often rely on additional models or annotations to learn robust, clothing-invariant features, making them resource-intensive. In contrast, we explore the use of color - specifically foreground and background colors - as a lightweight, annotation-free proxy for mitigating appearance bias in ReID models. We propose Colors See, Colors Ignore (CSCI), an RGB-only method that leverages color information directly from raw images or video frames. CSCI efficiently captures color-related appearance bias ('Color See') while disentangling it from identity-relevant ReID features ('Color Ignore'). To achieve this, we introduce S2A self-attention, a novel self-attention to prevent information leak between color and identity cues within the feature space. Our analysis shows a strong correspondence between learned color embeddings and clothing attributes, validating color as an effective proxy when explicit clothing labels are unavailable. We demonstrate the effectiveness of CSCI on both image and video ReID with extensive experiments on four CC-ReID datasets. We improve the baseline by Top-1 2.9% on LTCC and 5.0% on PRCC for image-based ReID, and 1.0% on CCVID and 2.5% on MeVID for video-based ReID without relying on additional supervision. Our results highlight the potential of color as a cost-effective solution for addressing appearance bias in CC-ReID. Github: https://github.com/ppriyank/ICCV-CSCI-Person-ReID.
Foundation Models for Video Understanding: A Survey
May 06, 2024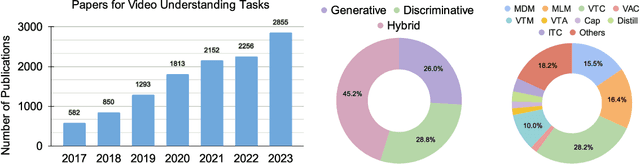
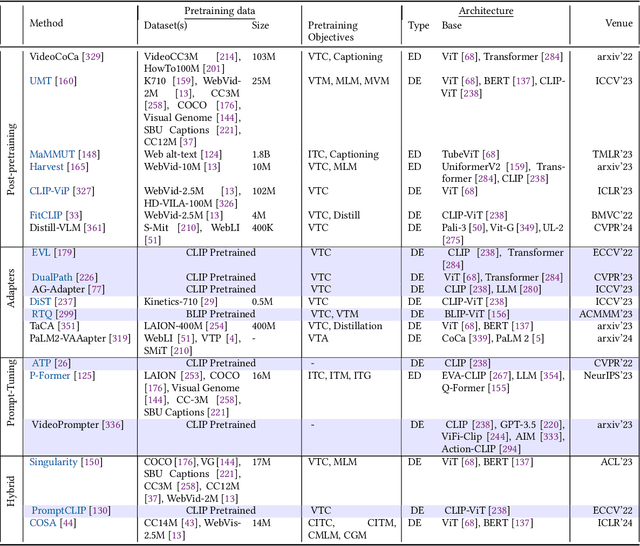
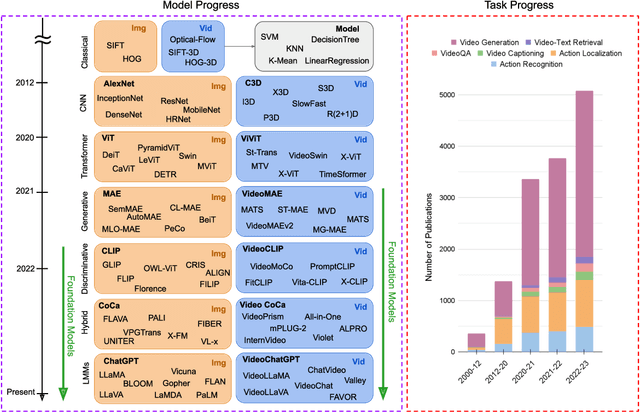
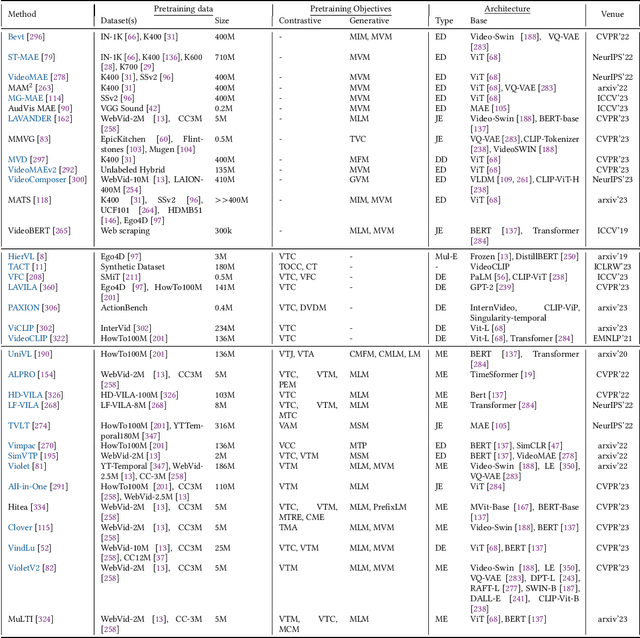
Video Foundation Models (ViFMs) aim to learn a general-purpose representation for various video understanding tasks. Leveraging large-scale datasets and powerful models, ViFMs achieve this by capturing robust and generic features from video data. This survey analyzes over 200 video foundational models, offering a comprehensive overview of benchmarks and evaluation metrics across 14 distinct video tasks categorized into 3 main categories. Additionally, we offer an in-depth performance analysis of these models for the 6 most common video tasks. We categorize ViFMs into three categories: 1) Image-based ViFMs, which adapt existing image models for video tasks, 2) Video-Based ViFMs, which utilize video-specific encoding methods, and 3) Universal Foundational Models (UFMs), which combine multiple modalities (image, video, audio, and text etc.) within a single framework. By comparing the performance of various ViFMs on different tasks, this survey offers valuable insights into their strengths and weaknesses, guiding future advancements in video understanding. Our analysis surprisingly reveals that image-based foundation models consistently outperform video-based models on most video understanding tasks. Additionally, UFMs, which leverage diverse modalities, demonstrate superior performance on video tasks. We share the comprehensive list of ViFMs studied in this work at: \url{https://github.com/NeeluMadan/ViFM_Survey.git}
Robustness Analysis on Foundational Segmentation Models
Jun 15, 2023



Due to the increase in computational resources and accessibility of data, an increase in large, deep learning models trained on copious amounts of data using self-supervised or semi-supervised learning have emerged. These "foundation" models are often adapted to a variety of downstream tasks like classification, object detection, and segmentation with little-to-no training on the target dataset. In this work, we perform a robustness analysis of Visual Foundation Models (VFMs) for segmentation tasks and compare them to supervised models of smaller scale. We focus on robustness against real-world distribution shift perturbations.We benchmark four state-of-the-art segmentation architectures using 2 different datasets, COCO and ADE20K, with 17 different perturbations with 5 severity levels each. We find interesting insights that include (1) VFMs are not robust to compression-based corruptions, (2) while the selected VFMs do not significantly outperform or exhibit more robustness compared to non-VFM models, they remain competitively robust in zero-shot evaluations, particularly when non-VFM are under supervision and (3) selected VFMs demonstrate greater resilience to specific categories of objects, likely due to their open-vocabulary training paradigm, a feature that non-VFM models typically lack. We posit that the suggested robustness evaluation introduces new requirements for foundational models, thus sparking further research to enhance their performance.
SVGraph: Learning Semantic Graphs from Instructional Videos
Jul 16, 2022
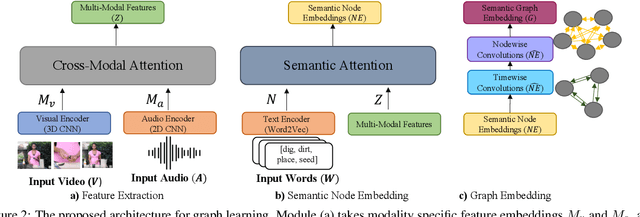
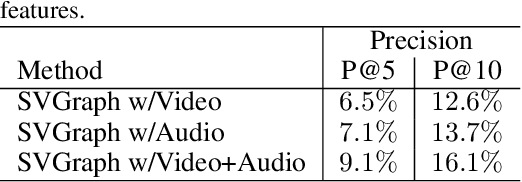
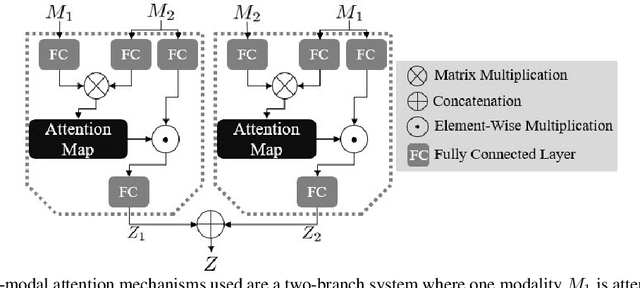
In this work, we focus on generating graphical representations of noisy, instructional videos for video understanding. We propose a self-supervised, interpretable approach that does not require any annotations for graphical representations, which would be expensive and time consuming to collect. We attempt to overcome "black box" learning limitations by presenting Semantic Video Graph or SVGraph, a multi-modal approach that utilizes narrations for semantic interpretability of the learned graphs. SVGraph 1) relies on the agreement between multiple modalities to learn a unified graphical structure with the help of cross-modal attention and 2) assigns semantic interpretation with the help of Semantic-Assignment, which captures the semantics from video narration. We perform experiments on multiple datasets and demonstrate the interpretability of SVGraph in semantic graph learning.
Multi-modal Robustness Analysis Against Language and Visual Perturbations
Jul 06, 2022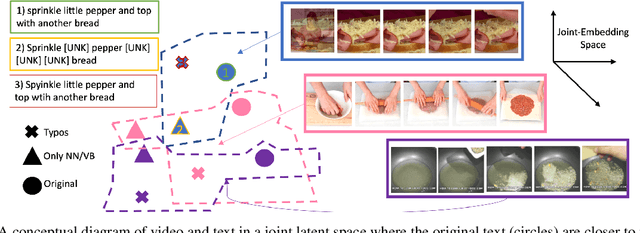

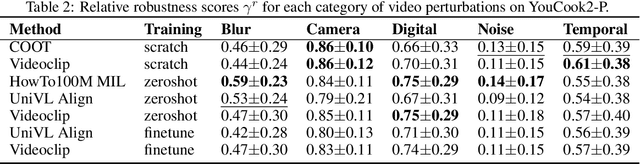
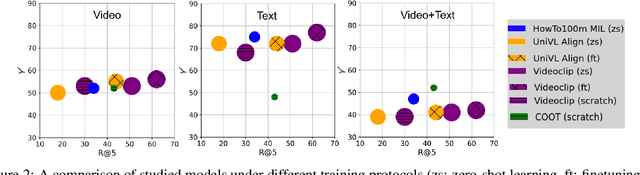
Joint visual and language modeling on large-scale datasets has recently shown a good progress in multi-modal tasks when compared to single modal learning. However, robustness of these approaches against real-world perturbations has not been studied. In this work, we perform the first extensive robustness study of such models against various real-world perturbations focusing on video and language. We focus on text-to-video retrieval and propose two large-scale benchmark datasets, MSRVTT-P and YouCook2-P, which utilize 90 different visual and 35 different textual perturbations. The study reveals some interesting findings: 1) The studied models are more robust when text is perturbed versus when video is perturbed 2) The transformer text encoder is more robust on non-semantic changing text perturbations and visual perturbations compared to word embedding approaches. 3) Using two-branch encoders in isolation is typically more robust than when architectures use cross-attention. We hope this study will serve as a benchmark and guide future research in robust multimodal learning.
Novel View Video Prediction Using a Dual Representation
Jun 07, 2021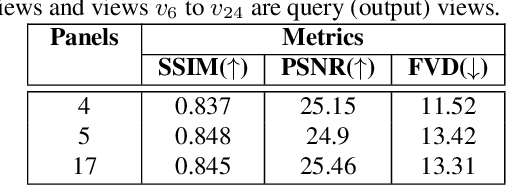
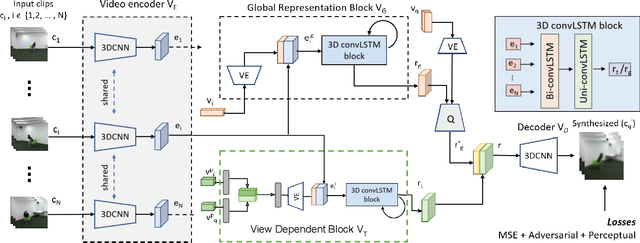
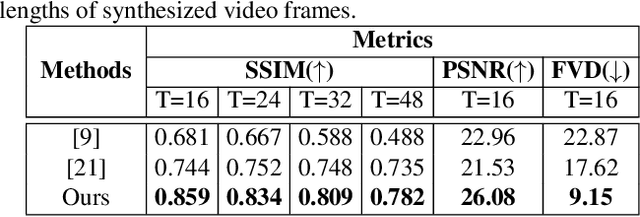

We address the problem of novel view video prediction; given a set of input video clips from a single/multiple views, our network is able to predict the video from a novel view. The proposed approach does not require any priors and is able to predict the video from wider angular distances, upto 45 degree, as compared to the recent studies predicting small variations in viewpoint. Moreover, our method relies only onRGB frames to learn a dual representation which is used to generate the video from a novel viewpoint. The dual representation encompasses a view-dependent and a global representation which incorporates complementary details to enable novel view video prediction. We demonstrate the effectiveness of our framework on two real world datasets: NTU-RGB+D and CMU Panoptic. A comparison with the State-of-the-art novel view video prediction methods shows an improvement of 26.1% in SSIM, 13.6% in PSNR, and 60% inFVD scores without using explicit priors from target views.
PLM: Partial Label Masking for Imbalanced Multi-label Classification
May 22, 2021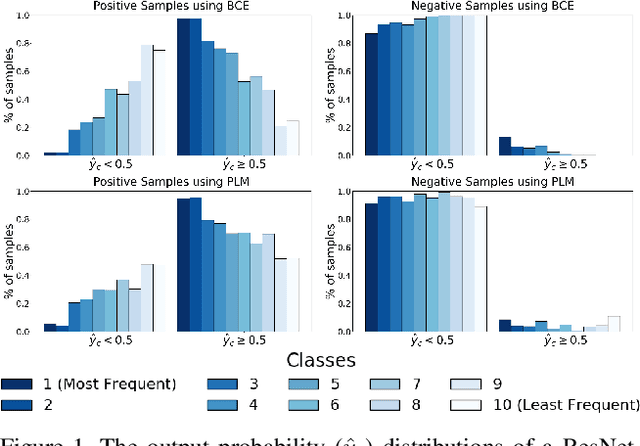
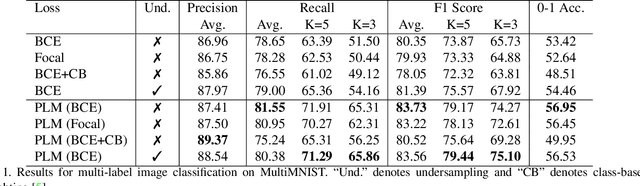
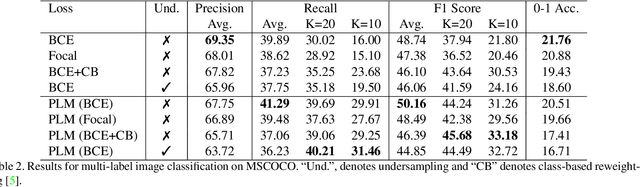
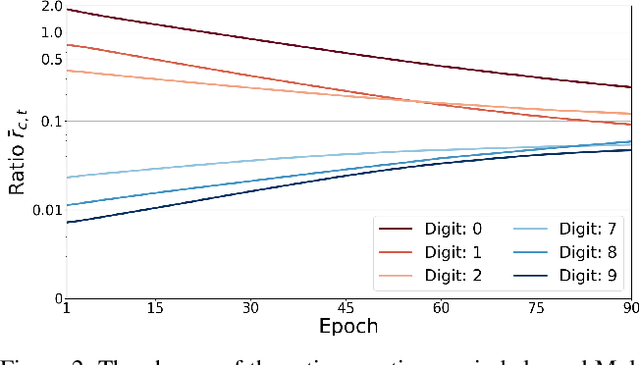
Neural networks trained on real-world datasets with long-tailed label distributions are biased towards frequent classes and perform poorly on infrequent classes. The imbalance in the ratio of positive and negative samples for each class skews network output probabilities further from ground-truth distributions. We propose a method, Partial Label Masking (PLM), which utilizes this ratio during training. By stochastically masking labels during loss computation, the method balances this ratio for each class, leading to improved recall on minority classes and improved precision on frequent classes. The ratio is estimated adaptively based on the network's performance by minimizing the KL divergence between predicted and ground-truth distributions. Whereas most existing approaches addressing data imbalance are mainly focused on single-label classification and do not generalize well to the multi-label case, this work proposes a general approach to solve the long-tail data imbalance issue for multi-label classification. PLM is versatile: it can be applied to most objective functions and it can be used alongside other strategies for class imbalance. Our method achieves strong performance when compared to existing methods on both multi-label (MultiMNIST and MSCOCO) and single-label (imbalanced CIFAR-10 and CIFAR-100) image classification datasets.