 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoPE-VideoLM: Codec Primitives For Efficient Video Language Models
Feb 13, 2026Video Language Models (VideoLMs) empower AI systems to understand temporal dynamics in videos. To fit to the maximum context window constraint, current methods use keyframe sampling which can miss both macro-level events and micro-level details due to the sparse temporal coverage. Furthermore, processing full images and their tokens for each frame incurs substantial computational overhead. To address these limitations, we propose to leverage video codec primitives (specifically motion vectors and residuals) which natively encode video redundancy and sparsity without requiring expensive full-image encoding for most frames. To this end, we introduce lightweight transformer-based encoders that aggregate codec primitives and align their representations with image encoder embeddings through a pre-training strategy that accelerates convergence during end-to-end fine-tuning. Our approach reduces the time-to-first-token by up to $86\%$ and token usage by up to $93\%$ compared to standard VideoLMs. Moreover, by varying the keyframe and codec primitive densities we are able to maintain or exceed performance on $14$ diverse video understanding benchmarks spanning general question answering, temporal reasoning, long-form understanding, and spatial scene understanding.
CrossOver: 3D Scene Cross-Modal Alignment
Feb 20, 2025


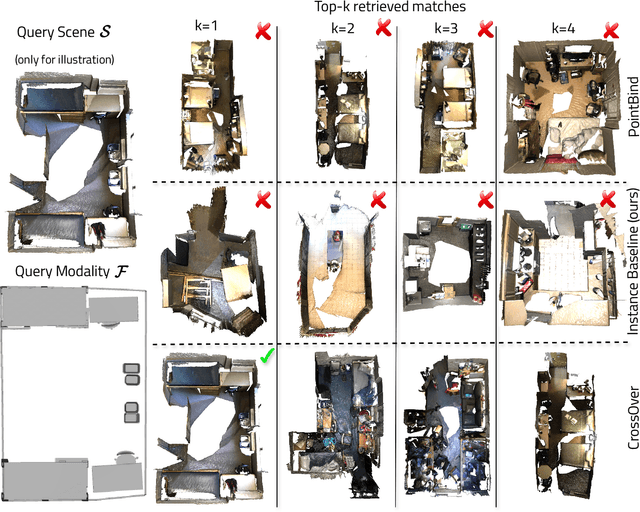
Multi-modal 3D object understanding has gained significant attention, yet current approaches often assume complete data availability and rigid alignment across all modalities. We present CrossOver, a novel framework for cross-modal 3D scene understanding via flexible, scene-level modality alignment. Unlike traditional methods that require aligned modality data for every object instance, CrossOver learns a unified, modality-agnostic embedding space for scenes by aligning modalities - RGB images, point clouds, CAD models, floorplans, and text descriptions - with relaxed constraints and without explicit object semantics. Leveraging dimensionality-specific encoders, a multi-stage training pipeline, and emergent cross-modal behaviors, CrossOver supports robust scene retrieval and object localization, even with missing modalities. Evaluations on ScanNet and 3RScan datasets show its superior performance across diverse metrics, highlighting adaptability for real-world applications in 3D scene understanding.
Robustness Analysis on Foundational Segmentation Models
Jun 15, 2023



Due to the increase in computational resources and accessibility of data, an increase in large, deep learning models trained on copious amounts of data using self-supervised or semi-supervised learning have emerged. These "foundation" models are often adapted to a variety of downstream tasks like classification, object detection, and segmentation with little-to-no training on the target dataset. In this work, we perform a robustness analysis of Visual Foundation Models (VFMs) for segmentation tasks and compare them to supervised models of smaller scale. We focus on robustness against real-world distribution shift perturbations.We benchmark four state-of-the-art segmentation architectures using 2 different datasets, COCO and ADE20K, with 17 different perturbations with 5 severity levels each. We find interesting insights that include (1) VFMs are not robust to compression-based corruptions, (2) while the selected VFMs do not significantly outperform or exhibit more robustness compared to non-VFM models, they remain competitively robust in zero-shot evaluations, particularly when non-VFM are under supervision and (3) selected VFMs demonstrate greater resilience to specific categories of objects, likely due to their open-vocabulary training paradigm, a feature that non-VFM models typically lack. We posit that the suggested robustness evaluation introduces new requirements for foundational models, thus sparking further research to enhance their performance.
SGAligner : 3D Scene Alignment with Scene Graphs
Apr 28, 2023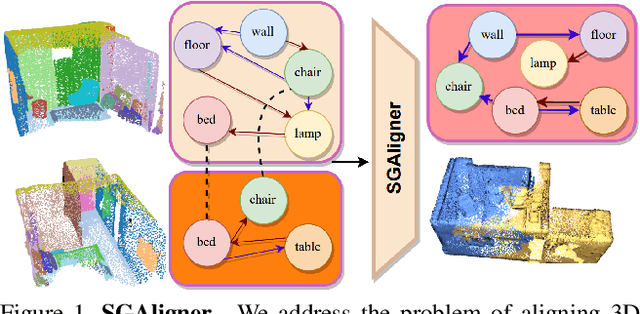
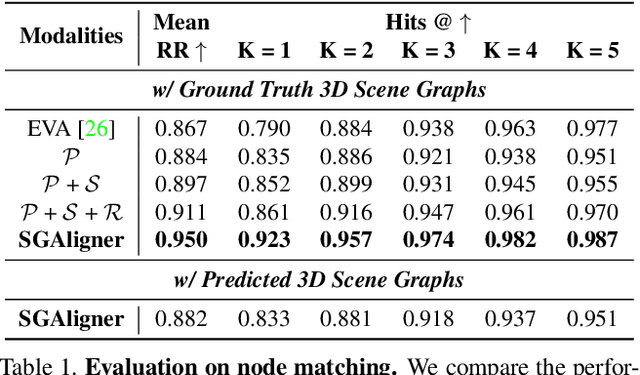
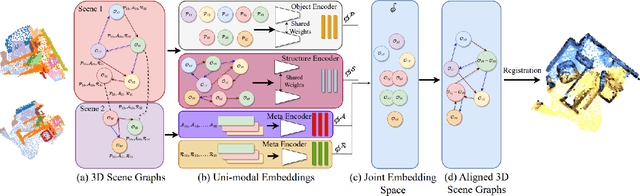
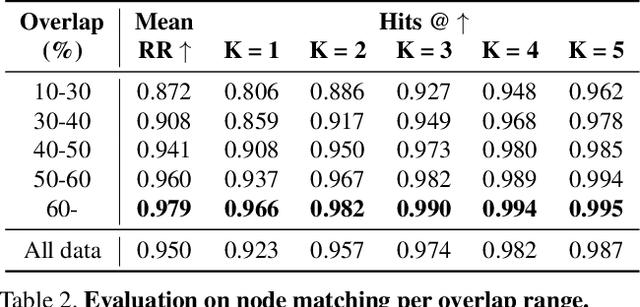
Building 3D scene graphs has recently emerged as a topic in scene representation for several embodied AI applications to represent the world in a structured and rich manner. With their increased use in solving downstream tasks (eg, navigation and room rearrangement), can we leverage and recycle them for creating 3D maps of environments, a pivotal step in agent operation? We focus on the fundamental problem of aligning pairs of 3D scene graphs whose overlap can range from zero to partial and can contain arbitrary changes. We propose SGAligner, the first method for aligning pairs of 3D scene graphs that is robust to in-the-wild scenarios (ie, unknown overlap -- if any -- and changes in the environment). We get inspired by multi-modality knowledge graphs and use contrastive learning to learn a joint, multi-modal embedding space. We evaluate on the 3RScan dataset and further showcase that our method can be used for estimating the transformation between pairs of 3D scenes. Since benchmarks for these tasks are missing, we create them on this dataset. The code, benchmark, and trained models are available on the project website.
LaMAR: Benchmarking Localization and Mapping for Augmented Reality
Oct 19, 2022


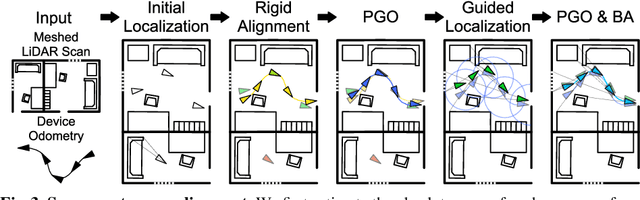
Localization and mapping is the foundational technology for augmented reality (AR) that enables sharing and persistence of digital content in the real world. While significant progress has been made, researchers are still mostly driven by unrealistic benchmarks not representative of real-world AR scenarios. These benchmarks are often based on small-scale datasets with low scene diversity, captured from stationary cameras, and lack other sensor inputs like inertial, radio, or depth data. Furthermore, their ground-truth (GT) accuracy is mostly insufficient to satisfy AR requirements. To close this gap, we introduce LaMAR, a new benchmark with a comprehensive capture and GT pipeline that co-registers realistic trajectories and sensor streams captured by heterogeneous AR devices in large, unconstrained scenes. To establish an accurate GT, our pipeline robustly aligns the trajectories against laser scans in a fully automated manner. As a result, we publish a benchmark dataset of diverse and large-scale scenes recorded with head-mounted and hand-held AR devices. We extend several state-of-the-art methods to take advantage of the AR-specific setup and evaluate them on our benchmark. The results offer new insights on current research and reveal promising avenues for future work in the field of localization and mapping for AR.
Learning to Simulate Realistic LiDARs
Sep 22, 2022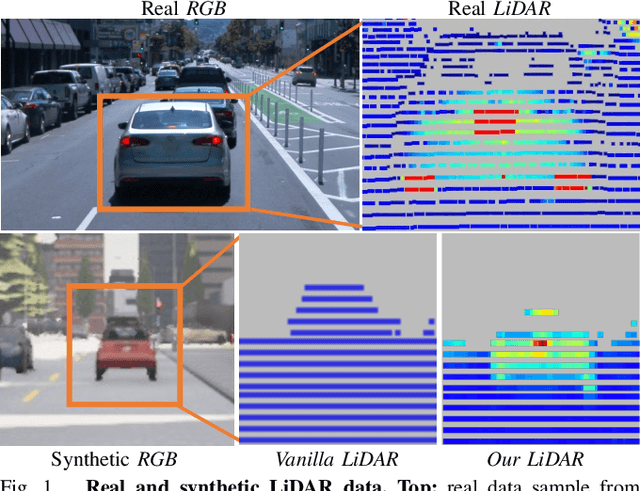
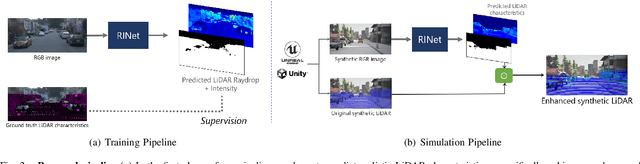


Simulating realistic sensors is a challenging part in data generation for autonomous systems, often involving carefully handcrafted sensor design, scene properties, and physics modeling. To alleviate this, we introduce a pipeline for data-driven simulation of a realistic LiDAR sensor. We propose a model that learns a mapping between RGB images and corresponding LiDAR features such as raydrop or per-point intensities directly from real datasets. We show that our model can learn to encode realistic effects such as dropped points on transparent surfaces or high intensity returns on reflective materials. When applied to naively raycasted point clouds provided by off-the-shelf simulator software, our model enhances the data by predicting intensities and removing points based on the scene's appearance to match a real LiDAR sensor. We use our technique to learn models of two distinct LiDAR sensors and use them to improve simulated LiDAR data accordingly. Through a sample task of vehicle segmentation, we show that enhancing simulated point clouds with our technique improves downstream task performance.
TASKOGRAPHY: Evaluating robot task planning over large 3D scene graphs
Jul 11, 2022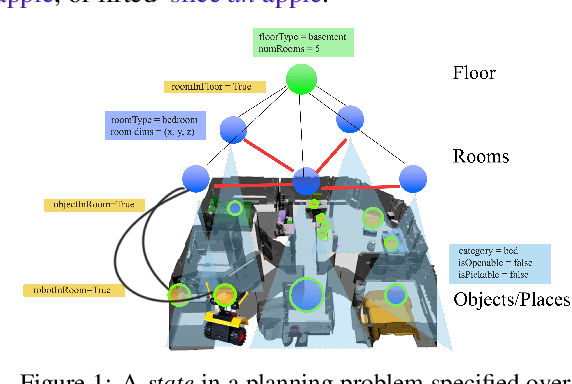
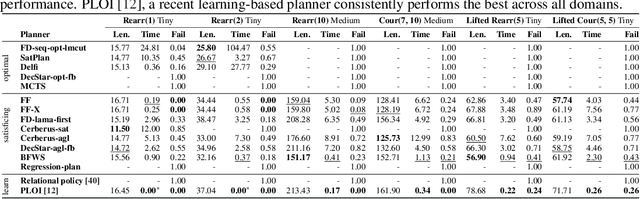
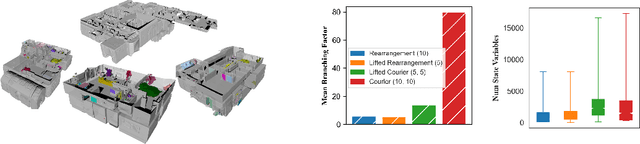
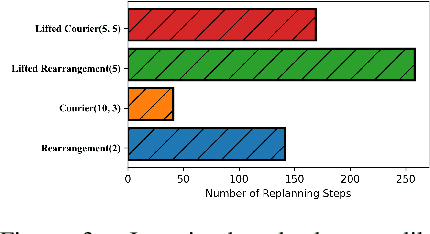
3D scene graphs (3DSGs) are an emerging description; unifying symbolic, topological, and metric scene representations. However, typical 3DSGs contain hundreds of objects and symbols even for small environments; rendering task planning on the full graph impractical. We construct TASKOGRAPHY, the first large-scale robotic task planning benchmark over 3DSGs. While most benchmarking efforts in this area focus on vision-based planning, we systematically study symbolic planning, to decouple planning performance from visual representation learning. We observe that, among existing methods, neither classical nor learning-based planners are capable of real-time planning over full 3DSGs. Enabling real-time planning demands progress on both (a) sparsifying 3DSGs for tractable planning and (b) designing planners that better exploit 3DSG hierarchies. Towards the former goal, we propose SCRUB, a task-conditioned 3DSG sparsification method; enabling classical planners to match and in some cases surpass state-of-the-art learning-based planners. Towards the latter goal, we propose SEEK, a procedure enabling learning-based planners to exploit 3DSG structure, reducing the number of replanning queries required by current best approaches by an order of magnitude. We will open-source all code and baselines to spur further research along the intersections of robot task planning, learning and 3DSGs.
* Video: https://www.youtube.com/watch?v=mM4v5hP4LdA&ab_channel=KrishnaMurthy . Project page: https://taskography.github.io/ . 18 pages, 7 figures. In proceedings of Conference on Robot Learning (CoRL) 2021. The first two authors contributed equally
Cross-Descriptor Visual Localization and Mapping
Dec 02, 2020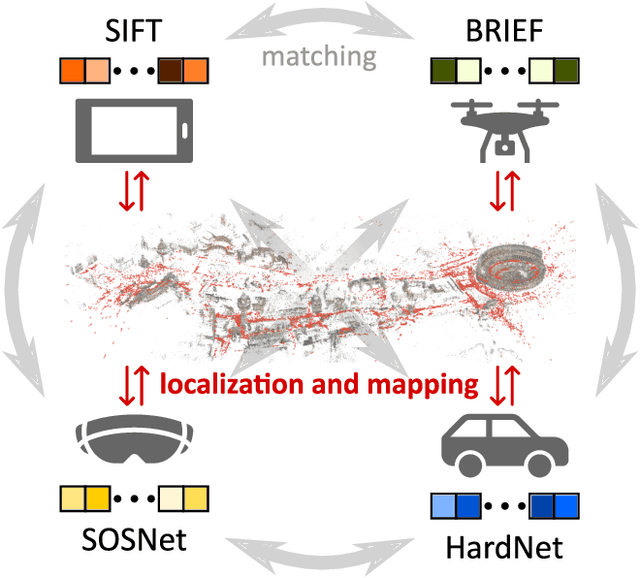
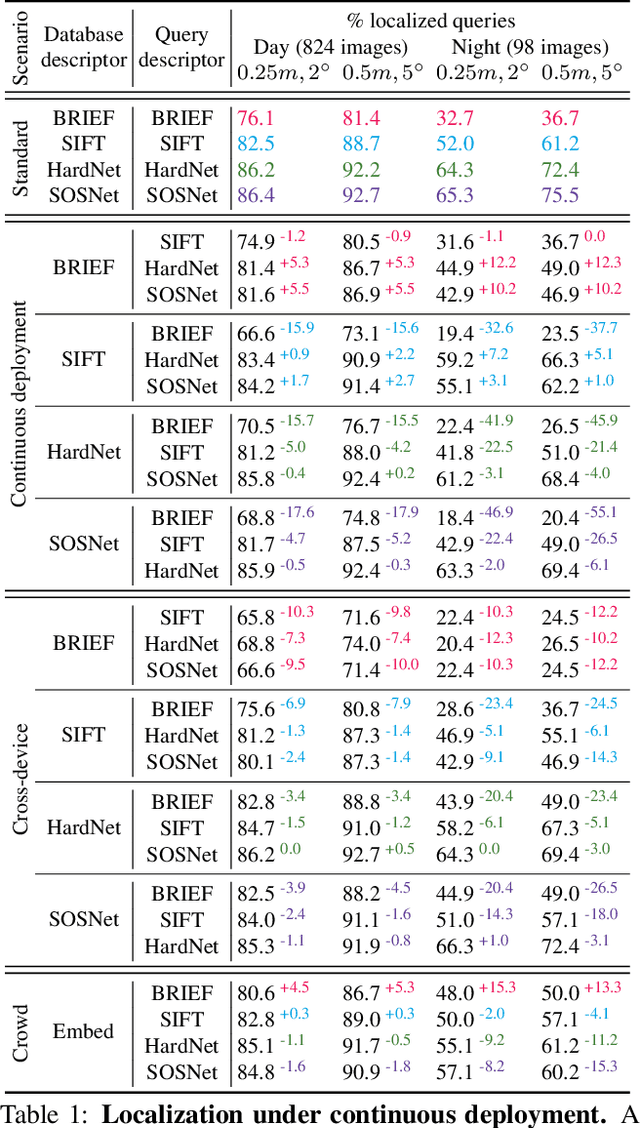
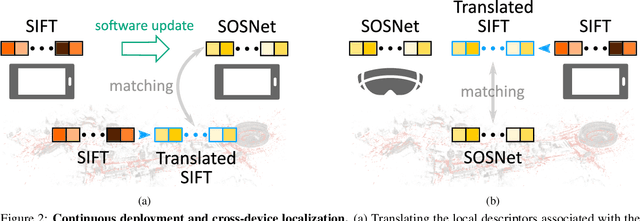
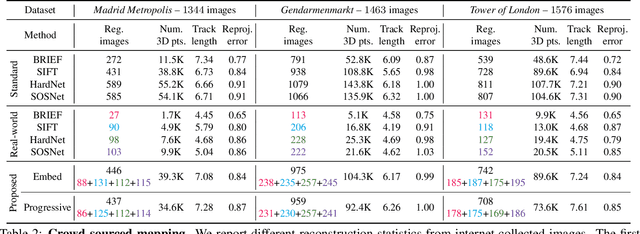
Visual localization and mapping is the key technology underlying the majority of Mixed Reality and robotics systems. Most state-of-the-art approaches rely on local features to establish correspondences between images. In this paper, we present three novel scenarios for localization and mapping which require the continuous update of feature representations and the ability to match across different feature types. While localization and mapping is a fundamental computer vision problem, the traditional setup treats it as a single-shot process using the same local image features throughout the evolution of a map. This assumes the whole process is repeated from scratch whenever the underlying features are changed. However, reiterating it is typically impossible in practice, because raw images are often not stored and re-building the maps could lead to loss of the attached digital content. To overcome the limitations of current approaches, we present the first principled solution to cross-descriptor localization and mapping. Our data-driven approach is agnostic to the feature descriptor type, has low computational requirements, and scales linearly with the number of description algorithms. Extensive experiments demonstrate the effectiveness of our approach on state-of-the-art benchmarks for a variety of handcrafted and learned features.
Live Reconstruction of Large-Scale Dynamic Outdoor Worlds
Apr 15, 2019
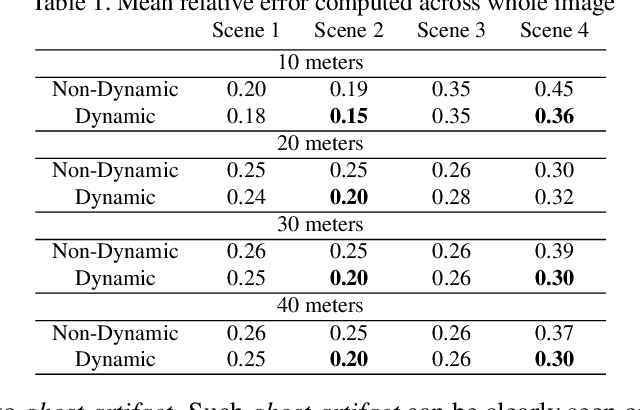
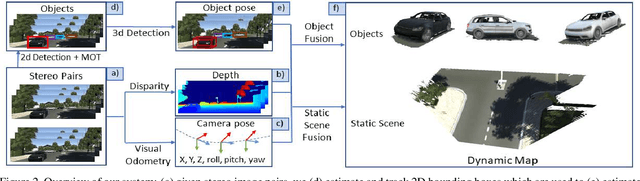
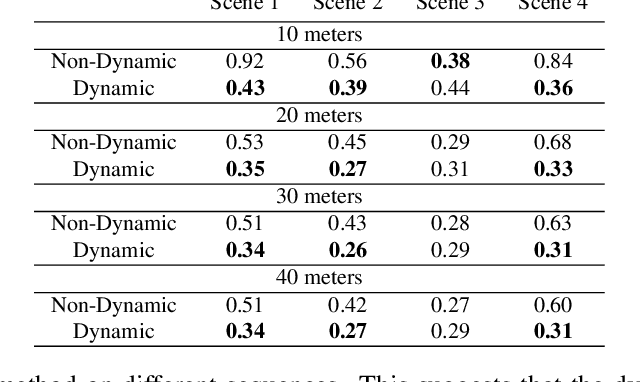
Standard 3D reconstruction pipelines assume stationary world, therefore suffer from `ghost artifacts' whenever dynamic objects are present in the scene. Recent approaches has started tackling this issue, however, they typically either only discard dynamic information, represent it using bounding boxes or per-frame depth or rely on approaches that are inherently slow and not suitable to online settings. We propose an end-to-end system for live reconstruction of large-scale outdoor dynamic environments. We leverage recent advances in computationally efficient data-driven approaches for 6-DoF object pose estimation to segment the scene into objects and stationary `background'. This allows us to represent the scene using a time-dependent (dynamic) map, in which each object is explicitly represented as a separate instance and reconstructed in its own volume. For each time step, our dynamic map maintains a relative pose of each volume with respect to the stationary background. Our system operates in incremental manner which is essential for on-line reconstruction, handles large-scale environments with objects at large distances and runs in (near) real-time. We demonstrate the efficacy of our approach on the KITTI dataset, and provide qualitative and quantitative results showing high-quality dense 3D reconstructions of a number of dynamic scenes.
On the Robustness of Semantic Segmentation Models to Adversarial Attacks
Jul 08, 2018
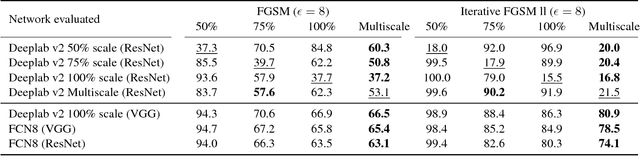
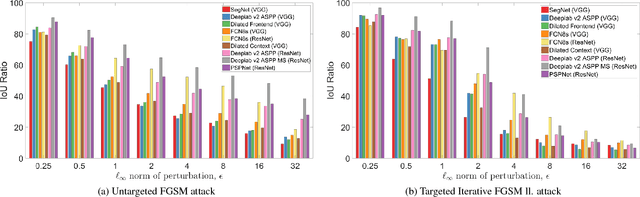

Deep Neural Networks (DNNs) have demonstrated exceptional performance on most recognition tasks such as image classification and segmentation. However, they have also been shown to be vulnerable to adversarial examples. This phenomenon has recently attracted a lot of attention but it has not been extensively studied on multiple, large-scale datasets and structured prediction tasks such as semantic segmentation which often require more specialised networks with additional components such as CRFs, dilated convolutions, skip-connections and multiscale processing. In this paper, we present what to our knowledge is the first rigorous evaluation of adversarial attacks on modern semantic segmentation models, using two large-scale datasets. We analyse the effect of different network architectures, model capacity and multiscale processing, and show that many observations made on the task of classification do not always transfer to this more complex task. Furthermore, we show how mean-field inference in deep structured models, multiscale processing (and more generally, input transformations) naturally implement recently proposed adversarial defenses. Our observations will aid future efforts in understanding and defending against adversarial examples. Moreover, in the shorter term, we show how to effectively benchmark robustness and show which segmentation models should currently be preferred in safety-critical applications due to their inherent robustness.