 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMP-SfM: Monocular Surface Priors for Robust Structure-from-Motion
Apr 28, 2025While Structure-from-Motion (SfM) has seen much progress over the years, state-of-the-art systems are prone to failure when facing extreme viewpoint changes in low-overlap, low-parallax or high-symmetry scenarios. Because capturing images that avoid these pitfalls is challenging, this severely limits the wider use of SfM, especially by non-expert users. We overcome these limitations by augmenting the classical SfM paradigm with monocular depth and normal priors inferred by deep neural networks. Thanks to a tight integration of monocular and multi-view constraints, our approach significantly outperforms existing ones under extreme viewpoint changes, while maintaining strong performance in standard conditions. We also show that monocular priors can help reject faulty associations due to symmetries, which is a long-standing problem for SfM. This makes our approach the first capable of reliably reconstructing challenging indoor environments from few images. Through principled uncertainty propagation, it is robust to errors in the priors, can handle priors inferred by different models with little tuning, and will thus easily benefit from future progress in monocular depth and normal estimation. Our code is publicly available at https://github.com/cvg/mpsfm.
Robust Incremental Structure-from-Motion with Hybrid Features
Sep 29, 2024


Structure-from-Motion (SfM) has become a ubiquitous tool for camera calibration and scene reconstruction with many downstream applications in computer vision and beyond. While the state-of-the-art SfM pipelines have reached a high level of maturity in well-textured and well-configured scenes over the last decades, they still fall short of robustly solving the SfM problem in challenging scenarios. In particular, weakly textured scenes and poorly constrained configurations oftentimes cause catastrophic failures or large errors for the primarily keypoint-based pipelines. In these scenarios, line segments are often abundant and can offer complementary geometric constraints. Their large spatial extent and typically structured configurations lead to stronger geometric constraints as compared to traditional keypoint-based methods. In this work, we introduce an incremental SfM system that, in addition to points, leverages lines and their structured geometric relations. Our technical contributions span the entire pipeline (mapping, triangulation, registration) and we integrate these into a comprehensive end-to-end SfM system that we share as an open-source software with the community. We also present the first analytical method to propagate uncertainties for 3D optimized lines via sensitivity analysis. Experiments show that our system is consistently more robust and accurate compared to the widely used point-based state of the art in SfM -- achieving richer maps and more precise camera registrations, especially under challenging conditions. In addition, our uncertainty-aware localization module alone is able to consistently improve over the state of the art under both point-alone and hybrid setups.
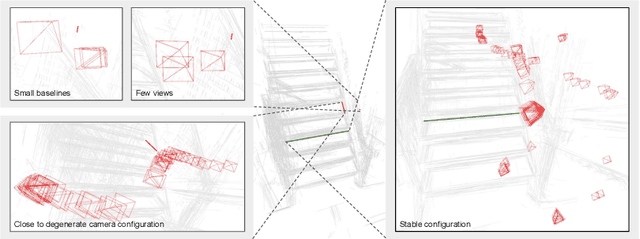
Global Structure-from-Motion Revisited
Jul 29, 2024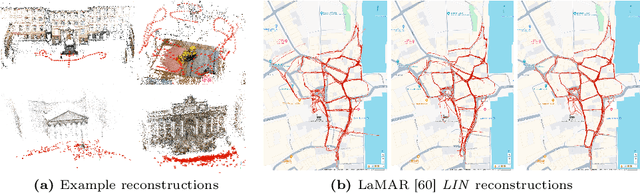
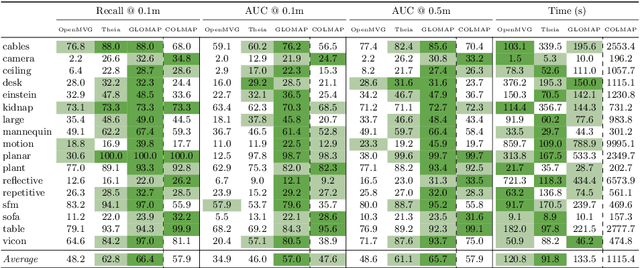
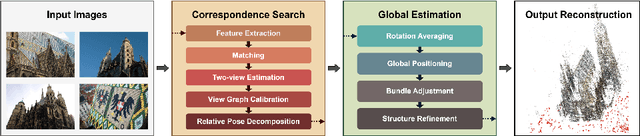

Recovering 3D structure and camera motion from images has been a long-standing focus of computer vision research and is known as Structure-from-Motion (SfM). Solutions to this problem are categorized into incremental and global approaches. Until now, the most popular systems follow the incremental paradigm due to its superior accuracy and robustness, while global approaches are drastically more scalable and efficient. With this work, we revisit the problem of global SfM and propose GLOMAP as a new general-purpose system that outperforms the state of the art in global SfM. In terms of accuracy and robustness, we achieve results on-par or superior to COLMAP, the most widely used incremental SfM, while being orders of magnitude faster. We share our system as an open-source implementation at {https://github.com/colmap/glomap}.
ALSTER: A Local Spatio-Temporal Expert for Online 3D Semantic Reconstruction
Dec 03, 2023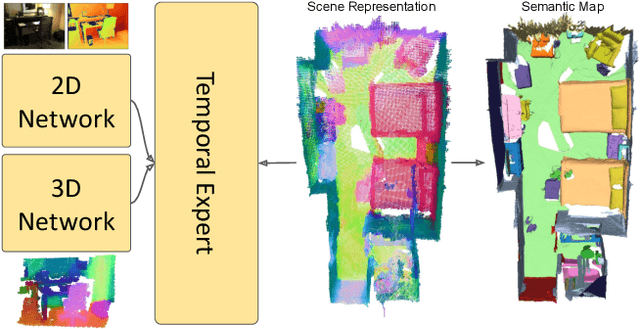
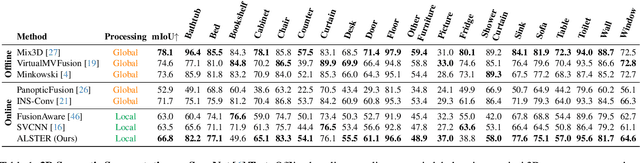
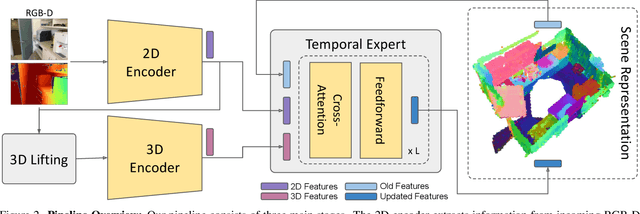
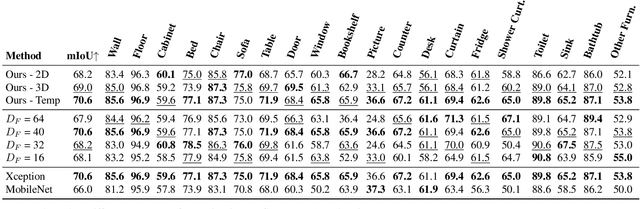
We propose an online 3D semantic segmentation method that incrementally reconstructs a 3D semantic map from a stream of RGB-D frames. Unlike offline methods, ours is directly applicable to scenarios with real-time constraints, such as robotics or mixed reality. To overcome the inherent challenges of online methods, we make two main contributions. First, to effectively extract information from the input RGB-D video stream, we jointly estimate geometry and semantic labels per frame in 3D. A key focus of our approach is to reason about semantic entities both in the 2D input and the local 3D domain to leverage differences in spatial context and network architectures. Our method predicts 2D features using an off-the-shelf segmentation network. The extracted 2D features are refined by a lightweight 3D network to enable reasoning about the local 3D structure. Second, to efficiently deal with an infinite stream of input RGB-D frames, a subsequent network serves as a temporal expert predicting the incremental scene updates by leveraging 2D, 3D, and past information in a learned manner. These updates are then integrated into a global scene representation. Using these main contributions, our method can enable scenarios with real-time constraints and can scale to arbitrary scene sizes by processing and updating the scene only in a local region defined by the new measurement. Our experiments demonstrate improved results compared to existing online methods that purely operate in local regions and show that complementary sources of information can boost the performance. We provide a thorough ablation study on the benefits of different architectural as well as algorithmic design decisions. Our method yields competitive results on the popular ScanNet benchmark and SceneNN dataset.
LaMAR: Benchmarking Localization and Mapping for Augmented Reality
Oct 19, 2022


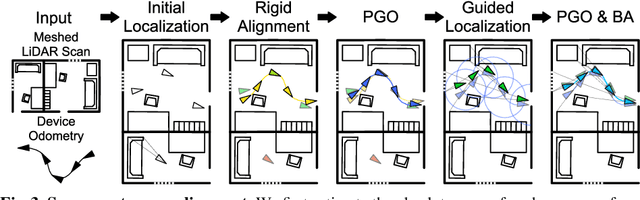
Localization and mapping is the foundational technology for augmented reality (AR) that enables sharing and persistence of digital content in the real world. While significant progress has been made, researchers are still mostly driven by unrealistic benchmarks not representative of real-world AR scenarios. These benchmarks are often based on small-scale datasets with low scene diversity, captured from stationary cameras, and lack other sensor inputs like inertial, radio, or depth data. Furthermore, their ground-truth (GT) accuracy is mostly insufficient to satisfy AR requirements. To close this gap, we introduce LaMAR, a new benchmark with a comprehensive capture and GT pipeline that co-registers realistic trajectories and sensor streams captured by heterogeneous AR devices in large, unconstrained scenes. To establish an accurate GT, our pipeline robustly aligns the trajectories against laser scans in a fully automated manner. As a result, we publish a benchmark dataset of diverse and large-scale scenes recorded with head-mounted and hand-held AR devices. We extend several state-of-the-art methods to take advantage of the AR-specific setup and evaluate them on our benchmark. The results offer new insights on current research and reveal promising avenues for future work in the field of localization and mapping for AR.
Reconstructing and grounding narrated instructional videos in 3D
Sep 10, 2021
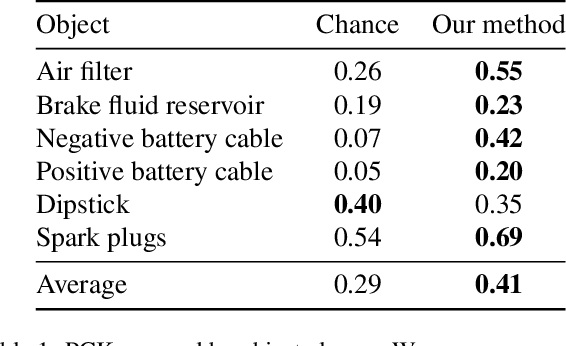
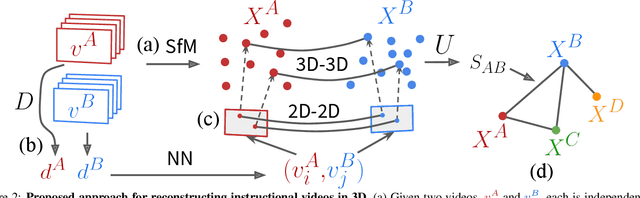

Narrated instructional videos often show and describe manipulations of similar objects, e.g., repairing a particular model of a car or laptop. In this work we aim to reconstruct such objects and to localize associated narrations in 3D. Contrary to the standard scenario of instance-level 3D reconstruction, where identical objects or scenes are present in all views, objects in different instructional videos may have large appearance variations given varying conditions and versions of the same product. Narrations may also have large variation in natural language expressions. We address these challenges by three contributions. First, we propose an approach for correspondence estimation combining learnt local features and dense flow. Second, we design a two-step divide and conquer reconstruction approach where the initial 3D reconstructions of individual videos are combined into a 3D alignment graph. Finally, we propose an unsupervised approach to ground natural language in obtained 3D reconstructions. We demonstrate the effectiveness of our approach for the domain of car maintenance. Given raw instructional videos and no manual supervision, our method successfully reconstructs engines of different car models and associates textual descriptions with corresponding objects in 3D.
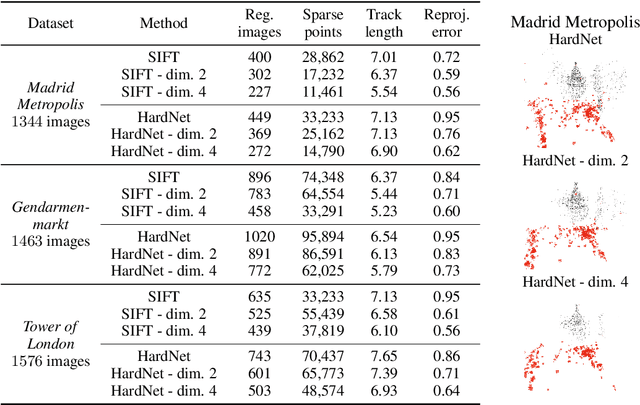
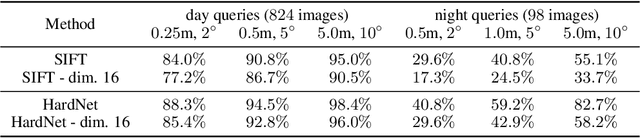
Cross-Descriptor Visual Localization and Mapping
Dec 02, 2020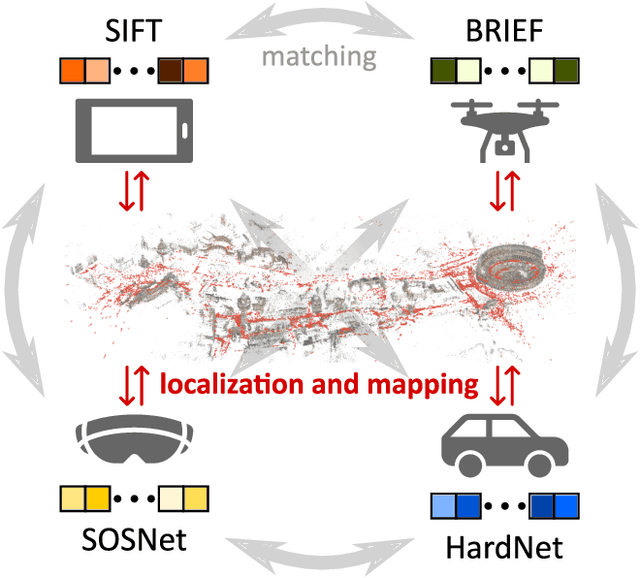
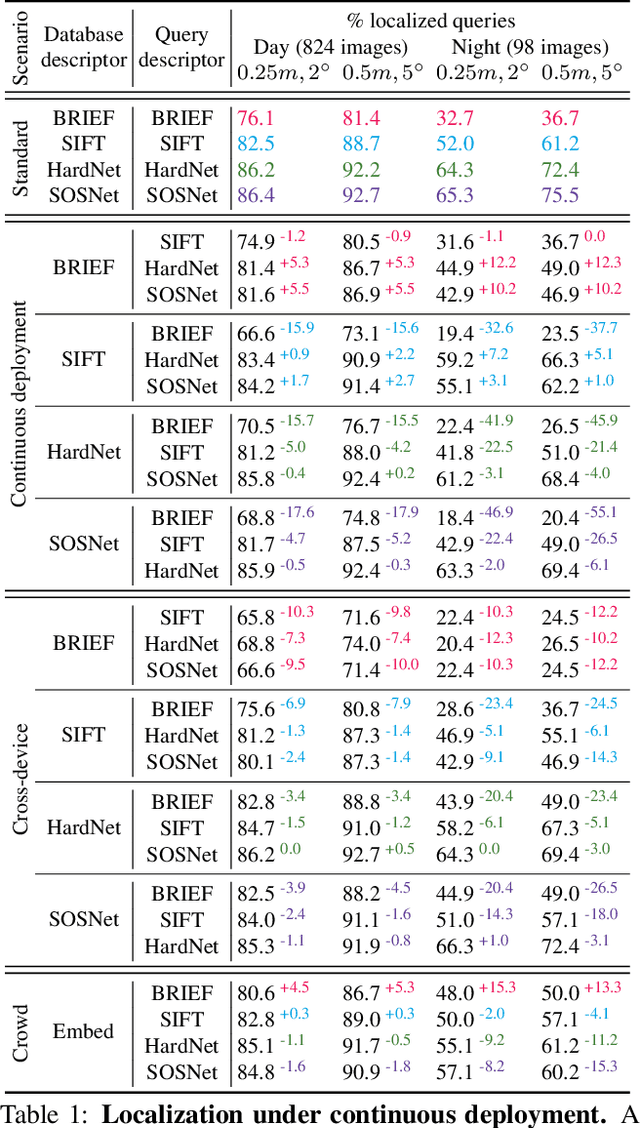
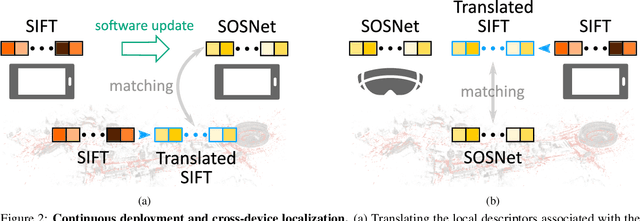
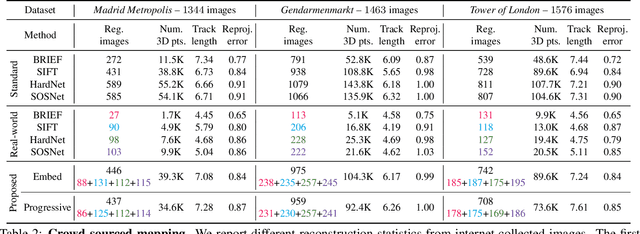
Visual localization and mapping is the key technology underlying the majority of Mixed Reality and robotics systems. Most state-of-the-art approaches rely on local features to establish correspondences between images. In this paper, we present three novel scenarios for localization and mapping which require the continuous update of feature representations and the ability to match across different feature types. While localization and mapping is a fundamental computer vision problem, the traditional setup treats it as a single-shot process using the same local image features throughout the evolution of a map. This assumes the whole process is repeated from scratch whenever the underlying features are changed. However, reiterating it is typically impossible in practice, because raw images are often not stored and re-building the maps could lead to loss of the attached digital content. To overcome the limitations of current approaches, we present the first principled solution to cross-descriptor localization and mapping. Our data-driven approach is agnostic to the feature descriptor type, has low computational requirements, and scales linearly with the number of description algorithms. Extensive experiments demonstrate the effectiveness of our approach on state-of-the-art benchmarks for a variety of handcrafted and learned features.
NeuralFusion: Online Depth Fusion in Latent Space
Nov 30, 2020
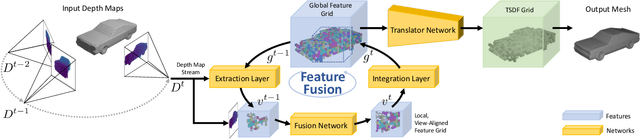
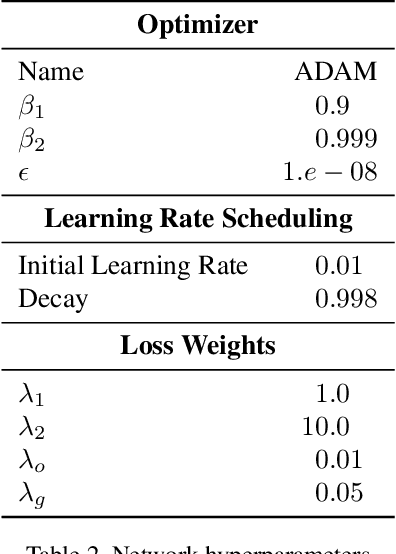
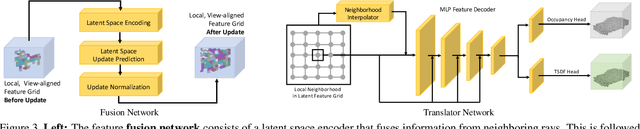
We present a novel online depth map fusion approach that learns depth map aggregation in a latent feature space. While previous fusion methods use an explicit scene representation like signed distance functions (SDFs), we propose a learned feature representation for the fusion. The key idea is a separation between the scene representation used for the fusion and the output scene representation, via an additional translator network. Our neural network architecture consists of two main parts: a depth and feature fusion sub-network, which is followed by a translator sub-network to produce the final surface representation (e.g. TSDF) for visualization or other tasks. Our approach is real-time capable, handles high noise levels, and is particularly able to deal with gross outliers common for photometric stereo-based depth maps. Experiments on real and synthetic data demonstrate improved results compared to the state of the art, especially in challenging scenarios with large amounts of noise and outliers.
HoloLens 2 Research Mode as a Tool for Computer Vision Research
Aug 25, 2020
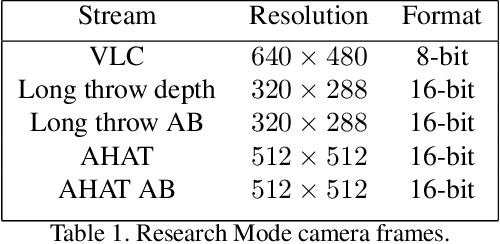


Mixed reality headsets, such as the Microsoft HoloLens 2, are powerful sensing devices with integrated compute capabilities, which makes it an ideal platform for computer vision research. In this technical report, we present HoloLens 2 Research Mode, an API and a set of tools enabling access to the raw sensor streams. We provide an overview of the API and explain how it can be used to build mixed reality applications based on processing sensor data. We also show how to combine the Research Mode sensor data with the built-in eye and hand tracking capabilities provided by HoloLens 2. By releasing the Research Mode API and a set of open-source tools, we aim to foster further research in the fields of computer vision as well as robotics and encourage contributions from the research community.
Privacy-Preserving Visual Feature Descriptors through Adversarial Affine Subspace Embedding
Jun 11, 2020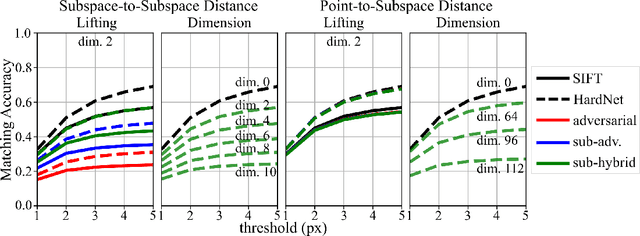

Many computer vision systems require users to upload image features to the cloud for processing and storage. Such features can be exploited to recover sensitive information about the scene or subjects, e.g., by reconstructing the appearance of the original image. To address this privacy concern, we propose a new privacy-preserving feature representation. The core idea of our work is to drop constraints from each feature descriptor by embedding it within an affine subspace containing the original feature as well as one or more adversarial feature samples. Feature matching on the privacy-preserving representation is enabled based on the notion of subspace-to-subspace distance. We experimentally demonstrate the effectiveness of our method and its high practical relevance for applications such as crowd-sourced 3D scene reconstruction and face authentication. Compared to the original features, our approach has only marginal impact on performance but makes it significantly more difficult for an adversary to recover private information.