 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate equivariance via projection-based regularisation
Jan 08, 2026Equivariance is a powerful inductive bias in neural networks, improving generalisation and physical consistency. Recently, however, non-equivariant models have regained attention, due to their better runtime performance and imperfect symmetries that might arise in real-world applications. This has motivated the development of approximately equivariant models that strike a middle ground between respecting symmetries and fitting the data distribution. Existing approaches in this field usually apply sample-based regularisers which depend on data augmentation at training time, incurring a high sample complexity, in particular for continuous groups such as $SO(3)$. This work instead approaches approximate equivariance via a projection-based regulariser which leverages the orthogonal decomposition of linear layers into equivariant and non-equivariant components. In contrast to existing methods, this penalises non-equivariance at an operator level across the full group orbit, rather than point-wise. We present a mathematical framework for computing the non-equivariance penalty exactly and efficiently in both the spatial and spectral domain. In our experiments, our method consistently outperforms prior approximate equivariance approaches in both model performance and efficiency, achieving substantial runtime gains over sample-based regularisers.
Set-LLM: A Permutation-Invariant LLM
May 21, 2025While large language models (LLMs) demonstrate impressive capabilities across numerous applications, their robustness remains a critical concern. This paper is motivated by a specific vulnerability: the order sensitivity of LLMs. This vulnerability manifests itself as the order bias observed when LLMs decide between possible options (for example, a preference for the first option) and the tendency of LLMs to provide different answers when options are reordered. The use cases for this scenario extend beyond the classical case of multiple-choice question answering to the use of LLMs as automated evaluators in AI pipelines, comparing output generated by different models. We introduce Set-LLM, a novel architectural adaptation for pretrained LLMs that enables the processing of mixed set-text inputs with permutation invariance guarantees. The adaptations involve a new attention mask and new positional encodings specifically designed for sets. We provide a theoretical proof of invariance and demonstrate through experiments that Set-LLM can be trained effectively, achieving comparable or improved performance and maintaining the runtime of the original model, while eliminating order sensitivity.
Generating Highly Designable Proteins with Geometric Algebra Flow Matching
Nov 07, 2024



We introduce a generative model for protein backbone design utilizing geometric products and higher order message passing. In particular, we propose Clifford Frame Attention (CFA), an extension of the invariant point attention (IPA) architecture from AlphaFold2, in which the backbone residue frames and geometric features are represented in the projective geometric algebra. This enables to construct geometrically expressive messages between residues, including higher order terms, using the bilinear operations of the algebra. We evaluate our architecture by incorporating it into the framework of FrameFlow, a state-of-the-art flow matching model for protein backbone generation. The proposed model achieves high designability, diversity and novelty, while also sampling protein backbones that follow the statistical distribution of secondary structure elements found in naturally occurring proteins, a property so far only insufficiently achieved by many state-of-the-art generative models.
Grappa -- A Machine Learned Molecular Mechanics Force Field
Mar 25, 2024Simulating large molecular systems over long timescales requires force fields that are both accurate and efficient. In recent years, E(3) equivariant neural networks have lifted the tension between computational efficiency and accuracy of force fields, but they are still several orders of magnitude more expensive than classical molecular mechanics (MM) force fields. Here, we propose a novel machine learning architecture to predict MM parameters from the molecular graph, employing a graph attentional neural network and a transformer with symmetry-preserving positional encoding. The resulting force field, Grappa, outperforms established and other machine-learned MM force fields in terms of accuracy at the same computational efficiency and can be used in existing Molecular Dynamics (MD) engines like GROMACS and OpenMM. It predicts energies and forces of small molecules, peptides, RNA and - showcasing its extensibility to uncharted regions of chemical space - radicals at state-of-the-art MM accuracy. We demonstrate Grappa's transferability to macromolecules in MD simulations, during which large protein are kept stable and small proteins can fold. Our force field sets the stage for biomolecular simulations close to chemical accuracy, but with the same computational cost as established protein force fields.
Connectivity Optimized Nested Graph Networks for Crystal Structures
Feb 27, 2023Graph neural networks (GNNs) have been applied to a large variety of applications in materials science and chemistry. Here, we recapitulate the graph construction for crystalline (periodic) materials and investigate its impact on the GNNs model performance. We suggest the asymmetric unit cell as a representation to reduce the number of atoms by using all symmetries of the system. With a simple but systematically built GNN architecture based on message passing and line graph templates, we furthermore introduce a general architecture (Nested Graph Network, NGN) that is applicable to a wide range of tasks and systematically improves state-of-the-art results on the MatBench benchmark datasets.
HyperInvariances: Amortizing Invariance Learning
Jul 17, 2022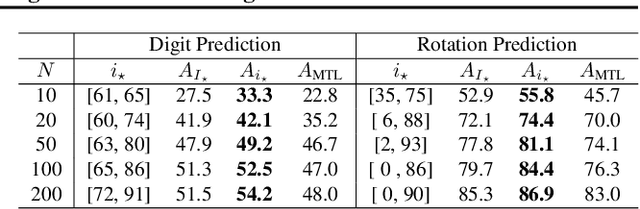
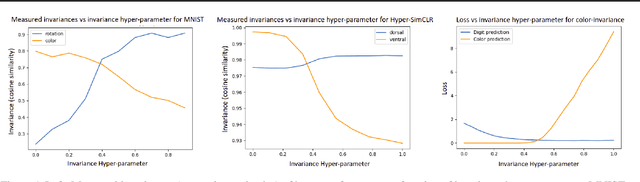

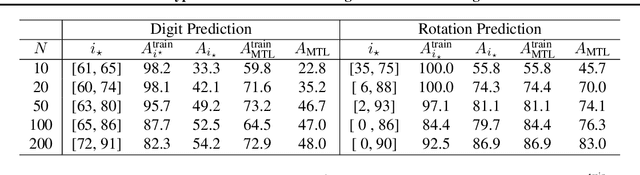
Providing invariances in a given learning task conveys a key inductive bias that can lead to sample-efficient learning and good generalisation, if correctly specified. However, the ideal invariances for many problems of interest are often not known, which has led both to a body of engineering lore as well as attempts to provide frameworks for invariance learning. However, invariance learning is expensive and data intensive for popular neural architectures. We introduce the notion of amortizing invariance learning. In an up-front learning phase, we learn a low-dimensional manifold of feature extractors spanning invariance to different transformations using a hyper-network. Then, for any problem of interest, both model and invariance learning are rapid and efficient by fitting a low-dimensional invariance descriptor an output head. Empirically, this framework can identify appropriate invariances in different downstream tasks and lead to comparable or better test performance than conventional approaches. Our HyperInvariance framework is also theoretically appealing as it enables generalisation-bounds that provide an interesting new operating point in the trade-off between model fit and complexity.
Pushing the Limits of Simple Pipelines for Few-Shot Learning: External Data and Fine-Tuning Make a Difference
Apr 15, 2022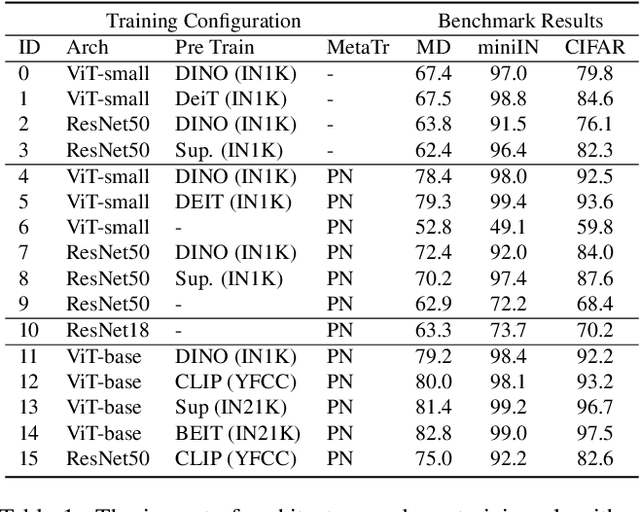
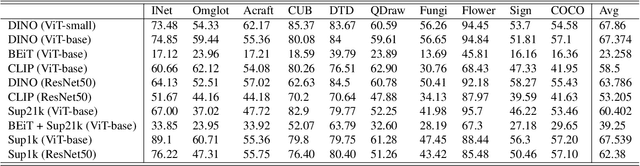

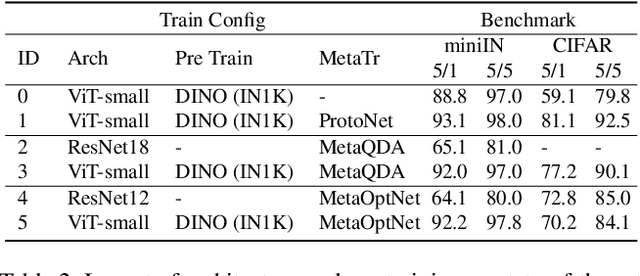
Few-shot learning (FSL) is an important and topical problem in computer vision that has motivated extensive research into numerous methods spanning from sophisticated meta-learning methods to simple transfer learning baselines. We seek to push the limits of a simple-but-effective pipeline for more realistic and practical settings of few-shot image classification. To this end, we explore few-shot learning from the perspective of neural network architecture, as well as a three stage pipeline of network updates under different data supplies, where unsupervised external data is considered for pre-training, base categories are used to simulate few-shot tasks for meta-training, and the scarcely labelled data of an novel task is taken for fine-tuning. We investigate questions such as: (1) How pre-training on external data benefits FSL? (2) How state-of-the-art transformer architectures can be exploited? and (3) How fine-tuning mitigates domain shift? Ultimately, we show that a simple transformer-based pipeline yields surprisingly good performance on standard benchmarks such as Mini-ImageNet, CIFAR-FS, CDFSL and Meta-Dataset. Our code and demo are available at https://hushell.github.io/pmf.
HoloLens 2 Research Mode as a Tool for Computer Vision Research
Aug 25, 2020
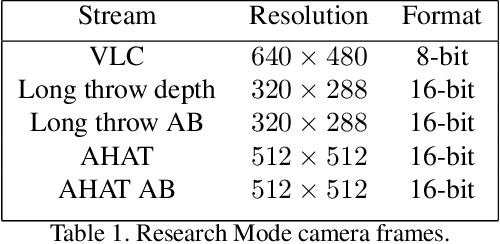


Mixed reality headsets, such as the Microsoft HoloLens 2, are powerful sensing devices with integrated compute capabilities, which makes it an ideal platform for computer vision research. In this technical report, we present HoloLens 2 Research Mode, an API and a set of tools enabling access to the raw sensor streams. We provide an overview of the API and explain how it can be used to build mixed reality applications based on processing sensor data. We also show how to combine the Research Mode sensor data with the built-in eye and hand tracking capabilities provided by HoloLens 2. By releasing the Research Mode API and a set of open-source tools, we aim to foster further research in the fields of computer vision as well as robotics and encourage contributions from the research community.
Independent Subspace Analysis for Unsupervised Learning of Disentangled Representations
Sep 05, 2019



Recently there has been an increased interest in unsupervised learning of disentangled representations using the Variational Autoencoder (VAE) framework. Most of the existing work has focused largely on modifying the variational cost function to achieve this goal. We first show that these modifications, e.g. beta-VAE, simplify the tendency of variational inference to underfit causing pathological over-pruning and over-orthogonalization of learned components. Second we propose a complementary approach: to modify the probabilistic model with a structured latent prior. This prior allows to discover latent variable representations that are structured into a hierarchy of independent vector spaces. The proposed prior has three major advantages: First, in contrast to the standard VAE normal prior the proposed prior is not rotationally invariant. This resolves the problem of unidentifiability of the standard VAE normal prior. Second, we demonstrate that the proposed prior encourages a disentangled latent representation which facilitates learning of disentangled representations. Third, extensive quantitative experiments demonstrate that the prior significantly mitigates the trade-off between reconstruction loss and disentanglement over the state of the art.
Variational Inference for Data-Efficient Model Learning in POMDPs
May 23, 2018



Partially observable Markov decision processes (POMDPs) are a powerful abstraction for tasks that require decision making under uncertainty, and capture a wide range of real world tasks. Today, effective planning approaches exist that generate effective strategies given black-box models of a POMDP task. Yet, an open question is how to acquire accurate models for complex domains. In this paper we propose DELIP, an approach to model learning for POMDPs that utilizes amortized structured variational inference. We empirically show that our model leads to effective control strategies when coupled with state-of-the-art planners. Intuitively, model-based approaches should be particularly beneficial in environments with changing reward structures, or where rewards are initially unknown. Our experiments confirm that DELIP is particularly effective in this setting.