 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSet-LLM: A Permutation-Invariant LLM
May 21, 2025While large language models (LLMs) demonstrate impressive capabilities across numerous applications, their robustness remains a critical concern. This paper is motivated by a specific vulnerability: the order sensitivity of LLMs. This vulnerability manifests itself as the order bias observed when LLMs decide between possible options (for example, a preference for the first option) and the tendency of LLMs to provide different answers when options are reordered. The use cases for this scenario extend beyond the classical case of multiple-choice question answering to the use of LLMs as automated evaluators in AI pipelines, comparing output generated by different models. We introduce Set-LLM, a novel architectural adaptation for pretrained LLMs that enables the processing of mixed set-text inputs with permutation invariance guarantees. The adaptations involve a new attention mask and new positional encodings specifically designed for sets. We provide a theoretical proof of invariance and demonstrate through experiments that Set-LLM can be trained effectively, achieving comparable or improved performance and maintaining the runtime of the original model, while eliminating order sensitivity.
Early-Exit and Instant Confidence Translation Quality Estimation
Feb 20, 2025Quality estimation is omnipresent in machine translation, for both evaluation and generation. Unfortunately, quality estimation models are often opaque and computationally expensive, making them impractical to be part of large-scale pipelines. In this work, we tackle two connected challenges: (1) reducing the cost of quality estimation at scale, and (2) developing an inexpensive uncertainty estimation method for quality estimation. To address the latter, we introduce Instant Confidence COMET, an uncertainty-aware quality estimation model that matches the performance of previous approaches at a fraction of their costs. We extend this to Early-Exit COMET, a quality estimation model that can compute quality scores and associated confidences already at early model layers, allowing us to early-exit computations and reduce evaluation costs. We also apply our model to machine translation reranking. We combine Early-Exit COMET with an upper confidence bound bandit algorithm to find the best candidate from a large pool without having to run the full evaluation model on all candidates. In both cases (evaluation and reranking) our methods reduce the required compute by 50% with very little degradation in performance.
Graph Dimension Attention Networks for Enterprise Credit Assessment
Jul 16, 2024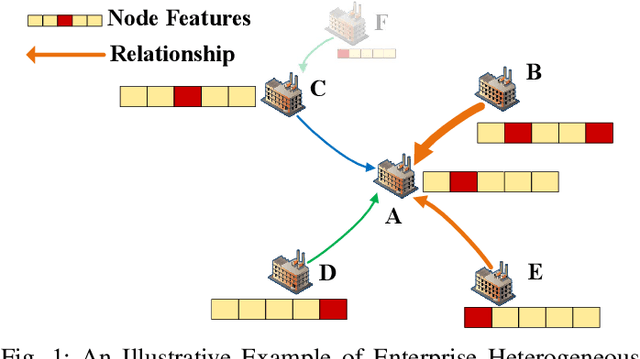
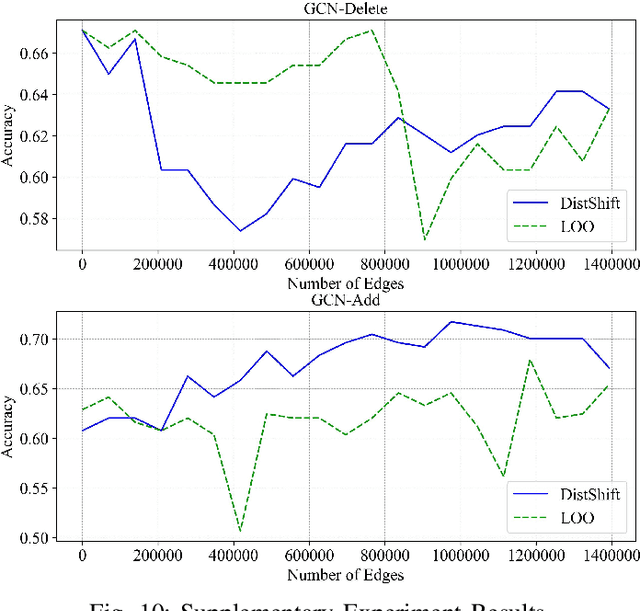
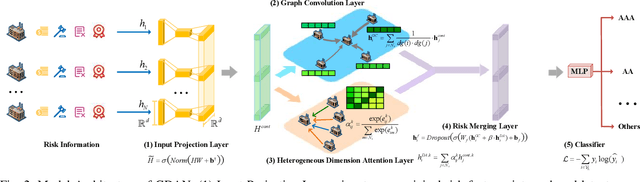
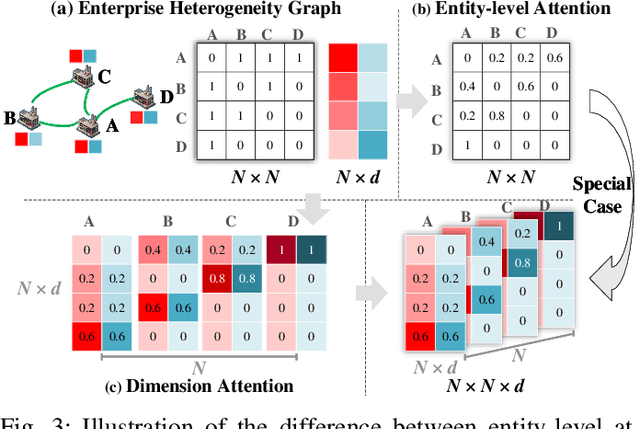
Enterprise credit assessment is critical for evaluating financial risk, and Graph Neural Networks (GNNs), with their advanced capability to model inter-entity relationships, are a natural tool to get a deeper understanding of these financial networks. However, existing GNN-based methodologies predominantly emphasize entity-level attention mechanisms for contagion risk aggregation, often overlooking the heterogeneous importance of different feature dimensions, thus falling short in adequately modeling credit risk levels. To address this issue, we propose a novel architecture named Graph Dimension Attention Network (GDAN), which incorporates a dimension-level attention mechanism to capture fine-grained risk-related characteristics. Furthermore, we explore the interpretability of the GNN-based method in financial scenarios and propose a simple but effective data-centric explainer for GDAN, called GDAN-DistShift. DistShift provides edge-level interpretability by quantifying distribution shifts during the message-passing process. Moreover, we collected a real-world, multi-source Enterprise Credit Assessment Dataset (ECAD) and have made it accessible to the research community since high-quality datasets are lacking in this field. Extensive experiments conducted on ECAD demonstrate the effectiveness of our methods. In addition, we ran GDAN on the well-known datasets SMEsD and DBLP, also with excellent results.
Graphtester: Exploring Theoretical Boundaries of GNNs on Graph Datasets
Jun 30, 2023
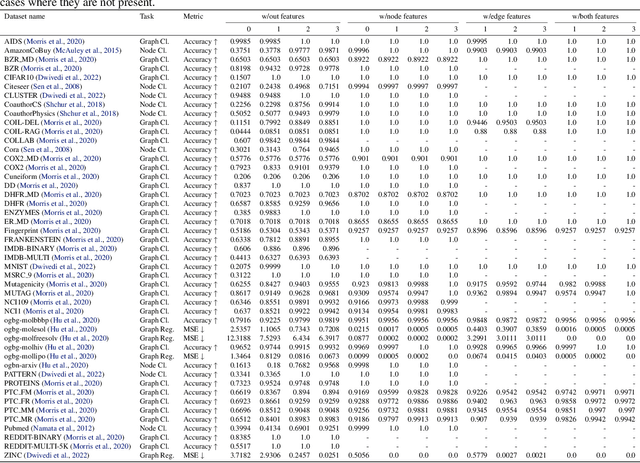
Graph Neural Networks (GNNs) have emerged as a powerful tool for learning from graph-structured data. However, even state-of-the-art architectures have limitations on what structures they can distinguish, imposing theoretical limits on what the networks can achieve on different datasets. In this paper, we provide a new tool called Graphtester for a comprehensive analysis of the theoretical capabilities of GNNs for various datasets, tasks, and scores. We use Graphtester to analyze over 40 different graph datasets, determining upper bounds on the performance of various GNNs based on the number of layers. Further, we show that the tool can also be used for Graph Transformers using positional node encodings, thereby expanding its scope. Finally, we demonstrate that features generated by Graphtester can be used for practical applications such as Graph Transformers, and provide a synthetic dataset to benchmark node and edge features, such as positional encodings. The package is freely available at the following URL: https://github.com/meakbiyik/graphtester.
Graph Neural Networks with Precomputed Node Features
Jun 01, 2022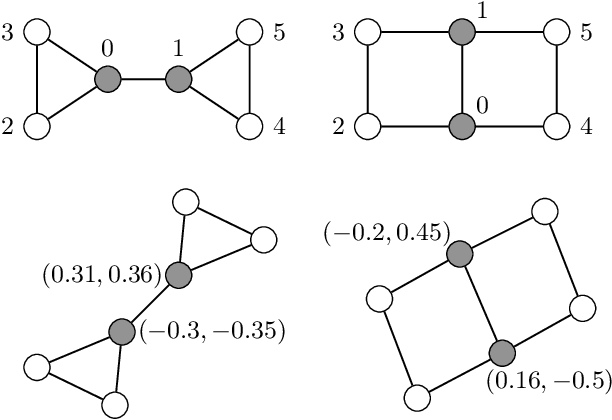
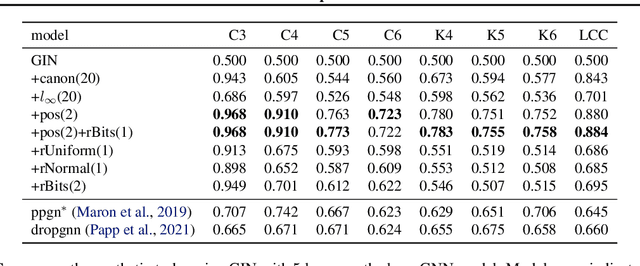
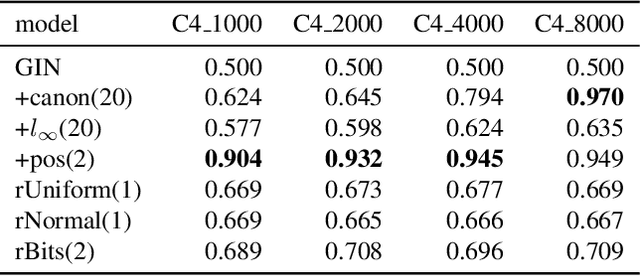
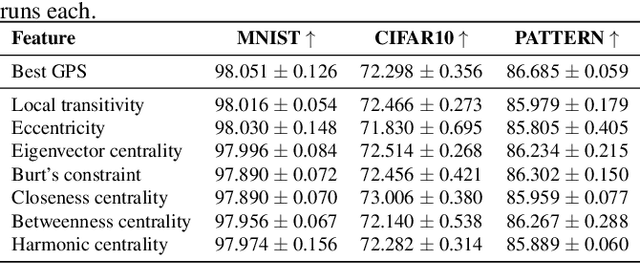
Most Graph Neural Networks (GNNs) cannot distinguish some graphs or indeed some pairs of nodes within a graph. This makes it impossible to solve certain classification tasks. However, adding additional node features to these models can resolve this problem. We introduce several such augmentations, including (i) positional node embeddings, (ii) canonical node IDs, and (iii) random features. These extensions are motivated by theoretical results and corroborated by extensive testing on synthetic subgraph detection tasks. We find that positional embeddings significantly outperform other extensions in these tasks. Moreover, positional embeddings have better sample efficiency, perform well on different graph distributions and even outperform learning with ground truth node positions. Finally, we show that the different augmentations perform competitively on established GNN benchmarks, and advise on when to use them.
A Plug-and-Play Method for Controlled Text Generation
Sep 20, 2021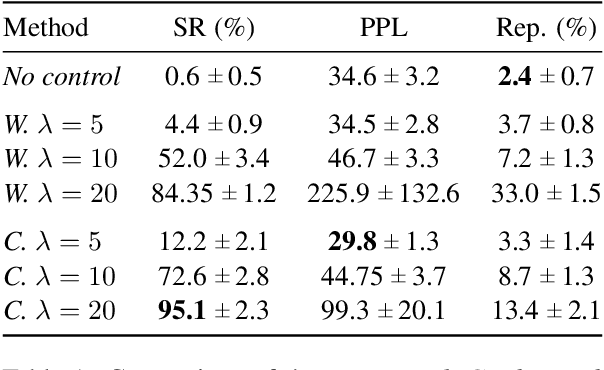
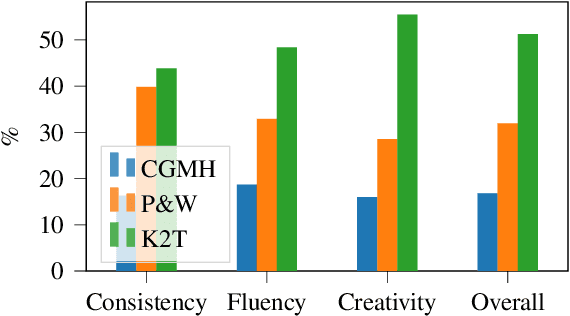
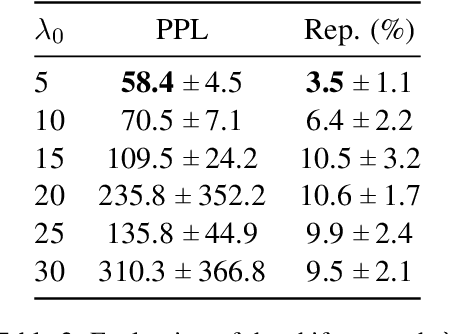
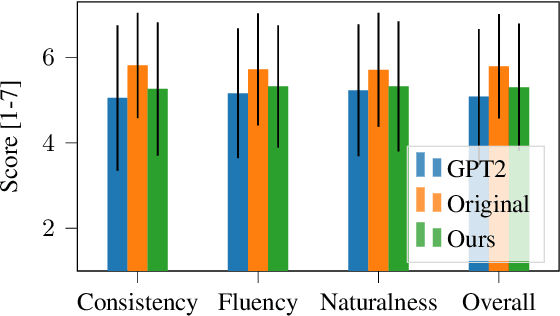
Large pre-trained language models have repeatedly shown their ability to produce fluent text. Yet even when starting from a prompt, generation can continue in many plausible directions. Current decoding methods with the goal of controlling generation, e.g., to ensure specific words are included, either require additional models or fine-tuning, or work poorly when the task at hand is semantically unconstrained, e.g., story generation. In this work, we present a plug-and-play decoding method for controlled language generation that is so simple and intuitive, it can be described in a single sentence: given a topic or keyword, we add a shift to the probability distribution over our vocabulary towards semantically similar words. We show how annealing this distribution can be used to impose hard constraints on language generation, something no other plug-and-play method is currently able to do with SOTA language generators. Despite the simplicity of this approach, we see it works incredibly well in practice: decoding from GPT-2 leads to diverse and fluent sentences while guaranteeing the appearance of given guide words. We perform two user studies, revealing that (1) our method outperforms competing methods in human evaluations; and (2) forcing the guide words to appear in the generated text has no impact on the fluency of the generated text.
Directed Beam Search: Plug-and-Play Lexically Constrained Language Generation
Dec 31, 2020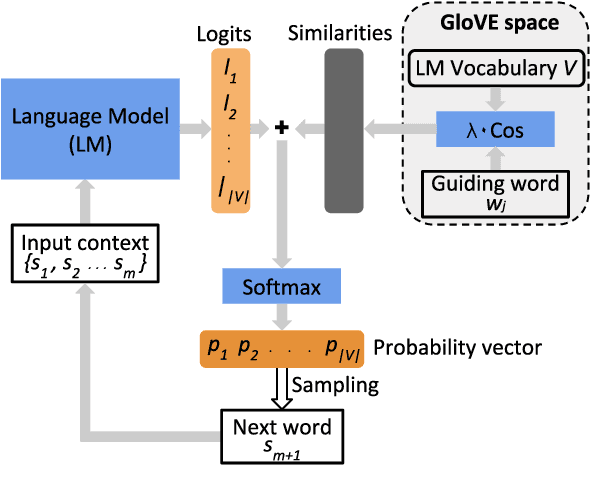
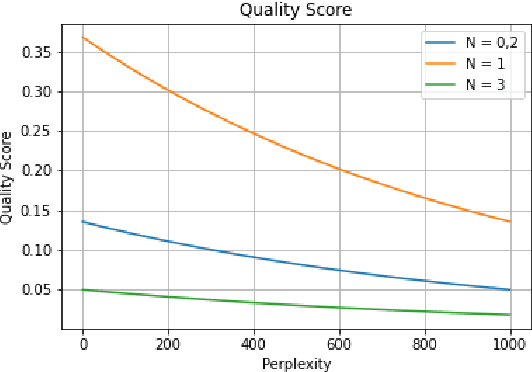

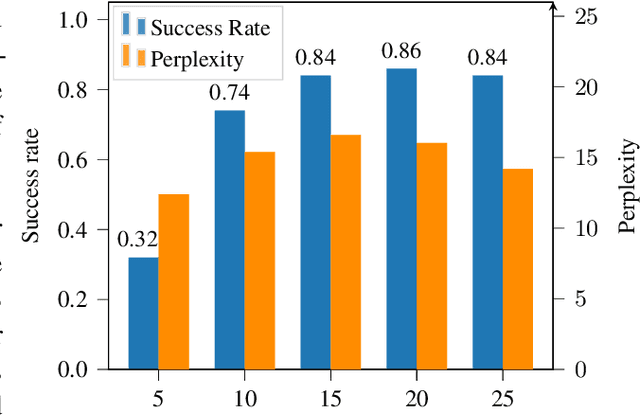
Large pre-trained language models are capable of generating realistic text. However, controlling these models so that the generated text satisfies lexical constraints, i.e., contains specific words, is a challenging problem. Given that state-of-the-art language models are too large to be trained from scratch in a manageable time, it is desirable to control these models without re-training them. Methods capable of doing this are called plug-and-play. Recent plug-and-play methods have been successful in constraining small bidirectional language models as well as forward models in tasks with a restricted search space, e.g., machine translation. However, controlling large transformer-based models to meet lexical constraints without re-training them remains a challenge. In this work, we propose Directed Beam Search (DBS), a plug-and-play method for lexically constrained language generation. Our method can be applied to any language model, is easy to implement and can be used for general language generation. In our experiments we use DBS to control GPT-2. We demonstrate its performance on keyword-to-phrase generation and we obtain comparable results as a state-of-the-art non-plug-and-play model for lexically constrained story generation.
Brain2Word: Decoding Brain Activity for Language Generation
Oct 13, 2020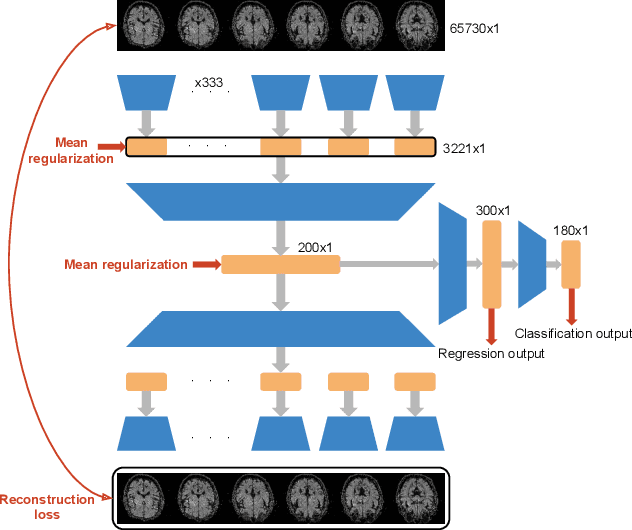
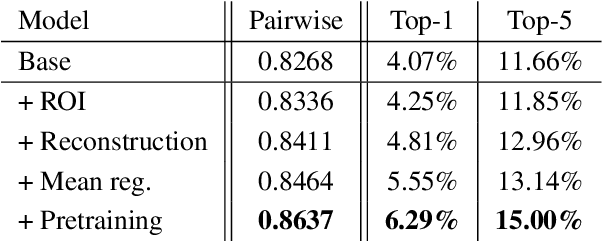
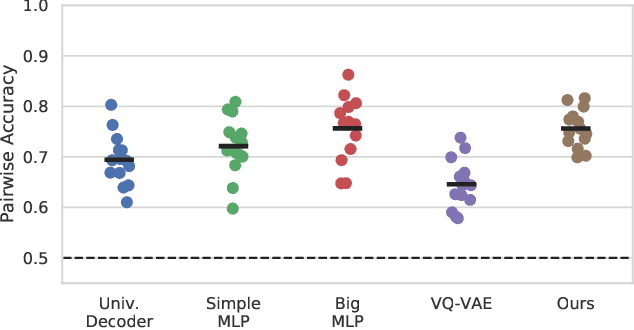
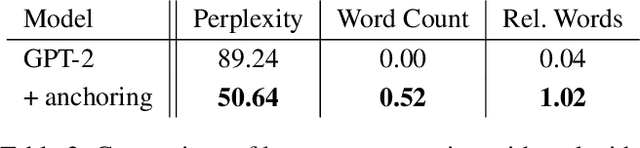
Brain decoding, understood as the process of mapping brain activities to the stimuli that generated them, has been an active research area in the last years. In the case of language stimuli, recent studies have shown that it is possible to decode fMRI scans into an embedding of the word a subject is reading. However, such word embeddings are designed for natural language processing tasks rather than for brain decoding. Therefore, they limit our ability to recover the precise stimulus. In this work, we propose to directly classify an fMRI scan, mapping it to the corresponding word within a fixed vocabulary. Unlike existing work, we evaluate on scans from previously unseen subjects. We argue that this is a more realistic setup and we present a model that can decode fMRI data from unseen subjects. Our model achieves 5.22% Top-1 and 13.59% Top-5 accuracy in this challenging task, significantly outperforming all the considered competitive baselines. Furthermore, we use the decoded words to guide language generation with the GPT-2 model. This way, we advance the quest for a system that translates brain activities into coherent text.