 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMelody Is All You Need For Music Generation
Sep 30, 2024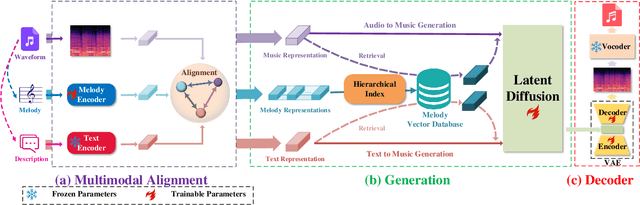
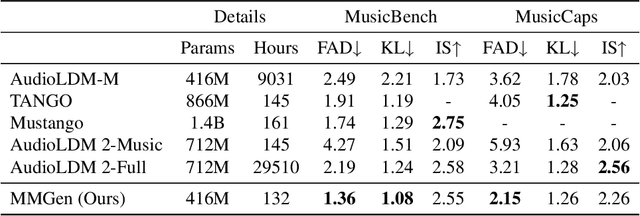
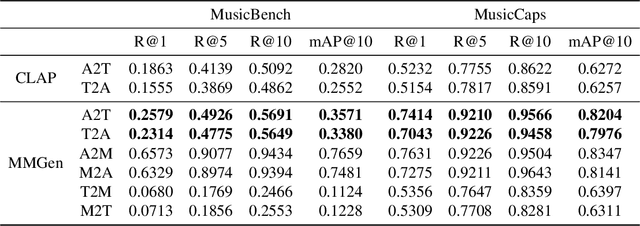
We present the Melody Guided Music Generation (MMGen) model, the first novel approach using melody to guide the music generation that, despite a pretty simple method and extremely limited resources, achieves excellent performance. Specifically, we first align the melody with audio waveforms and their associated descriptions using the multimodal alignment module. Subsequently, we condition the diffusion module on the learned melody representations. This allows MMGen to generate music that matches the style of the provided audio while also producing music that reflects the content of the given text description. To address the scarcity of high-quality data, we construct a multi-modal dataset, MusicSet, which includes melody, text, and audio, and will be made publicly available. We conduct extensive experiments which demonstrate the superiority of the proposed model both in terms of experimental metrics and actual performance quality.
Graph Dimension Attention Networks for Enterprise Credit Assessment
Jul 16, 2024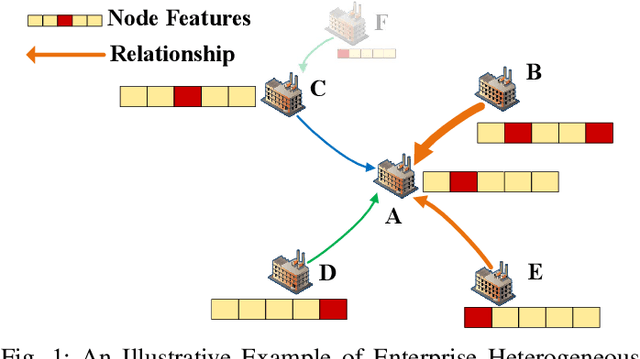
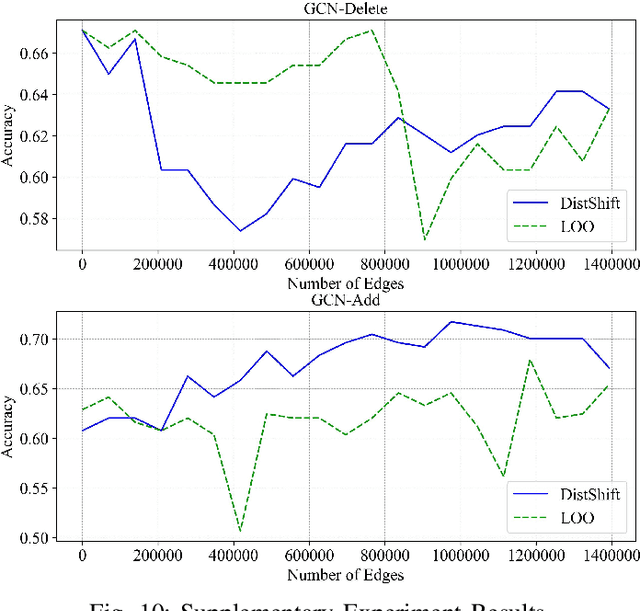
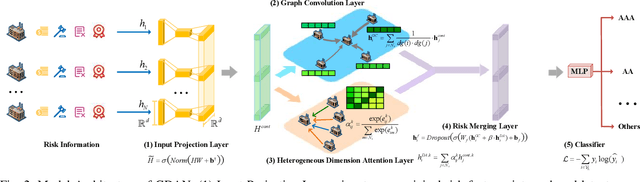
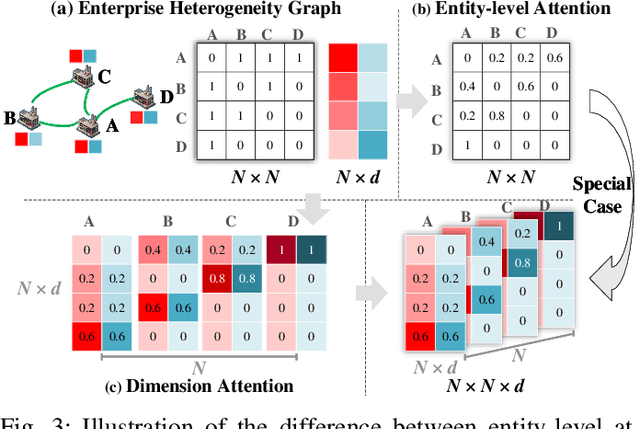
Enterprise credit assessment is critical for evaluating financial risk, and Graph Neural Networks (GNNs), with their advanced capability to model inter-entity relationships, are a natural tool to get a deeper understanding of these financial networks. However, existing GNN-based methodologies predominantly emphasize entity-level attention mechanisms for contagion risk aggregation, often overlooking the heterogeneous importance of different feature dimensions, thus falling short in adequately modeling credit risk levels. To address this issue, we propose a novel architecture named Graph Dimension Attention Network (GDAN), which incorporates a dimension-level attention mechanism to capture fine-grained risk-related characteristics. Furthermore, we explore the interpretability of the GNN-based method in financial scenarios and propose a simple but effective data-centric explainer for GDAN, called GDAN-DistShift. DistShift provides edge-level interpretability by quantifying distribution shifts during the message-passing process. Moreover, we collected a real-world, multi-source Enterprise Credit Assessment Dataset (ECAD) and have made it accessible to the research community since high-quality datasets are lacking in this field. Extensive experiments conducted on ECAD demonstrate the effectiveness of our methods. In addition, we ran GDAN on the well-known datasets SMEsD and DBLP, also with excellent results.
Improving Retrieval-Augmented Large Language Models via Data Importance Learning
Jul 06, 2023



Retrieval augmentation enables large language models to take advantage of external knowledge, for example on tasks like question answering and data imputation. However, the performance of such retrieval-augmented models is limited by the data quality of their underlying retrieval corpus. In this paper, we propose an algorithm based on multilinear extension for evaluating the data importance of retrieved data points. There are exponentially many terms in the multilinear extension, and one key contribution of this paper is a polynomial time algorithm that computes exactly, given a retrieval-augmented model with an additive utility function and a validation set, the data importance of data points in the retrieval corpus using the multilinear extension of the model's utility function. We further proposed an even more efficient ({\epsilon}, {\delta})-approximation algorithm. Our experimental results illustrate that we can enhance the performance of large language models by only pruning or reweighting the retrieval corpus, without requiring further training. For some tasks, this even allows a small model (e.g., GPT-JT), augmented with a search engine API, to outperform GPT-3.5 (without retrieval augmentation). Moreover, we show that weights based on multilinear extension can be computed efficiently in practice (e.g., in less than ten minutes for a corpus with 100 million elements).
Graph Learning: A Comprehensive Survey and Future Directions
Dec 17, 2022Graph learning aims to learn complex relationships among nodes and the topological structure of graphs, such as social networks, academic networks and e-commerce networks, which are common in the real world. Those relationships make graphs special compared with traditional tabular data in which nodes are dependent on non-Euclidean space and contain rich information to explore. Graph learning developed from graph theory to graph data mining and now is empowered with representation learning, making it achieve great performances in various scenarios, even including text, image, chemistry, and biology. Due to the broad application prospects in the real world, graph learning has become a popular and promising area in machine learning. Thousands of works have been proposed to solve various kinds of problems in graph learning and is appealing more and more attention in academic community, which makes it pivotal to survey previous valuable works. Although some of the researchers have noticed this phenomenon and finished impressive surveys on graph learning. However, they failed to link related objectives, methods and applications in a more logical way and cover current ample scenarios as well as challenging problems due to the rapid expansion of the graph learning.
Bankruptcy Prediction via Mixing Intra-Risk and Spillover-Risk
Feb 12, 2022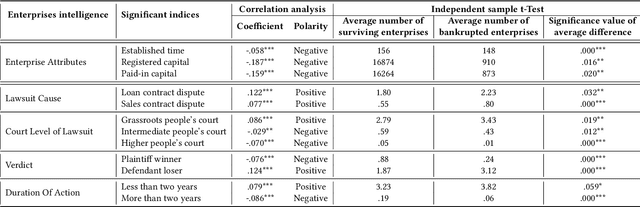
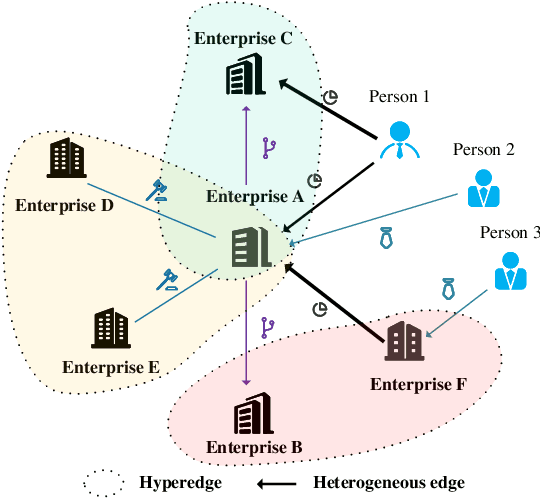
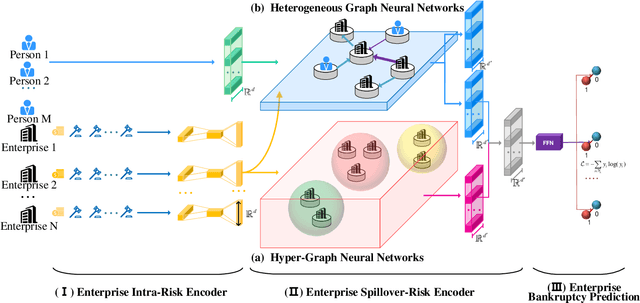
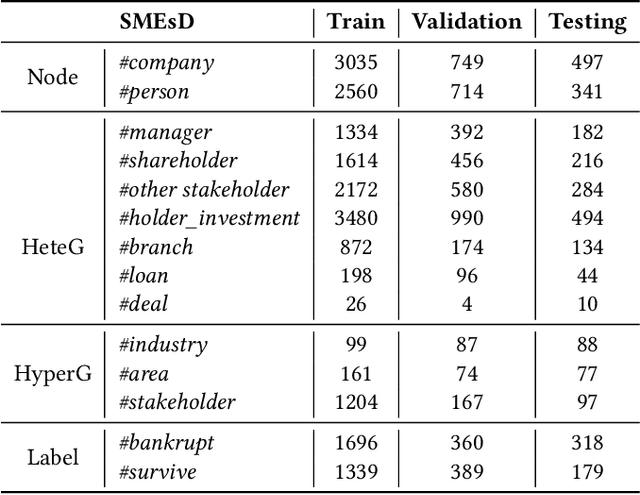
Bankruptcy risk prediction for Small and Medium-sized Enterprises (SMEs) is a crucial step for financial institutions to make the loan decision and identify region economics's early warning. However, previous studies in both finance and AI research fields only consider either the intra-risk or the spillover-risk, ignoring their interactions and their combinatorial effect for simplicity. This paper for the first time considers both risks simultaneously and their joint effect in bankruptcy prediction. Specifically, we first propose an enterprise intra-risk encoder with LSTM based on enterprise risk statistical significance indicators from its basic business information and litigation information for its intra-risk learning. Afterward, we propose an enterprise spillover-risk encoder based on enterprise relational information from the enterprise knowledge graph for its spillover-risk embedding. In particular, the spillover-risk encoder is equipped with both the newly proposed Hyper-Graph Neural Networks (Hyper-GNNs) and Heterogeneous Graph Neural Networks (Heter-GNNs), which is able to model spillover risk from two different aspects, i.e. common risk factors based on hyperedges and direct diffusion risk from the neighbors, respectively. With the two kinds of encoders, a unified framework is designed to simultaneously capture intra-risk and spillover-risk for bankruptcy prediction. To evaluate our model, we collect multi-sources SMEs real-world data and build a novel benchmark dataset SMEsD. We provide open access to the dataset, which is expected to promote the financial risk analysis research further. Experiments on SMEsD against nine SOTA baselines demonstrate the effectiveness of the proposed model for bankruptcy prediction.
Learning Bi-typed Multi-relational Heterogeneous Graph via Dual Hierarchical Attention Networks
Jan 25, 2022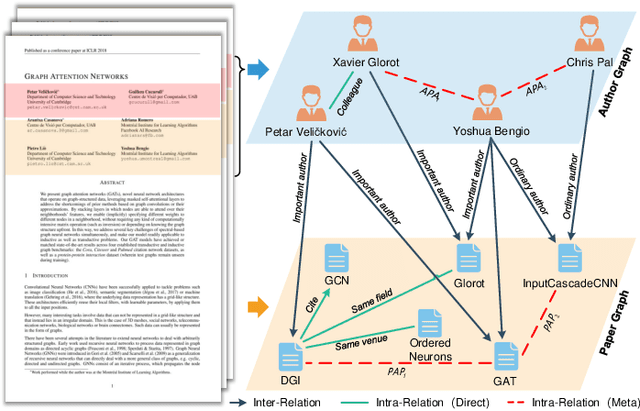
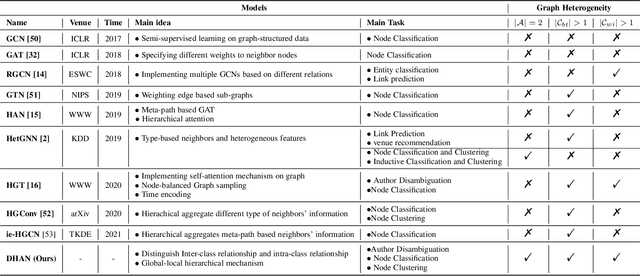
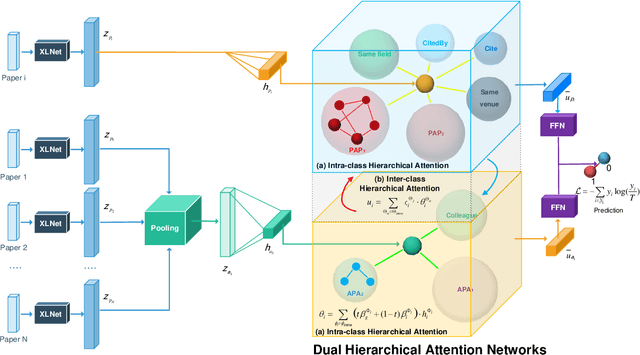

Bi-type multi-relational heterogeneous graph (BMHG) is one of the most common graphs in practice, for example, academic networks, e-commerce user behavior graph and enterprise knowledge graph. It is a critical and challenge problem on how to learn the numerical representation for each node to characterize subtle structures. However, most previous studies treat all node relations in BMHG as the same class of relation without distinguishing the different characteristics between the intra-class relations and inter-class relations of the bi-typed nodes, causing the loss of significant structure information. To address this issue, we propose a novel Dual Hierarchical Attention Networks (DHAN) based on the bi-typed multi-relational heterogeneous graphs to learn comprehensive node representations with the intra-class and inter-class attention-based encoder under a hierarchical mechanism. Specifically, the former encoder aggregates information from the same type of nodes, while the latter aggregates node representations from its different types of neighbors. Moreover, to sufficiently model node multi-relational information in BMHG, we adopt a newly proposed hierarchical mechanism. By doing so, the proposed dual hierarchical attention operations enable our model to fully capture the complex structures of the bi-typed multi-relational heterogeneous graphs. Experimental results on various tasks against the state-of-the-arts sufficiently confirm the capability of DHAN in learning node representations on the BMHGs.
Stock Movement Prediction Based on Bi-typed Hybrid-relational Market Knowledge Graph via Dual Attention Networks
Jan 24, 2022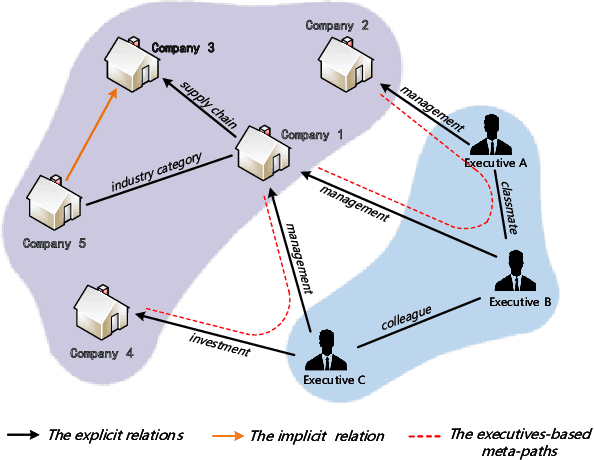
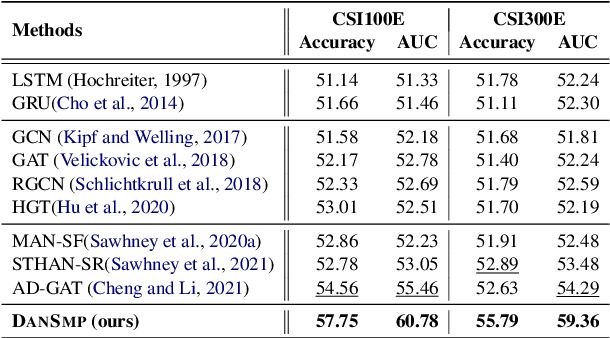
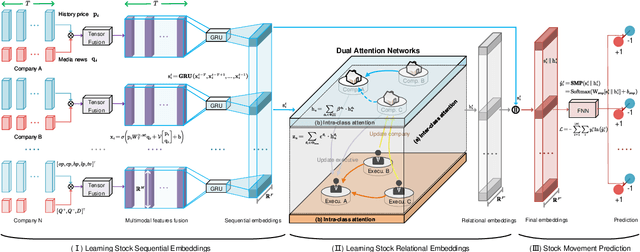
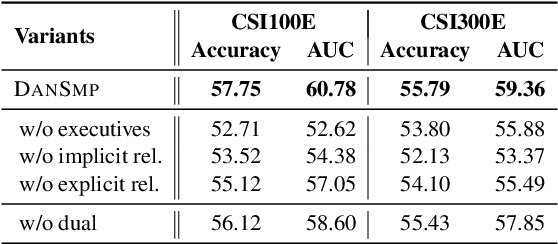
Stock Movement Prediction (SMP) aims at predicting listed companies' stock future price trend, which is a challenging task due to the volatile nature of financial markets. Recent financial studies show that the momentum spillover effect plays a significant role in stock fluctuation. However, previous studies typically only learn the simple connection information among related companies, which inevitably fail to model complex relations of listed companies in the real financial market. To address this issue, we first construct a more comprehensive Market Knowledge Graph (MKG) which contains bi-typed entities including listed companies and their associated executives, and hybrid-relations including the explicit relations and implicit relations. Afterward, we propose DanSmp, a novel Dual Attention Networks to learn the momentum spillover signals based upon the constructed MKG for stock prediction. The empirical experiments on our constructed datasets against nine SOTA baselines demonstrate that the proposed DanSmp is capable of improving stock prediction with the constructed MKG.