 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIvilization v0: Toward Large-Scale Artificial Social Simulation with a Unified Agent Architecture and Adaptive Agent Profiles
Feb 11, 2026AIvilization v0 is a publicly deployed large-scale artificial society that couples a resource-constrained sandbox economy with a unified LLM-agent architecture, aiming to sustain long-horizon autonomy while remaining executable under rapidly changing environment. To mitigate the tension between goal stability and reactive correctness, we introduce (i) a hierarchical branch-thinking planner that decomposes life goals into parallel objective branches and uses simulation-guided validation plus tiered re-planning to ensure feasibility; (ii) an adaptive agent profile with dual-process memory that separates short-term execution traces from long-term semantic consolidation, enabling persistent yet evolving identity; and (iii) a human-in-the-loop steering interface that injects long-horizon objectives and short commands at appropriate abstraction levels, with effects propagated through memory rather than brittle prompt overrides. The environment integrates physiological survival costs, non-substitutable multi-tier production, an AMM-based price mechanism, and a gated education-occupation system. Using high-frequency transactions from the platforms mature phase, we find stable markets that reproduce key stylized facts (heavy-tailed returns and volatility clustering) and produce structured wealth stratification driven by education and access constraints. Ablations show simplified planners can match performance on narrow tasks, while the full architecture is more robust under multi-objective, long-horizon settings, supporting delayed investment and sustained exploration.
MDEval: Evaluating and Enhancing Markdown Awareness in Large Language Models
Jan 25, 2025Large language models (LLMs) are expected to offer structured Markdown responses for the sake of readability in web chatbots (e.g., ChatGPT). Although there are a myriad of metrics to evaluate LLMs, they fail to evaluate the readability from the view of output content structure. To this end, we focus on an overlooked yet important metric -- Markdown Awareness, which directly impacts the readability and structure of the content generated by these language models. In this paper, we introduce MDEval, a comprehensive benchmark to assess Markdown Awareness for LLMs, by constructing a dataset with 20K instances covering 10 subjects in English and Chinese. Unlike traditional model-based evaluations, MDEval provides excellent interpretability by combining model-based generation tasks and statistical methods. Our results demonstrate that MDEval achieves a Spearman correlation of 0.791 and an accuracy of 84.1% with human, outperforming existing methods by a large margin. Extensive experimental results also show that through fine-tuning over our proposed dataset, less performant open-source models are able to achieve comparable performance to GPT-4o in terms of Markdown Awareness. To ensure reproducibility and transparency, MDEval is open sourced at https://github.com/SWUFE-DB-Group/MDEval-Benchmark.
Graph Dimension Attention Networks for Enterprise Credit Assessment
Jul 16, 2024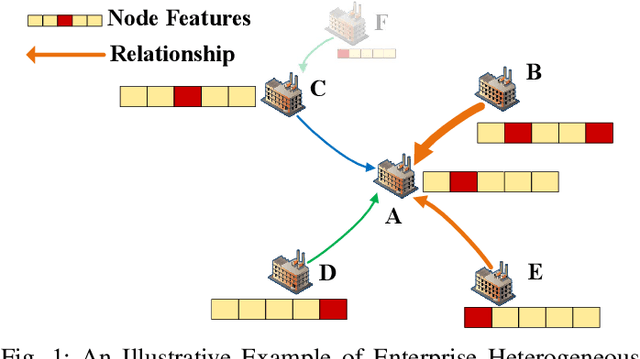
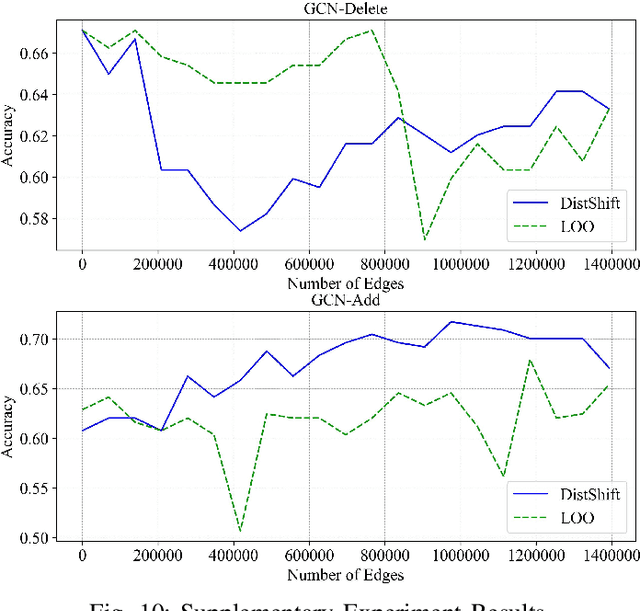
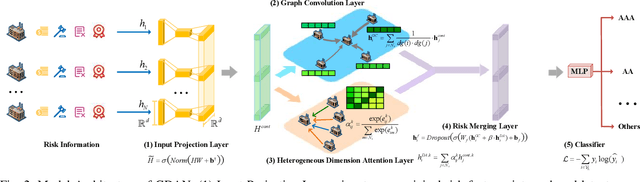
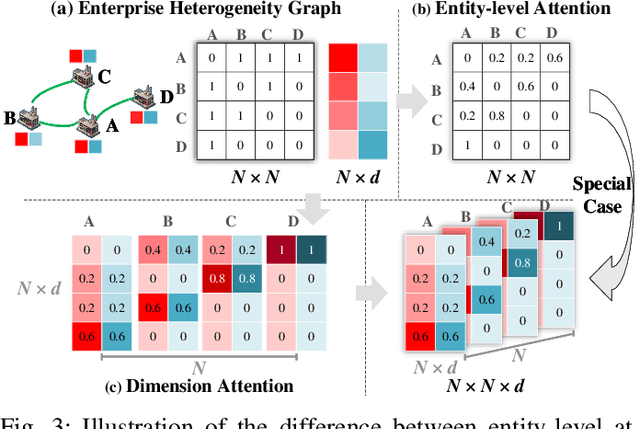
Enterprise credit assessment is critical for evaluating financial risk, and Graph Neural Networks (GNNs), with their advanced capability to model inter-entity relationships, are a natural tool to get a deeper understanding of these financial networks. However, existing GNN-based methodologies predominantly emphasize entity-level attention mechanisms for contagion risk aggregation, often overlooking the heterogeneous importance of different feature dimensions, thus falling short in adequately modeling credit risk levels. To address this issue, we propose a novel architecture named Graph Dimension Attention Network (GDAN), which incorporates a dimension-level attention mechanism to capture fine-grained risk-related characteristics. Furthermore, we explore the interpretability of the GNN-based method in financial scenarios and propose a simple but effective data-centric explainer for GDAN, called GDAN-DistShift. DistShift provides edge-level interpretability by quantifying distribution shifts during the message-passing process. Moreover, we collected a real-world, multi-source Enterprise Credit Assessment Dataset (ECAD) and have made it accessible to the research community since high-quality datasets are lacking in this field. Extensive experiments conducted on ECAD demonstrate the effectiveness of our methods. In addition, we ran GDAN on the well-known datasets SMEsD and DBLP, also with excellent results.
Towards Optimal Customized Architecture for Heterogeneous Federated Learning with Contrastive Cloud-Edge Model Decoupling
Mar 04, 2024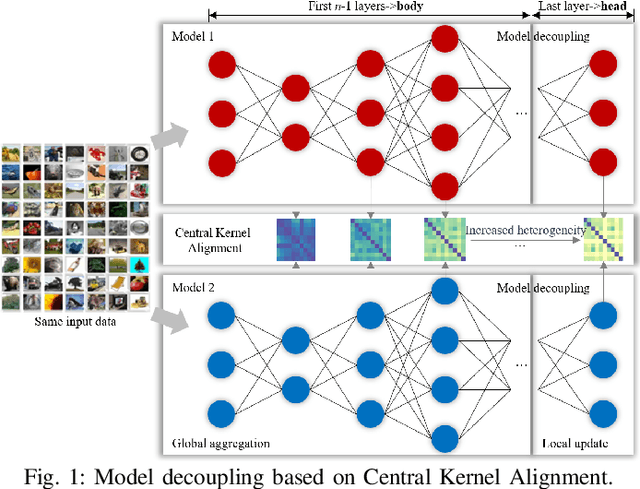
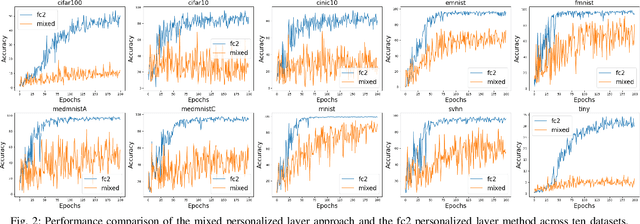
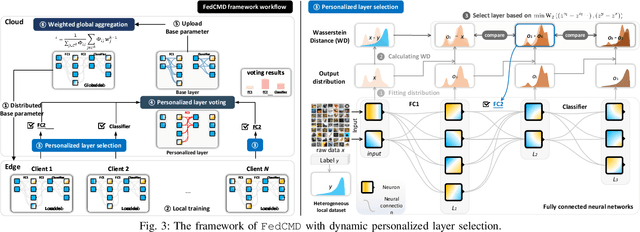
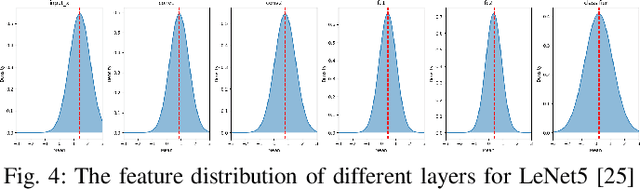
Federated learning, as a promising distributed learning paradigm, enables collaborative training of a global model across multiple network edge clients without the need for central data collecting. However, the heterogeneity of edge data distribution drags the model towards the local minima, which can be distant from the global optimum. Such heterogeneity often leads to slow convergence and substantial communication overhead. To address these issues, we propose a novel federated learning framework called FedCMD, a model decoupling tailored to the Cloud-edge supported federated learning that separates deep neural networks into a body for capturing shared representations in Cloud and a personalized head for migrating data heterogeneity. Our motivation is that, by the deep investigation of the performance of selecting different neural network layers as the personalized head, we found rigidly assigning the last layer as the personalized head in current studies is not always optimal. Instead, it is necessary to dynamically select the personalized layer that maximizes the training performance by taking the representation difference between neighbor layers into account. To find the optimal personalized layer, we utilize the low-dimensional representation of each layer to contrast feature distribution transfer and introduce a Wasserstein-based layer selection method, aimed at identifying the best-match layer for personalization. Additionally, a weighted global aggregation algorithm is proposed based on the selected personalized layer for the practical application of FedCMD. Extensive experiments on ten benchmarks demonstrate the efficiency and superior performance of our solution compared with nine state-of-the-art solutions. All code and results are available at https://github.com/elegy112138/FedCMD.
Taming Gradient Variance in Federated Learning with Networked Control Variates
Oct 26, 2023Federated learning, a decentralized approach to machine learning, faces significant challenges such as extensive communication overheads, slow convergence, and unstable improvements. These challenges primarily stem from the gradient variance due to heterogeneous client data distributions. To address this, we introduce a novel Networked Control Variates (FedNCV) framework for Federated Learning. We adopt the REINFORCE Leave-One-Out (RLOO) as a fundamental control variate unit in the FedNCV framework, implemented at both client and server levels. At the client level, the RLOO control variate is employed to optimize local gradient updates, mitigating the variance introduced by data samples. Once relayed to the server, the RLOO-based estimator further provides an unbiased and low-variance aggregated gradient, leading to robust global updates. This dual-side application is formalized as a linear combination of composite control variates. We provide a mathematical expression capturing this integration of double control variates within FedNCV and present three theoretical results with corresponding proofs. This unique dual structure equips FedNCV to address data heterogeneity and scalability issues, thus potentially paving the way for large-scale applications. Moreover, we tested FedNCV on six diverse datasets under a Dirichlet distribution with {\alpha} = 0.1, and benchmarked its performance against six SOTA methods, demonstrating its superiority.
AWTE-BERT:Attending to Wordpiece Tokenization Explicitly on BERT for Joint Intent Classification and SlotFilling
Nov 29, 2022



Intent classification and slot filling are two core tasks in natural language understanding (NLU). The interaction nature of the two tasks makes the joint models often outperform the single designs. One of the promising solutions, called BERT (Bidirectional Encoder Representations from Transformers), achieves the joint optimization of the two tasks. BERT adopts the wordpiece to tokenize each input token into multiple sub-tokens, which causes a mismatch between the tokens and the labels lengths. Previous methods utilize the hidden states corresponding to the first sub-token as input to the classifier, which limits performance improvement since some hidden semantic informations is discarded in the fine-tune process. To address this issue, we propose a novel joint model based on BERT, which explicitly models the multiple sub-tokens features after wordpiece tokenization, thereby generating the context features that contribute to slot filling. Specifically, we encode the hidden states corresponding to multiple sub-tokens into a context vector via the attention mechanism. Then, we feed each context vector into the slot filling encoder, which preserves the integrity of the sentence. Experimental results demonstrate that our proposed model achieves significant improvement on intent classification accuracy, slot filling F1, and sentence-level semantic frame accuracy on two public benchmark datasets. The F1 score of the slot filling in particular has been improved from 96.1 to 98.2 (2.1% absolute) on the ATIS dataset.
Learning Bi-typed Multi-relational Heterogeneous Graph via Dual Hierarchical Attention Networks
Jan 25, 2022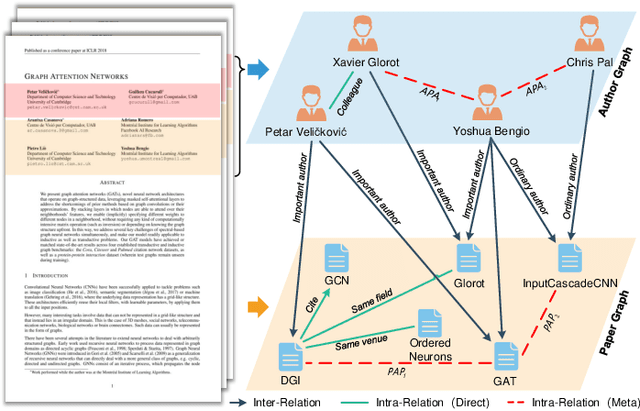
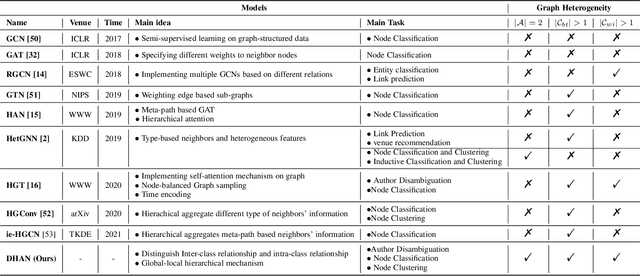
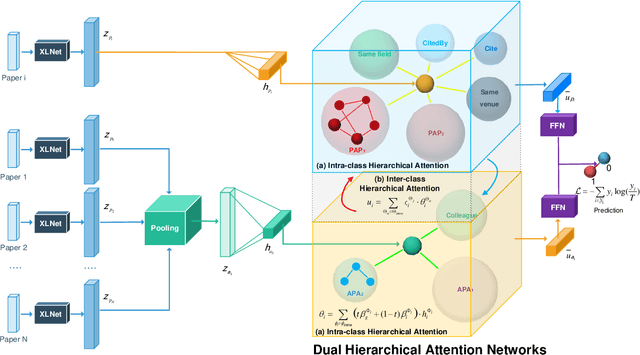

Bi-type multi-relational heterogeneous graph (BMHG) is one of the most common graphs in practice, for example, academic networks, e-commerce user behavior graph and enterprise knowledge graph. It is a critical and challenge problem on how to learn the numerical representation for each node to characterize subtle structures. However, most previous studies treat all node relations in BMHG as the same class of relation without distinguishing the different characteristics between the intra-class relations and inter-class relations of the bi-typed nodes, causing the loss of significant structure information. To address this issue, we propose a novel Dual Hierarchical Attention Networks (DHAN) based on the bi-typed multi-relational heterogeneous graphs to learn comprehensive node representations with the intra-class and inter-class attention-based encoder under a hierarchical mechanism. Specifically, the former encoder aggregates information from the same type of nodes, while the latter aggregates node representations from its different types of neighbors. Moreover, to sufficiently model node multi-relational information in BMHG, we adopt a newly proposed hierarchical mechanism. By doing so, the proposed dual hierarchical attention operations enable our model to fully capture the complex structures of the bi-typed multi-relational heterogeneous graphs. Experimental results on various tasks against the state-of-the-arts sufficiently confirm the capability of DHAN in learning node representations on the BMHGs.
Stock Movement Prediction Based on Bi-typed Hybrid-relational Market Knowledge Graph via Dual Attention Networks
Jan 24, 2022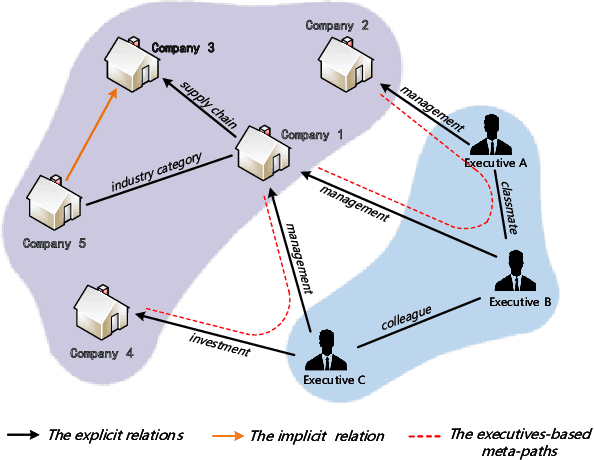
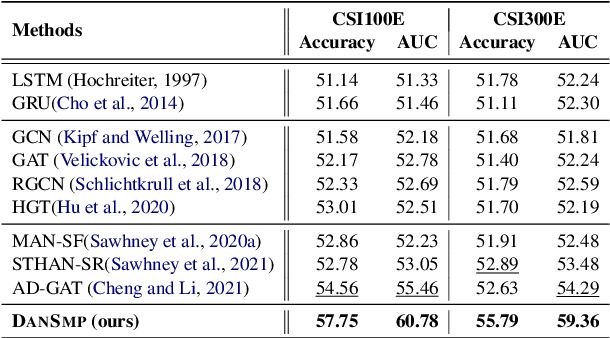
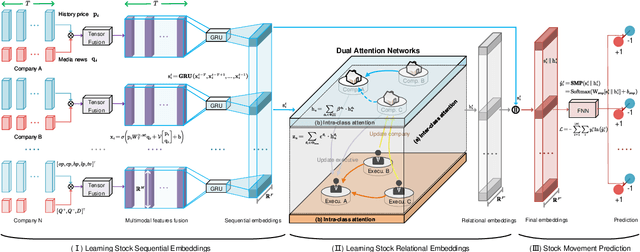
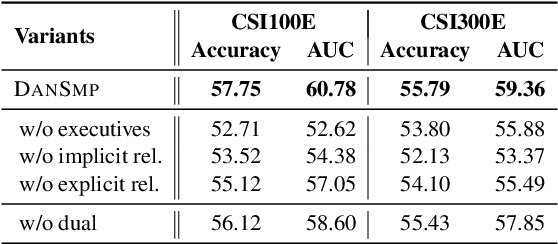
Stock Movement Prediction (SMP) aims at predicting listed companies' stock future price trend, which is a challenging task due to the volatile nature of financial markets. Recent financial studies show that the momentum spillover effect plays a significant role in stock fluctuation. However, previous studies typically only learn the simple connection information among related companies, which inevitably fail to model complex relations of listed companies in the real financial market. To address this issue, we first construct a more comprehensive Market Knowledge Graph (MKG) which contains bi-typed entities including listed companies and their associated executives, and hybrid-relations including the explicit relations and implicit relations. Afterward, we propose DanSmp, a novel Dual Attention Networks to learn the momentum spillover signals based upon the constructed MKG for stock prediction. The empirical experiments on our constructed datasets against nine SOTA baselines demonstrate that the proposed DanSmp is capable of improving stock prediction with the constructed MKG.