 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Cell Sorting with Scalable In Situ FPGA-Accelerated Deep Learning
Mar 16, 2025Precise cell classification is essential in biomedical diagnostics and therapeutic monitoring, particularly for identifying diverse cell types involved in various diseases. Traditional cell classification methods such as flow cytometry depend on molecular labeling which is often costly, time-intensive, and can alter cell integrity. To overcome these limitations, we present a label-free machine learning framework for cell classification, designed for real-time sorting applications using bright-field microscopy images. This approach leverages a teacher-student model architecture enhanced by knowledge distillation, achieving high efficiency and scalability across different cell types. Demonstrated through a use case of classifying lymphocyte subsets, our framework accurately classifies T4, T8, and B cell types with a dataset of 80,000 preprocessed images, accessible via an open-source Python package for easy adaptation. Our teacher model attained 98\% accuracy in differentiating T4 cells from B cells and 93\% accuracy in zero-shot classification between T8 and B cells. Remarkably, our student model operates with only 0.02\% of the teacher model's parameters, enabling field-programmable gate array (FPGA) deployment. Our FPGA-accelerated student model achieves an ultra-low inference latency of just 14.5~$\mu$s and a complete cell detection-to-sorting trigger time of 24.7~$\mu$s, delivering 12x and 40x improvements over the previous state-of-the-art real-time cell analysis algorithm in inference and total latency, respectively, while preserving accuracy comparable to the teacher model. This framework provides a scalable, cost-effective solution for lymphocyte classification, as well as a new SOTA real-time cell sorting implementation for rapid identification of subsets using in situ deep learning on off-the-shelf computing hardware.
Taming Gradient Variance in Federated Learning with Networked Control Variates
Oct 26, 2023Federated learning, a decentralized approach to machine learning, faces significant challenges such as extensive communication overheads, slow convergence, and unstable improvements. These challenges primarily stem from the gradient variance due to heterogeneous client data distributions. To address this, we introduce a novel Networked Control Variates (FedNCV) framework for Federated Learning. We adopt the REINFORCE Leave-One-Out (RLOO) as a fundamental control variate unit in the FedNCV framework, implemented at both client and server levels. At the client level, the RLOO control variate is employed to optimize local gradient updates, mitigating the variance introduced by data samples. Once relayed to the server, the RLOO-based estimator further provides an unbiased and low-variance aggregated gradient, leading to robust global updates. This dual-side application is formalized as a linear combination of composite control variates. We provide a mathematical expression capturing this integration of double control variates within FedNCV and present three theoretical results with corresponding proofs. This unique dual structure equips FedNCV to address data heterogeneity and scalability issues, thus potentially paving the way for large-scale applications. Moreover, we tested FedNCV on six diverse datasets under a Dirichlet distribution with {\alpha} = 0.1, and benchmarked its performance against six SOTA methods, demonstrating its superiority.
MIML: Multiplex Image Machine Learning for High Precision Cell Classification via Mechanical Traits within Microfluidic Systems
Sep 15, 2023Label-free cell classification is advantageous for supplying pristine cells for further use or examination, yet existing techniques frequently fall short in terms of specificity and speed. In this study, we address these limitations through the development of a novel machine learning framework, Multiplex Image Machine Learning (MIML). This architecture uniquely combines label-free cell images with biomechanical property data, harnessing the vast, often underutilized morphological information intrinsic to each cell. By integrating both types of data, our model offers a more holistic understanding of the cellular properties, utilizing morphological information typically discarded in traditional machine learning models. This approach has led to a remarkable 98.3\% accuracy in cell classification, a substantial improvement over models that only consider a single data type. MIML has been proven effective in classifying white blood cells and tumor cells, with potential for broader application due to its inherent flexibility and transfer learning capability. It's particularly effective for cells with similar morphology but distinct biomechanical properties. This innovative approach has significant implications across various fields, from advancing disease diagnostics to understanding cellular behavior.
Stacked Generative Machine Learning Models for Fast Approximations of Steady-State Navier-Stokes Equations
Dec 13, 2021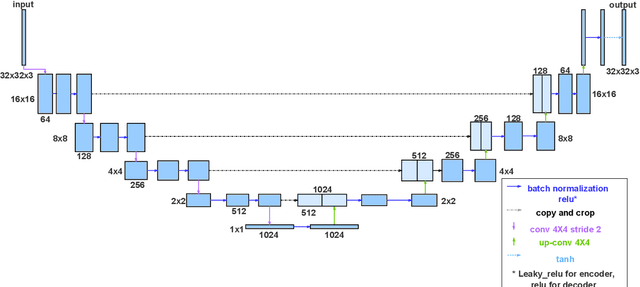
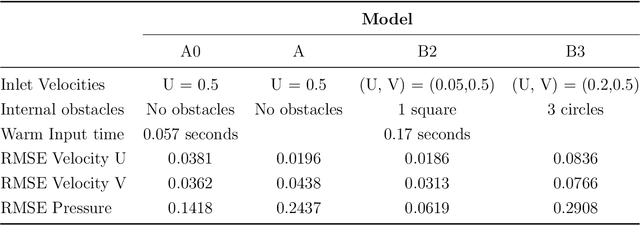
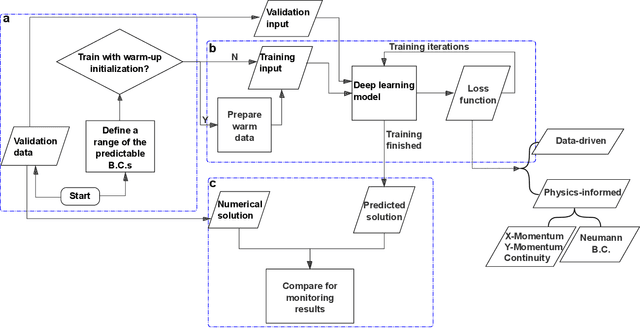
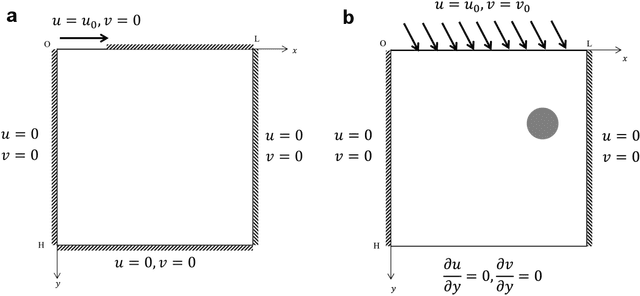
Computational fluid dynamics (CFD) simulations are broadly applied in engineering and physics. A standard description of fluid dynamics requires solving the Navier-Stokes (N-S) equations in different flow regimes. However, applications of CFD simulations are computationally-limited by the availability, speed, and parallelism of high-performance computing. To improve computational efficiency, machine learning techniques have been used to create accelerated data-driven approximations for CFD. A majority of such approaches rely on large labeled CFD datasets that are expensive to obtain at the scale necessary to build robust data-driven models. We develop a weakly-supervised approach to solve the steady-state N-S equations under various boundary conditions, using a multi-channel input with boundary and geometric conditions. We achieve state-of-the-art results without any labeled simulation data, but using a custom data-driven and physics-informed loss function by using and small-scale solutions to prime the model to solve the N-S equations. To improve the resolution and predictability, we train stacked models of increasing complexity generating the numerical solutions for N-S equations. Without expensive computations, our model achieves high predictability with a variety of obstacles and boundary conditions. Given its high flexibility, the model can generate a solution on a 64 x 64 domain within 5 ms on a regular desktop computer which is 1000 times faster than a regular CFD solver. Translation of interactive CFD simulation on local consumer computing hardware enables new applications in real-time predictions on the internet of things devices where data transfer is prohibitive and can increase the scale, speed, and computational cost of boundary-value fluid problems.
Applications and Techniques for Fast Machine Learning in Science
Oct 25, 2021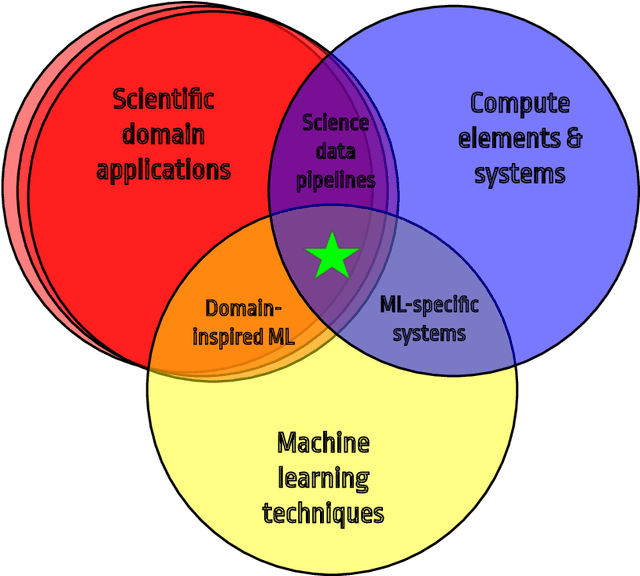
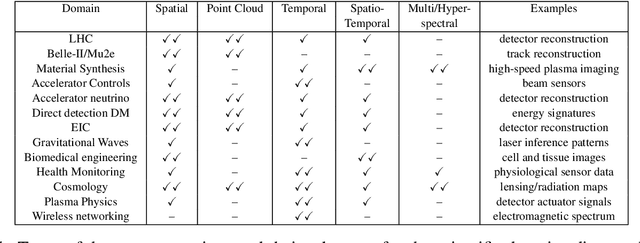
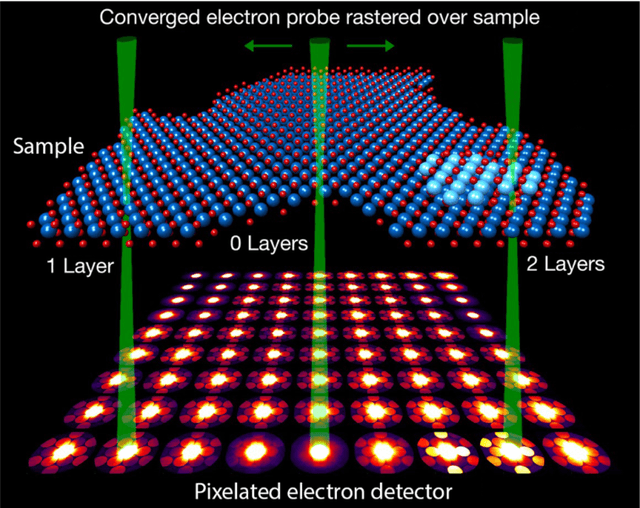
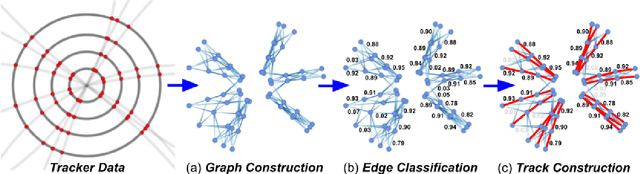
In this community review report, we discuss applications and techniques for fast machine learning (ML) in science -- the concept of integrating power ML methods into the real-time experimental data processing loop to accelerate scientific discovery. The material for the report builds on two workshops held by the Fast ML for Science community and covers three main areas: applications for fast ML across a number of scientific domains; techniques for training and implementing performant and resource-efficient ML algorithms; and computing architectures, platforms, and technologies for deploying these algorithms. We also present overlapping challenges across the multiple scientific domains where common solutions can be found. This community report is intended to give plenty of examples and inspiration for scientific discovery through integrated and accelerated ML solutions. This is followed by a high-level overview and organization of technical advances, including an abundance of pointers to source material, which can enable these breakthroughs.