 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAP: An Agent-to-Instrument Protocol for Autonomous Science
Jun 02, 2026Autonomous science is moving from demonstration to infrastructure. Large language model agents now plan experiments, and self-driving laboratories execute them. Yet every such system rebuilds the link between the reasoning agent and the physical instrument from scratch, against fragmented vendor SDKs and standards built for deterministic software clients rather than probabilistic, goal-directed agents. Recent agent-interoperability protocols clarify two of the three edges of an agentic ecosystem (Anthropic's Model Context Protocol (MCP) standardizes the agent-to-tool edge, and Google's Agent2Agent (A2A) the agent-to-agent edge), but neither models the agent-to-instrument edge, where operations are stateful, safety-critical, exclusively owned, physically embodied, and produce measurements with units, calibration, and uncertainty. We present the Lab Agent Protocol (LAP), a protocol design that fills this gap. LAP retains A2A's peer-to-peer, discovery-first, task-lifecycle structure and adds four physical-world primitives: (i) the InstrumentCard, a signed capability and physical-limit description; (ii) first-class reservation for exclusive instrument and sample locking; (iii) a safety-fence handshake with operator-confirmation tokens cryptographically bound to a specific task and its parameters, gating hazardous and irreversible operations; and (iv) a MeasurementResult schema that makes every result physically typed (QUDT/UCUM), calibration-anchored, uncertainty-bearing, and reproducible by construction. We specify roles, a six-layer architecture, the JSON-RPC method set, the task and safety state machines, the error model, and cross-laboratory federation, and walk a closed-loop autonomous campaign through the protocol end-to-end. LAP is transport-compatible with the A2A/MCP ecosystem and encapsulates rather than replaces existing device standards such as SiLA 2 and OPC-UA.
RepFlow: Representation Enhanced Flow Matching for Causal Effect Estimation
May 07, 2026Estimating causal effects from observational data has become increasingly critical in diverse fields including healthcare, economics, and social policy. The fundamental challenge in causal inference arises from the missing counterfactuals and the selection bias. Existing methods are largely limited to point estimates and lack the capacity for distribution modeling. In this work, we propose RepFlow, a novel framework that formulates causal effect estimation as a joint optimization problem integrating representation learning with Conditional Flow Matching (CFM). RepFlow mitigates selection bias by minimizing the entropically regularized Wasserstein distance between treated and control representations. To enhance numerical stability, we further introduce an $L_2$ normalization constraint on latent representations. This balanced representation enables the flow model to accurately capture the distribution of potential outcomes. Extensive experiments across a wide range of benchmarks demonstrate that RepFlow consistently outperforms existing methods in both point and distributional causal effect estimation.
Decoupled Travel Planning with Behavior Forest
Apr 23, 2026Behavior sequences, composed of executable steps, serve as the operational foundation for multi-constraint planning problems such as travel planning. In such tasks, each planning step is not only constrained locally but also influenced by global constraints spanning multiple subtasks, leading to a tightly coupled and complex decision process. Existing travel planning methods typically rely on a single decision space that entangles all subtasks and constraints, failing to distinguish between locally acting constraints within a subtask and global constraints that span multiple subtasks. Consequently, the model is forced to jointly reason over local and global constraints at each decision step, increasing the reasoning burden and reducing planning efficiency. To address this problem, we propose the Behavior Forest method. Specifically, our approach structures the decision-making process into a forest of parallel behavior trees, where each behavior tree is responsible for a subtask. A global coordination mechanism is introduced to orchestrate the interactions among these trees, enabling modular and coherent travel planning. Within this framework, large language models are embedded as decision engines within behavior tree nodes, performing localized reasoning conditioned on task-specific constraints to generate candidate subplans and adapt decisions based on coordination feedback. The behavior trees, in turn, provide an explicit control structure that guides LLM generation. This design decouples complex tasks and constraints into manageable subspaces, enabling task-specific reasoning and reducing the cognitive load of LLM. Experimental results show that our method outperforms state-of-the-art methods by 6.67% on the TravelPlanner and by 11.82% on the ChinaTravel benchmarks, demonstrating its effectiveness in increasing LLM performance for complex multi-constraint travel planning.
Riemannian Motion Generation: A Unified Framework for Human Motion Representation and Generation via Riemannian Flow Matching
Mar 16, 2026Human motion generation is often learned in Euclidean spaces, although valid motions follow structured non-Euclidean geometry. We present Riemannian Motion Generation (RMG), a unified framework that represents motion on a product manifold and learns dynamics via Riemannian flow matching. RMG factorizes motion into several manifold factors, yielding a scale-free representation with intrinsic normalization, and uses geodesic interpolation, tangent-space supervision, and manifold-preserving ODE integration for training and sampling. On HumanML3D, RMG achieves state-of-the-art FID in the HumanML3D format (0.043) and ranks first on all reported metrics under the MotionStreamer format. On MotionMillion, it also surpasses strong baselines (FID 5.6, R@1 0.86). Ablations show that the compact $\mathscr{T}+\mathscr{R}$ (translation + rotations) representation is the most stable and effective, highlighting geometry-aware modeling as a practical and scalable route to high-fidelity motion generation.
DOS: Dependency-Oriented Sampler for Masked Diffusion Language Models
Mar 16, 2026Masked diffusion language models (MDLMs) have recently emerged as a new paradigm in language modeling, offering flexible generation dynamics and enabling efficient parallel decoding. However, existing decoding strategies for pre-trained MDLMs predominantly rely on token-level uncertainty criteria, while largely overlooking sequence-level information and inter-token dependencies. To address this limitation, we propose Dependency-Oriented Sampler (DOS), a training-free decoding strategy that leverages inter-token dependencies to inform token updates during generation. Specifically, DOS exploits attention matrices from transformer blocks to approximate inter-token dependencies, emphasizing information from unmasked tokens when updating masked positions. Empirical results demonstrate that DOS consistently achieves superior performance on both code generation and mathematical reasoning tasks. Moreover, DOS can be seamlessly integrated with existing parallel sampling methods, leading to improved generation efficiency without sacrificing generation quality.
RAGPerf: An End-to-End Benchmarking Framework for Retrieval-Augmented Generation Systems
Mar 11, 2026We present the design and implementation of a RAG-based AI system benchmarking (RAGPerf) framework for characterizing the system behaviors of RAG pipelines. To facilitate detailed profiling and fine-grained performance analysis, RAGPerf decouples the RAG workflow into several modular components - embedding, indexing, retrieval, reranking, and generation. RAGPerf offers the flexibility for users to configure the core parameters of each component and examine their impact on the end-to-end query performance and quality. RAGPerf has a workload generator to model real-world scenarios by supporting diverse datasets (e.g., text, pdf, code, and audio), different retrieval and update ratios, and query distributions. RAGPerf also supports different embedding models, major vector databases such as LanceDB, Milvus, Qdrant, Chroma, and Elasticsearch, as well as different LLMs for content generation. It automates the collection of performance metrics (i.e., end-to-end query throughput, host/GPU memory footprint, and CPU/GPU utilization) and accuracy metrics (i.e., context recall, query accuracy, and factual consistency). We demonstrate the capabilities of RAGPerf through a comprehensive set of experiments and open source its codebase at GitHub. Our evaluation shows that RAGPerf incurs negligible performance overhead.
DARE: Aligning LLM Agents with the R Statistical Ecosystem via Distribution-Aware Retrieval
Mar 05, 2026Large Language Model (LLM) agents can automate data-science workflows, but many rigorous statistical methods implemented in R remain underused because LLMs struggle with statistical knowledge and tool retrieval. Existing retrieval-augmented approaches focus on function-level semantics and ignore data distribution, producing suboptimal matches. We propose DARE (Distribution-Aware Retrieval Embedding), a lightweight, plug-and-play retrieval model that incorporates data distribution information into function representations for R package retrieval. Our main contributions are: (i) RPKB, a curated R Package Knowledge Base derived from 8,191 high-quality CRAN packages; (ii) DARE, an embedding model that fuses distributional features with function metadata to improve retrieval relevance; and (iii) RCodingAgent, an R-oriented LLM agent for reliable R code generation and a suite of statistical analysis tasks for systematically evaluating LLM agents in realistic analytical scenarios. Empirically, DARE achieves an NDCG at 10 of 93.47%, outperforming state-of-the-art open-source embedding models by up to 17% on package retrieval while using substantially fewer parameters. Integrating DARE into RCodingAgent yields significant gains on downstream analysis tasks. This work helps narrow the gap between LLM automation and the mature R statistical ecosystem.
SpecAttn: Co-Designing Sparse Attention with Self-Speculative Decoding
Feb 06, 2026Long-context large language model (LLM) inference has become the norm for today's AI applications. However, it is severely bottlenecked by the increasing memory demands of its KV cache. Previous works have shown that self-speculative decoding with sparse attention, where tokens are drafted using a subset of the KV cache and verified in parallel with full KV cache, speeds up inference in a lossless way. However, this approach relies on standalone KV selection algorithms to select the KV entries used for drafting and overlooks that the criticality of each KV entry is inherently computed during verification. In this paper, we propose SpecAttn, a self-speculative decoding method with verification-guided sparse attention. SpecAttn identifies critical KV entries as a byproduct of verification and only loads these entries when drafting subsequent tokens. This not only improves draft token acceptance rate but also incurs low KV selection overhead, thereby improving decoding throughput. SpecAttn achieves 2.81$\times$ higher throughput over vanilla auto-regressive decoding and 1.29$\times$ improvement over state-of-the-art sparsity-based self-speculative decoding methods.
DSAEval: Evaluating Data Science Agents on a Wide Range of Real-World Data Science Problems
Jan 20, 2026Recent LLM-based data agents aim to automate data science tasks ranging from data analysis to deep learning. However, the open-ended nature of real-world data science problems, which often span multiple taxonomies and lack standard answers, poses a significant challenge for evaluation. To address this, we introduce DSAEval, a benchmark comprising 641 real-world data science problems grounded in 285 diverse datasets, covering both structured and unstructured data (e.g., vision and text). DSAEval incorporates three distinctive features: (1) Multimodal Environment Perception, which enables agents to interpret observations from multiple modalities including text and vision; (2) Multi-Query Interactions, which mirror the iterative and cumulative nature of real-world data science projects; and (3) Multi-Dimensional Evaluation, which provides a holistic assessment across reasoning, code, and results. We systematically evaluate 11 advanced agentic LLMs using DSAEval. Our results show that Claude-Sonnet-4.5 achieves the strongest overall performance, GPT-5.2 is the most efficient, and MiMo-V2-Flash is the most cost-effective. We further demonstrate that multimodal perception consistently improves performance on vision-related tasks, with gains ranging from 2.04% to 11.30%. Overall, while current data science agents perform well on structured data and routine data anlysis workflows, substantial challenges remain in unstructured domains. Finally, we offer critical insights and outline future research directions to advance the development of data science agents.
On Conditional Stochastic Interpolation for Generative Nonlinear Sufficient Dimension Reduction
Dec 22, 2025
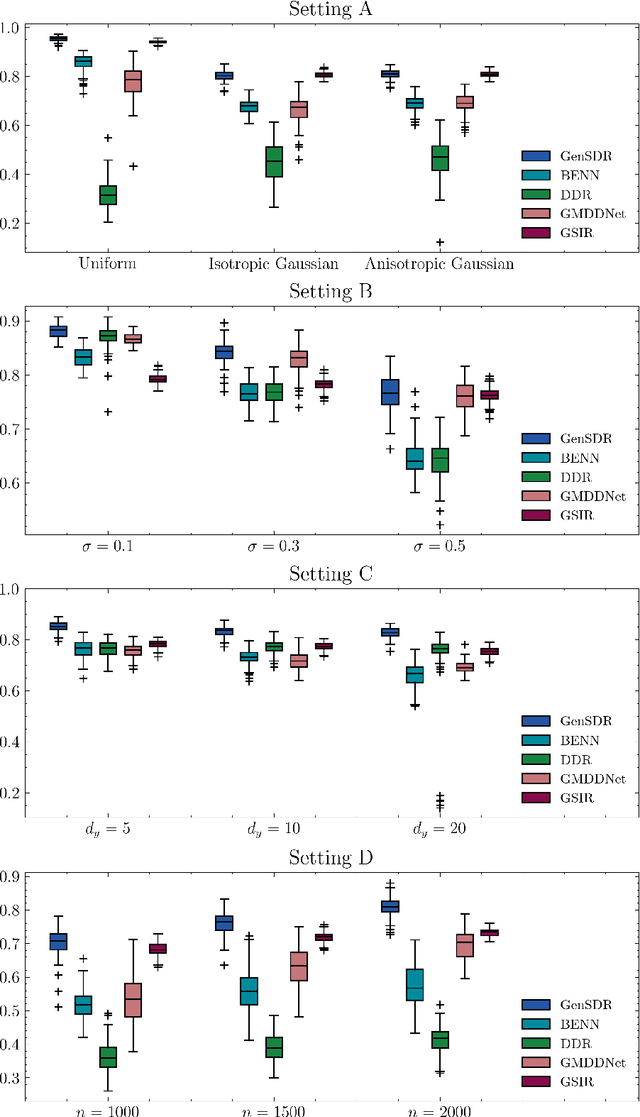
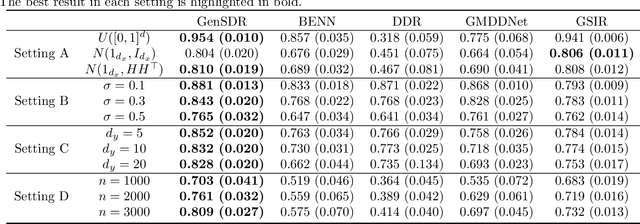
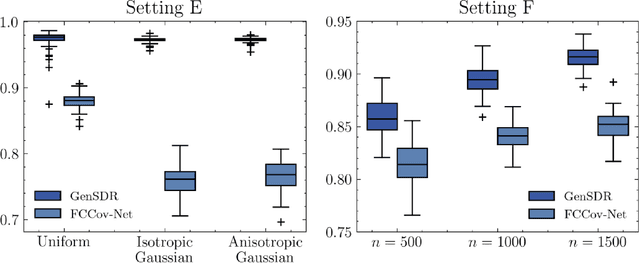
Identifying low-dimensional sufficient structures in nonlinear sufficient dimension reduction (SDR) has long been a fundamental yet challenging problem. Most existing methods lack theoretical guarantees of exhaustiveness in identifying lower dimensional structures, either at the population level or at the sample level. We tackle this issue by proposing a new method, generative sufficient dimension reduction (GenSDR), which leverages modern generative models. We show that GenSDR is able to fully recover the information contained in the central $σ$-field at both the population and sample levels. In particular, at the sample level, we establish a consistency property for the GenSDR estimator from the perspective of conditional distributions, capitalizing on the distributional learning capabilities of deep generative models. Moreover, by incorporating an ensemble technique, we extend GenSDR to accommodate scenarios with non-Euclidean responses, thereby substantially broadening its applicability. Extensive numerical results demonstrate the outstanding empirical performance of GenSDR and highlight its strong potential for addressing a wide range of complex, real-world tasks.