 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoWork-X: Experience-Optimized Co-Evolution for Multi-Agent Collaboration System
Feb 04, 2026Large language models are enabling language-conditioned agents in interactive environments, but highly cooperative tasks often impose two simultaneous constraints: sub-second real-time coordination and sustained multi-episode adaptation under a strict online token budget. Existing approaches either rely on frequent in-episode reasoning that induces latency and timing jitter, or deliver post-episode improvements through unstructured text that is difficult to compile into reliable low-cost execution. We propose CoWork-X, an active co-evolution framework that casts peer collaboration as a closed-loop optimization problem across episodes, inspired by fast--slow memory separation. CoWork-X instantiates a Skill-Agent that executes via HTN (hierarchical task network)-based skill retrieval from a structured, interpretable, and compositional skill library, and a post-episode Co-Optimizer that performs patch-style skill consolidation with explicit budget constraints and drift regularization. Experiments in challenging Overcooked-AI-like realtime collaboration benchmarks demonstrate that CoWork-X achieves stable, cumulative performance gains while steadily reducing online latency and token usage.
AlignDrive: Aligned Lateral-Longitudinal Planning for End-to-End Autonomous Driving
Jan 05, 2026End-to-end autonomous driving has rapidly progressed, enabling joint perception and planning in complex environments. In the planning stage, state-of-the-art (SOTA) end-to-end autonomous driving models decouple planning into parallel lateral and longitudinal predictions. While effective, this parallel design can lead to i) coordination failures between the planned path and speed, and ii) underutilization of the drive path as a prior for longitudinal planning, thus redundantly encoding static information. To address this, we propose a novel cascaded framework that explicitly conditions longitudinal planning on the drive path, enabling coordinated and collision-aware lateral and longitudinal planning. Specifically, we introduce a path-conditioned formulation that explicitly incorporates the drive path into longitudinal planning. Building on this, the model predicts longitudinal displacements along the drive path rather than full 2D trajectory waypoints. This design simplifies longitudinal reasoning and more tightly couples it with lateral planning. Additionally, we introduce a planning-oriented data augmentation strategy that simulates rare safety-critical events, such as vehicle cut-ins, by adding agents and relabeling longitudinal targets to avoid collision. Evaluated on the challenging Bench2Drive benchmark, our method sets a new SOTA, achieving a driving score of 89.07 and a success rate of 73.18%, demonstrating significantly improved coordination and safety
DepFlow: Disentangled Speech Generation to Mitigate Semantic Bias in Depression Detection
Jan 01, 2026Speech is a scalable and non-invasive biomarker for early mental health screening. However, widely used depression datasets like DAIC-WOZ exhibit strong coupling between linguistic sentiment and diagnostic labels, encouraging models to learn semantic shortcuts. As a result, model robustness may be compromised in real-world scenarios, such as Camouflaged Depression, where individuals maintain socially positive or neutral language despite underlying depressive states. To mitigate this semantic bias, we propose DepFlow, a three-stage depression-conditioned text-to-speech framework. First, a Depression Acoustic Encoder learns speaker- and content-invariant depression embeddings through adversarial training, achieving effective disentanglement while preserving depression discriminability (ROC-AUC: 0.693). Second, a flow-matching TTS model with FiLM modulation injects these embeddings into synthesis, enabling control over depressive severity while preserving content and speaker identity. Third, a prototype-based severity mapping mechanism provides smooth and interpretable manipulation across the depression continuum. Using DepFlow, we construct a Camouflage Depression-oriented Augmentation (CDoA) dataset that pairs depressed acoustic patterns with positive/neutral content from a sentiment-stratified text bank, creating acoustic-semantic mismatches underrepresented in natural data. Evaluated across three depression detection architectures, CDoA improves macro-F1 by 9%, 12%, and 5%, respectively, consistently outperforming conventional augmentation strategies in depression Detection. Beyond enhancing robustness, DepFlow provides a controllable synthesis platform for conversational systems and simulation-based evaluation, where real clinical data remains limited by ethical and coverage constraints.
OMG-Bench: A New Challenging Benchmark for Skeleton-based Online Micro Hand Gesture Recognition
Dec 18, 2025Online micro gesture recognition from hand skeletons is critical for VR/AR interaction but faces challenges due to limited public datasets and task-specific algorithms. Micro gestures involve subtle motion patterns, which make constructing datasets with precise skeletons and frame-level annotations difficult. To this end, we develop a multi-view self-supervised pipeline to automatically generate skeleton data, complemented by heuristic rules and expert refinement for semi-automatic annotation. Based on this pipeline, we introduce OMG-Bench, the first large-scale public benchmark for skeleton-based online micro gesture recognition. It features 40 fine-grained gesture classes with 13,948 instances across 1,272 sequences, characterized by subtle motions, rapid dynamics, and continuous execution. To tackle these challenges, we propose Hierarchical Memory-Augmented Transformer (HMATr), an end-to-end framework that unifies gesture detection and classification by leveraging hierarchical memory banks which store frame-level details and window-level semantics to preserve historical context. In addition, it employs learnable position-aware queries initialized from the memory to implicitly encode gesture positions and semantics. Experiments show that HMATr outperforms state-of-the-art methods by 7.6\% in detection rate, establishing a strong baseline for online micro gesture recognition. Project page: https://omg-bench.github.io/
Mind-Paced Speaking: A Dual-Brain Approach to Real-Time Reasoning in Spoken Language Models
Oct 10, 2025Real-time Spoken Language Models (SLMs) struggle to leverage Chain-of-Thought (CoT) reasoning due to the prohibitive latency of generating the entire thought process sequentially. Enabling SLMs to think while speaking, similar to humans, is attracting increasing attention. We present, for the first time, Mind-Paced Speaking (MPS), a brain-inspired framework that enables high-fidelity, real-time reasoning. Similar to how humans utilize distinct brain regions for thinking and responding, we propose a novel dual-brain approach, employing a "Formulation Brain" for high-level reasoning to pace and guide a separate "Articulation Brain" for fluent speech generation. This division of labor eliminates mode-switching, preserving the integrity of the reasoning process. Experiments show that MPS significantly outperforms existing think-while-speaking methods and achieves reasoning performance comparable to models that pre-compute the full CoT before speaking, while drastically reducing latency. Under a zero-latency configuration, the proposed method achieves an accuracy of 92.8% on the mathematical reasoning task Spoken-MQA and attains a score of 82.5 on the speech conversation task URO-Bench. Our work effectively bridges the gap between high-quality reasoning and real-time interaction.
Step-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
NTU Speechlab LLM-Based Multilingual ASR System for Interspeech MLC-SLM Challenge 2025
Jun 16, 2025This report details the NTU Speechlab system developed for the Interspeech 2025 Multilingual Conversational Speech and Language Model (MLC-SLM) Challenge (Task I), where we achieved 5th place. We present comprehensive analyses of our multilingual automatic speech recognition system, highlighting key advancements in model architecture, data selection, and training strategies. In particular, language-specific prompts and model averaging techniques were instrumental in boosting system performance across diverse languages. Compared to the initial baseline system, our final model reduced the average Mix Error Rate from 20.2% to 10.6%, representing an absolute improvement of 9.6% (a relative improvement of 48%) on the evaluation set. Our results demonstrate the effectiveness of our approach and offer practical insights for future Speech Large Language Models.
Cost-Efficient LLM Training with Lifetime-Aware Tensor Offloading via GPUDirect Storage
Jun 06, 2025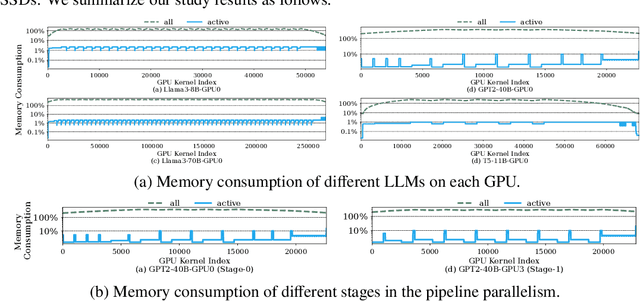

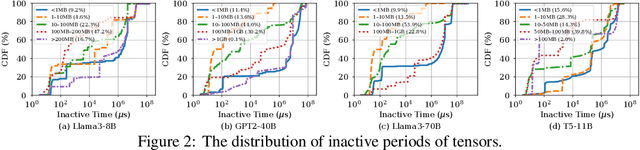

We present the design and implementation of a new lifetime-aware tensor offloading framework for GPU memory expansion using low-cost PCIe-based solid-state drives (SSDs). Our framework, TERAIO, is developed explicitly for large language model (LLM) training with multiple GPUs and multiple SSDs. Its design is driven by our observation that the active tensors take only a small fraction (1.7% on average) of allocated GPU memory in each LLM training iteration, the inactive tensors are usually large and will not be used for a long period of time, creating ample opportunities for offloading/prefetching tensors to/from slow SSDs without stalling the GPU training process. TERAIO accurately estimates the lifetime (active period of time in GPU memory) of each tensor with the profiling of the first few iterations in the training process. With the tensor lifetime analysis, TERAIO will generate an optimized tensor offloading/prefetching plan and integrate it into the compiled LLM program via PyTorch. TERAIO has a runtime tensor migration engine to execute the offloading/prefetching plan via GPUDirect storage, which allows direct tensor migration between GPUs and SSDs for alleviating the CPU bottleneck and maximizing the SSD bandwidth utilization. In comparison with state-of-the-art studies such as ZeRO-Offload and ZeRO-Infinity, we show that TERAIO improves the training performance of various LLMs by 1.47x on average, and achieves 80.7% of the ideal performance assuming unlimited GPU memory.
Generating Multimodal Driving Scenes via Next-Scene Prediction
Mar 19, 2025Generative models in Autonomous Driving (AD) enable diverse scene creation, yet existing methods fall short by only capturing a limited range of modalities, restricting the capability of generating controllable scenes for comprehensive evaluation of AD systems. In this paper, we introduce a multimodal generation framework that incorporates four major data modalities, including a novel addition of map modality. With tokenized modalities, our scene sequence generation framework autoregressively predicts each scene while managing computational demands through a two-stage approach. The Temporal AutoRegressive (TAR) component captures inter-frame dynamics for each modality while the Ordered AutoRegressive (OAR) component aligns modalities within each scene by sequentially predicting tokens in a fixed order. To maintain coherence between map and ego-action modalities, we introduce the Action-aware Map Alignment (AMA) module, which applies a transformation based on the ego-action to maintain coherence between these modalities. Our framework effectively generates complex, realistic driving scenes over extended sequences, ensuring multimodal consistency and offering fine-grained control over scene elements.
Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction
Feb 18, 2025Real-time speech interaction, serving as a fundamental interface for human-machine collaboration, holds immense potential. However, current open-source models face limitations such as high costs in voice data collection, weakness in dynamic control, and limited intelligence. To address these challenges, this paper introduces Step-Audio, the first production-ready open-source solution. Key contributions include: 1) a 130B-parameter unified speech-text multi-modal model that achieves unified understanding and generation, with the Step-Audio-Chat version open-sourced; 2) a generative speech data engine that establishes an affordable voice cloning framework and produces the open-sourced lightweight Step-Audio-TTS-3B model through distillation; 3) an instruction-driven fine control system enabling dynamic adjustments across dialects, emotions, singing, and RAP; 4) an enhanced cognitive architecture augmented with tool calling and role-playing abilities to manage complex tasks effectively. Based on our new StepEval-Audio-360 evaluation benchmark, Step-Audio achieves state-of-the-art performance in human evaluations, especially in terms of instruction following. On open-source benchmarks like LLaMA Question, shows 9.3% average performance improvement, demonstrating our commitment to advancing the development of open-source multi-modal language technologies. Our code and models are available at https://github.com/stepfun-ai/Step-Audio.