 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Principles to Applications: A Comprehensive Survey of Discrete Tokenizers in Generation, Comprehension, Recommendation, and Information Retrieval
Feb 18, 2025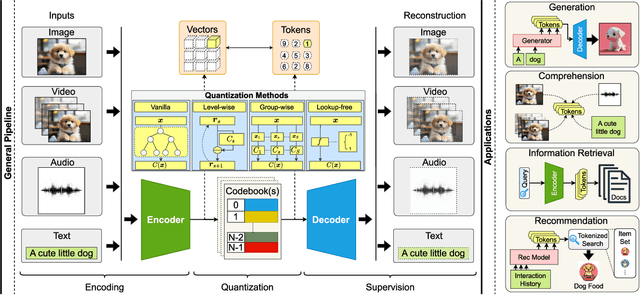
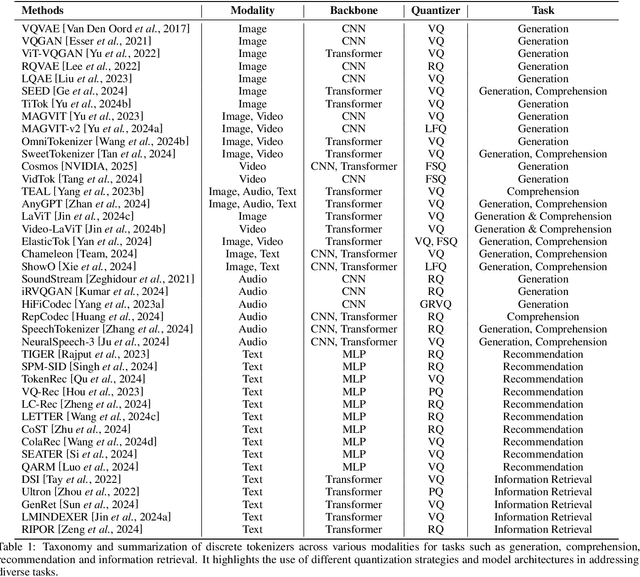
Discrete tokenizers have emerged as indispensable components in modern machine learning systems, particularly within the context of autoregressive modeling and large language models (LLMs). These tokenizers serve as the critical interface that transforms raw, unstructured data from diverse modalities into discrete tokens, enabling LLMs to operate effectively across a wide range of tasks. Despite their central role in generation, comprehension, and recommendation systems, a comprehensive survey dedicated to discrete tokenizers remains conspicuously absent in the literature. This paper addresses this gap by providing a systematic review of the design principles, applications, and challenges of discrete tokenizers. We begin by dissecting the sub-modules of tokenizers and systematically demonstrate their internal mechanisms to provide a comprehensive understanding of their functionality and design. Building on this foundation, we synthesize state-of-the-art methods, categorizing them into multimodal generation and comprehension tasks, and semantic tokens for personalized recommendations. Furthermore, we critically analyze the limitations of existing tokenizers and outline promising directions for future research. By presenting a unified framework for understanding discrete tokenizers, this survey aims to guide researchers and practitioners in addressing open challenges and advancing the field, ultimately contributing to the development of more robust and versatile AI systems.
SweetTokenizer: Semantic-Aware Spatial-Temporal Tokenizer for Compact Visual Discretization
Dec 17, 2024



This paper presents the \textbf{S}emantic-a\textbf{W}ar\textbf{E} spatial-t\textbf{E}mporal \textbf{T}okenizer (SweetTokenizer), a compact yet effective discretization approach for vision data. Our goal is to boost tokenizers' compression ratio while maintaining reconstruction fidelity in the VQ-VAE paradigm. Firstly, to obtain compact latent representations, we decouple images or videos into spatial-temporal dimensions, translating visual information into learnable querying spatial and temporal tokens through a \textbf{C}ross-attention \textbf{Q}uery \textbf{A}uto\textbf{E}ncoder (CQAE). Secondly, to complement visual information during compression, we quantize these tokens via a specialized codebook derived from off-the-shelf LLM embeddings to leverage the rich semantics from language modality. Finally, to enhance training stability and convergence, we also introduce a curriculum learning strategy, which proves critical for effective discrete visual representation learning. SweetTokenizer achieves comparable video reconstruction fidelity with only \textbf{25\%} of the tokens used in previous state-of-the-art video tokenizers, and boost video generation results by \textbf{32.9\%} w.r.t gFVD. When using the same token number, we significantly improves video and image reconstruction results by \textbf{57.1\%} w.r.t rFVD on UCF-101 and \textbf{37.2\%} w.r.t rFID on ImageNet-1K. Additionally, the compressed tokens are imbued with semantic information, enabling few-shot recognition capabilities powered by LLMs in downstream applications.
Orthus: Autoregressive Interleaved Image-Text Generation with Modality-Specific Heads
Nov 28, 2024
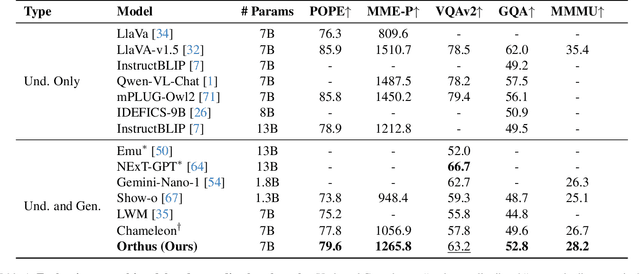
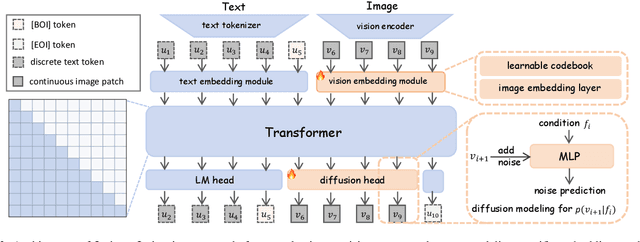
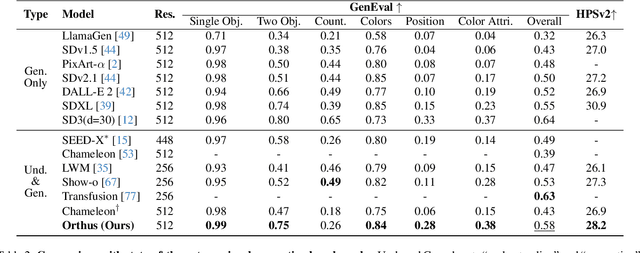
We introduce Orthus, an autoregressive (AR) transformer that excels in generating images given textual prompts, answering questions based on visual inputs, and even crafting lengthy image-text interleaved contents. Unlike prior arts on unified multimodal modeling, Orthus simultaneously copes with discrete text tokens and continuous image features under the AR modeling principle. The continuous treatment of visual signals minimizes the information loss for both image understanding and generation while the fully AR formulation renders the characterization of the correlation between modalities straightforward. The key mechanism enabling Orthus to leverage these advantages lies in its modality-specific heads -- one regular language modeling (LM) head predicts discrete text tokens and one diffusion head generates continuous image features conditioning on the output of the backbone. We devise an efficient strategy for building Orthus -- by substituting the Vector Quantization (VQ) operation in the existing unified AR model with a soft alternative, introducing a diffusion head, and tuning the added modules to reconstruct images, we can create an Orthus-base model effortlessly (e.g., within mere 72 A100 GPU hours). Orthus-base can further embrace post-training to better model interleaved images and texts. Empirically, Orthus surpasses competing baselines including Show-o and Chameleon across standard benchmarks, achieving a GenEval score of 0.58 and an MME-P score of 1265.8 using 7B parameters. Orthus also shows exceptional mixed-modality generation capabilities, reflecting the potential for handling intricate practical generation tasks.
Enhancing Instruction-Following Capability of Visual-Language Models by Reducing Image Redundancy
Nov 23, 2024


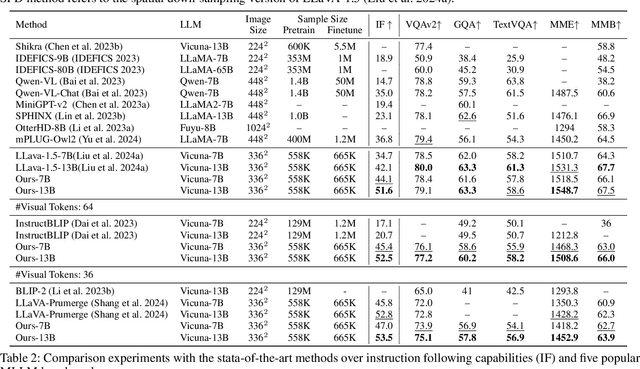
Large Language Models (LLMs) have strong instruction-following capability to interpret and execute tasks as directed by human commands. Multimodal Large Language Models (MLLMs) have inferior instruction-following ability compared to LLMs. However, there is a significant gap in the instruction-following capabilities between the MLLMs and LLMs. In this study, we conduct a pilot experiment, which demonstrates that spatially down-sampling visual tokens significantly enhances the instruction-following capability of MLLMs. This is attributed to the substantial redundancy in visual modality. However, this intuitive method severely impairs the MLLM's multimodal understanding capability. In this paper, we propose Visual-Modality Token Compression (VMTC) and Cross-Modality Attention Inhibition (CMAI) strategies to alleviate this gap between MLLMs and LLMs by inhibiting the influence of irrelevant visual tokens during content generation, increasing the instruction-following ability of the MLLMs while retaining their multimodal understanding capacity. In VMTC module, the primary tokens are retained and the redundant tokens are condensed by token clustering and merging. In CMAI process, we aggregate text-to-image attentions by text-to-text attentions to obtain a text-to-image focus score. Attention inhibition is performed on the text-image token pairs with low scores. Our comprehensive experiments over instruction-following capabilities and VQA-V2, GQA, TextVQA, MME and MMBench five benchmarks, demonstrate that proposed strategy significantly enhances the instruction following capability of MLLMs while preserving the ability to understand and process multimodal inputs.
ASR-enhanced Multimodal Representation Learning for Cross-Domain Product Retrieval
Aug 06, 2024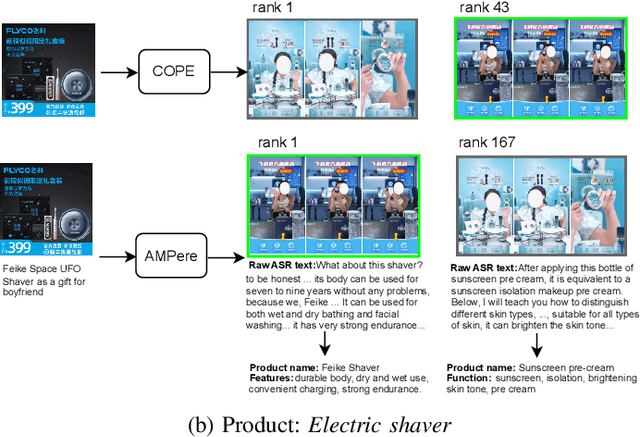
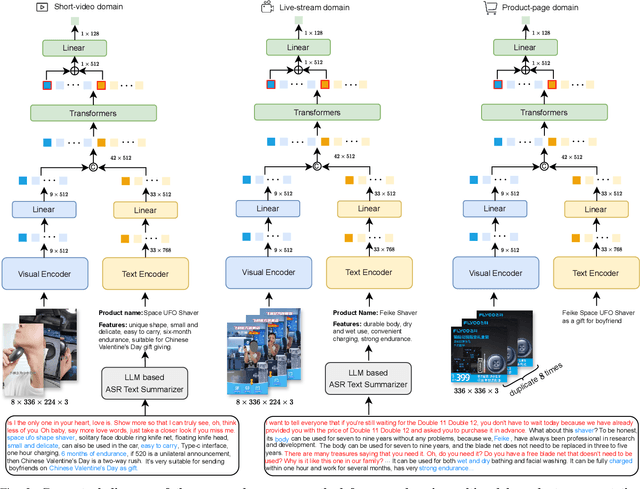

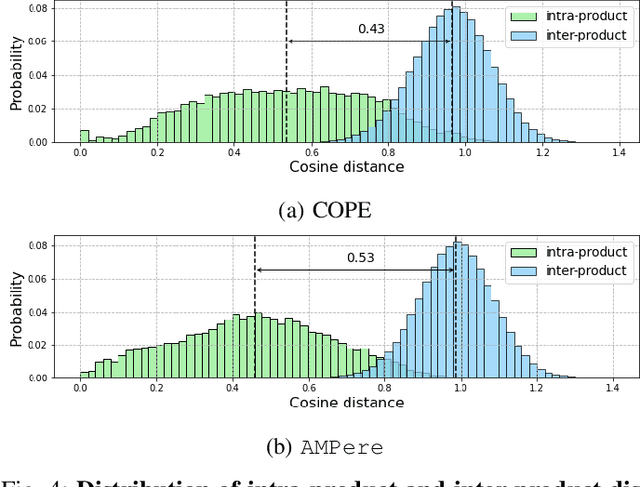
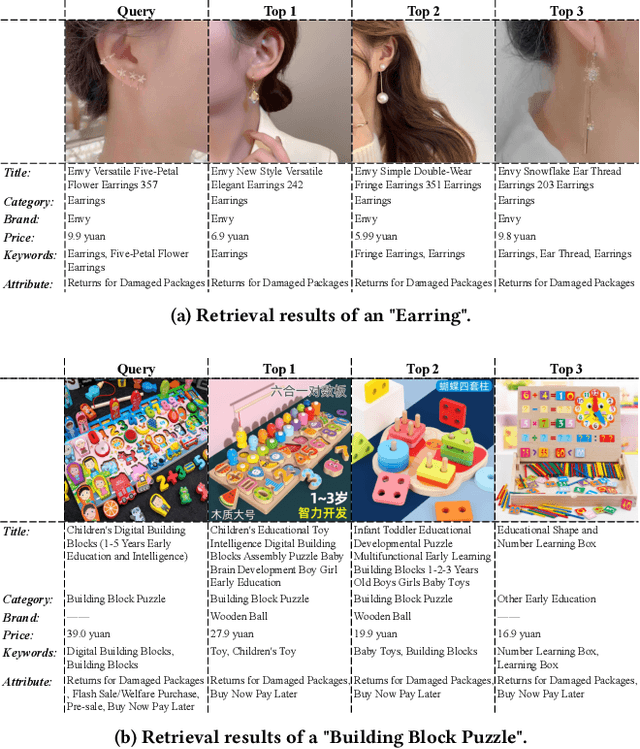
E-commerce is increasingly multimedia-enriched, with products exhibited in a broad-domain manner as images, short videos, or live stream promotions. A unified and vectorized cross-domain production representation is essential. Due to large intra-product variance and high inter-product similarity in the broad-domain scenario, a visual-only representation is inadequate. While Automatic Speech Recognition (ASR) text derived from the short or live-stream videos is readily accessible, how to de-noise the excessively noisy text for multimodal representation learning is mostly untouched. We propose ASR-enhanced Multimodal Product Representation Learning (AMPere). In order to extract product-specific information from the raw ASR text, AMPere uses an easy-to-implement LLM-based ASR text summarizer. The LLM-summarized text, together with visual data, is then fed into a multi-branch network to generate compact multimodal embeddings. Extensive experiments on a large-scale tri-domain dataset verify the effectiveness of AMPere in obtaining a unified multimodal product representation that clearly improves cross-domain product retrieval.
Knowledge Adaptation from Large Language Model to Recommendation for Practical Industrial Application
May 07, 2024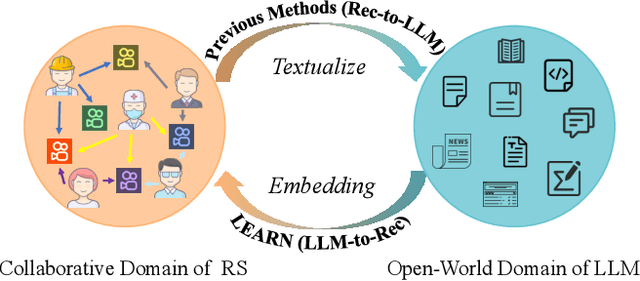


Contemporary recommender systems predominantly rely on collaborative filtering techniques, employing ID-embedding to capture latent associations among users and items. However, this approach overlooks the wealth of semantic information embedded within textual descriptions of items, leading to suboptimal performance in cold-start scenarios and long-tail user recommendations. Leveraging the capabilities of Large Language Models (LLMs) pretrained on massive text corpus presents a promising avenue for enhancing recommender systems by integrating open-world domain knowledge. In this paper, we propose an Llm-driven knowlEdge Adaptive RecommeNdation (LEARN) framework that synergizes open-world knowledge with collaborative knowledge. We address computational complexity concerns by utilizing pretrained LLMs as item encoders and freezing LLM parameters to avoid catastrophic forgetting and preserve open-world knowledge. To bridge the gap between the open-world and collaborative domains, we design a twin-tower structure supervised by the recommendation task and tailored for practical industrial application. Through offline experiments on the large-scale industrial dataset and online experiments on A/B tests, we demonstrate the efficacy of our approach.
Knowledge Condensation and Reasoning for Knowledge-based VQA
Mar 15, 2024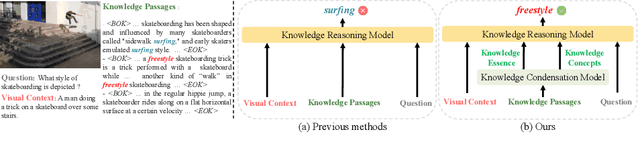
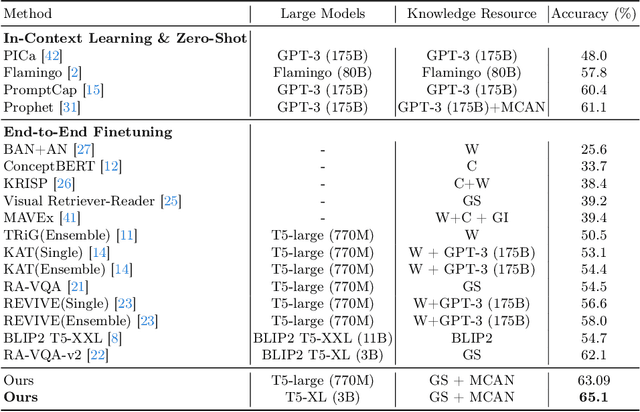
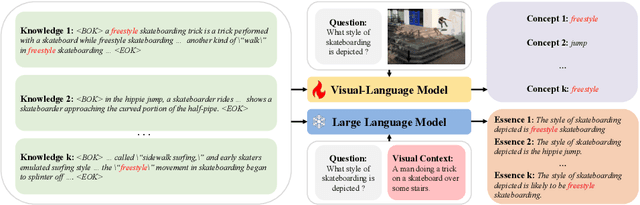
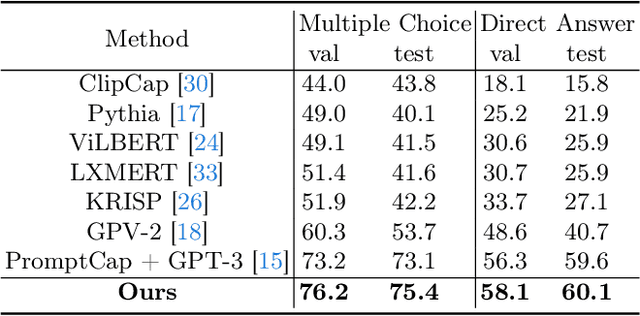
Knowledge-based visual question answering (KB-VQA) is a challenging task, which requires the model to leverage external knowledge for comprehending and answering questions grounded in visual content. Recent studies retrieve the knowledge passages from external knowledge bases and then use them to answer questions. However, these retrieved knowledge passages often contain irrelevant or noisy information, which limits the performance of the model. To address the challenge, we propose two synergistic models: Knowledge Condensation model and Knowledge Reasoning model. We condense the retrieved knowledge passages from two perspectives. First, we leverage the multimodal perception and reasoning ability of the visual-language models to distill concise knowledge concepts from retrieved lengthy passages, ensuring relevance to both the visual content and the question. Second, we leverage the text comprehension ability of the large language models to summarize and condense the passages into the knowledge essence which helps answer the question. These two types of condensed knowledge are then seamlessly integrated into our Knowledge Reasoning model, which judiciously navigates through the amalgamated information to arrive at the conclusive answer. Extensive experiments validate the superiority of the proposed method. Compared to previous methods, our method achieves state-of-the-art performance on knowledge-based VQA datasets (65.1% on OK-VQA and 60.1% on A-OKVQA) without resorting to the knowledge produced by GPT-3 (175B).
Beyond Appearance: a Semantic Controllable Self-Supervised Learning Framework for Human-Centric Visual Tasks
Mar 30, 2023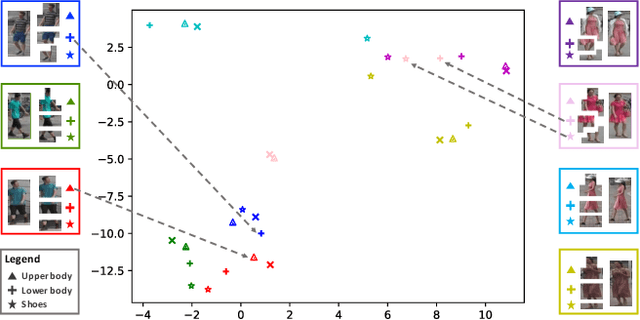
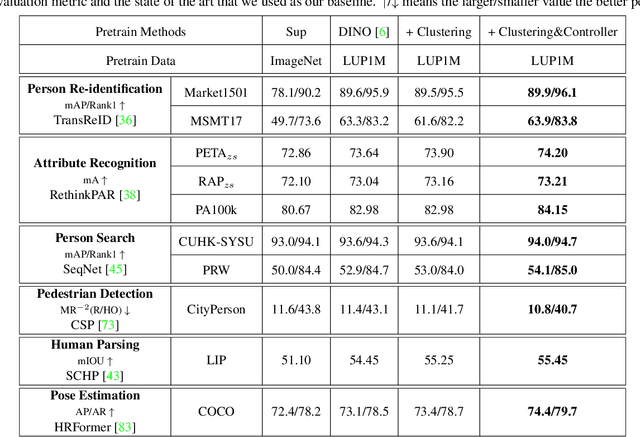
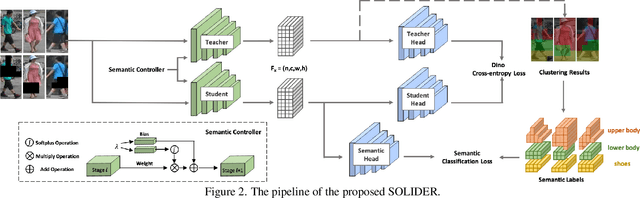
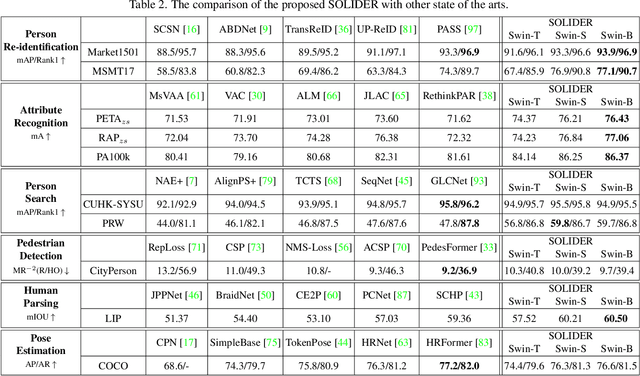
Human-centric visual tasks have attracted increasing research attention due to their widespread applications. In this paper, we aim to learn a general human representation from massive unlabeled human images which can benefit downstream human-centric tasks to the maximum extent. We call this method SOLIDER, a Semantic cOntrollable seLf-supervIseD lEaRning framework. Unlike the existing self-supervised learning methods, prior knowledge from human images is utilized in SOLIDER to build pseudo semantic labels and import more semantic information into the learned representation. Meanwhile, we note that different downstream tasks always require different ratios of semantic information and appearance information. For example, human parsing requires more semantic information, while person re-identification needs more appearance information for identification purpose. So a single learned representation cannot fit for all requirements. To solve this problem, SOLIDER introduces a conditional network with a semantic controller. After the model is trained, users can send values to the controller to produce representations with different ratios of semantic information, which can fit different needs of downstream tasks. Finally, SOLIDER is verified on six downstream human-centric visual tasks. It outperforms state of the arts and builds new baselines for these tasks. The code is released in https://github.com/tinyvision/SOLIDER.
InsPro: Propagating Instance Query and Proposal for Online Video Instance Segmentation
Jan 05, 2023Video instance segmentation (VIS) aims at segmenting and tracking objects in videos. Prior methods typically generate frame-level or clip-level object instances first and then associate them by either additional tracking heads or complex instance matching algorithms. This explicit instance association approach increases system complexity and fails to fully exploit temporal cues in videos. In this paper, we design a simple, fast and yet effective query-based framework for online VIS. Relying on an instance query and proposal propagation mechanism with several specially developed components, this framework can perform accurate instance association implicitly. Specifically, we generate frame-level object instances based on a set of instance query-proposal pairs propagated from previous frames. This instance query-proposal pair is learned to bind with one specific object across frames through conscientiously developed strategies. When using such a pair to predict an object instance on the current frame, not only the generated instance is automatically associated with its precursors on previous frames, but the model gets a good prior for predicting the same object. In this way, we naturally achieve implicit instance association in parallel with segmentation and elegantly take advantage of temporal clues in videos. To show the effectiveness of our method InsPro, we evaluate it on two popular VIS benchmarks, i.e., YouTube-VIS 2019 and YouTube-VIS 2021. Without bells-and-whistles, our InsPro with ResNet-50 backbone achieves 43.2 AP and 37.6 AP on these two benchmarks respectively, outperforming all other online VIS methods.
Learning Disentangled Label Representations for Multi-label Classification
Dec 02, 2022
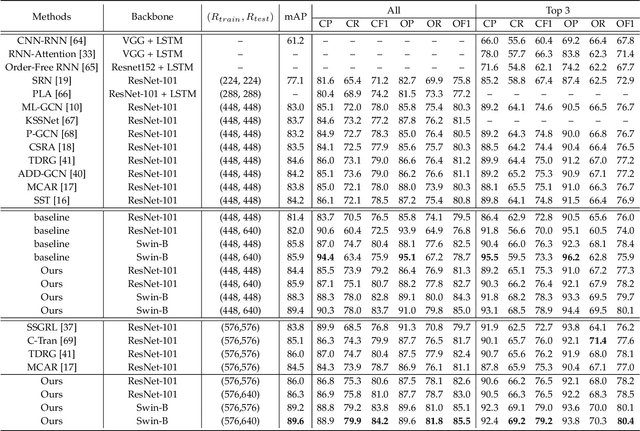
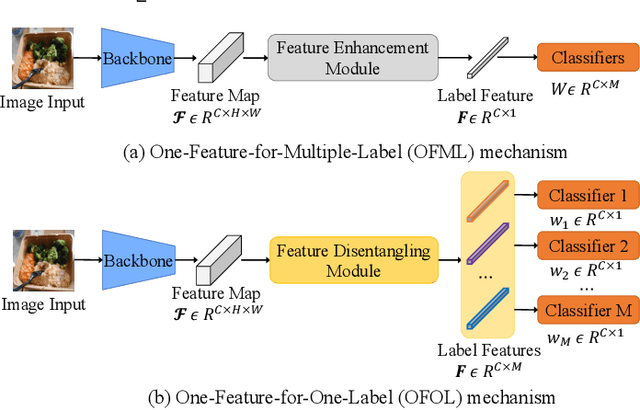
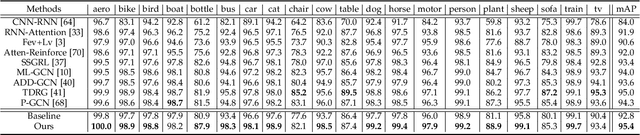
Although various methods have been proposed for multi-label classification, most approaches still follow the feature learning mechanism of the single-label (multi-class) classification, namely, learning a shared image feature to classify multiple labels. However, we find this One-shared-Feature-for-Multiple-Labels (OFML) mechanism is not conducive to learning discriminative label features and makes the model non-robustness. For the first time, we mathematically prove that the inferiority of the OFML mechanism is that the optimal learned image feature cannot maintain high similarities with multiple classifiers simultaneously in the context of minimizing cross-entropy loss. To address the limitations of the OFML mechanism, we introduce the One-specific-Feature-for-One-Label (OFOL) mechanism and propose a novel disentangled label feature learning (DLFL) framework to learn a disentangled representation for each label. The specificity of the framework lies in a feature disentangle module, which contains learnable semantic queries and a Semantic Spatial Cross-Attention (SSCA) module. Specifically, learnable semantic queries maintain semantic consistency between different images of the same label. The SSCA module localizes the label-related spatial regions and aggregates located region features into the corresponding label feature to achieve feature disentanglement. We achieve state-of-the-art performance on eight datasets of three tasks, \ie, multi-label classification, pedestrian attribute recognition, and continual multi-label learning.