 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVS-LLM: Visual-Semantic Depression Assessment based on LLM for Drawing Projection Test
Aug 07, 2025The Drawing Projection Test (DPT) is an essential tool in art therapy, allowing psychologists to assess participants' mental states through their sketches. Specifically, through sketches with the theme of "a person picking an apple from a tree (PPAT)", it can be revealed whether the participants are in mental states such as depression. Compared with scales, the DPT can enrich psychologists' understanding of an individual's mental state. However, the interpretation of the PPAT is laborious and depends on the experience of the psychologists. To address this issue, we propose an effective identification method to support psychologists in conducting a large-scale automatic DPT. Unlike traditional sketch recognition, DPT more focus on the overall evaluation of the sketches, such as color usage and space utilization. Moreover, PPAT imposes a time limit and prohibits verbal reminders, resulting in low drawing accuracy and a lack of detailed depiction. To address these challenges, we propose the following efforts: (1) Providing an experimental environment for automated analysis of PPAT sketches for depression assessment; (2) Offering a Visual-Semantic depression assessment based on LLM (VS-LLM) method; (3) Experimental results demonstrate that our method improves by 17.6% compared to the psychologist assessment method. We anticipate that this work will contribute to the research in mental state assessment based on PPAT sketches' elements recognition. Our datasets and codes are available at https://github.com/wmeiqi/VS-LLM.
See Your Heart: Psychological states Interpretation through Visual Creations
Feb 11, 2023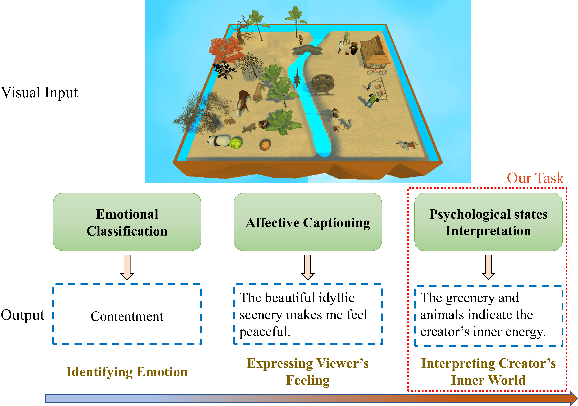

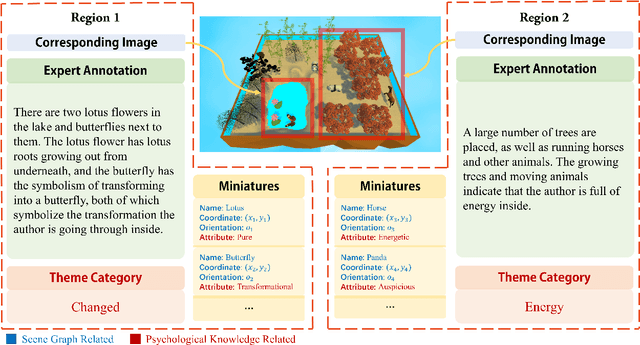

In psychoanalysis, generating interpretations to one's psychological state through visual creations is facing significant demands. The two main tasks of existing studies in the field of computer vision, sentiment/emotion classification and affective captioning, can hardly satisfy the requirement of psychological interpreting. To meet the demands for psychoanalysis, we introduce a challenging task, \textbf{V}isual \textbf{E}motion \textbf{I}nterpretation \textbf{T}ask (VEIT). VEIT requires AI to generate reasonable interpretations of creator's psychological state through visual creations. To support the task, we present a multimodal dataset termed SpyIn (\textbf{S}and\textbf{p}la\textbf{y} \textbf{In}terpretation Dataset), which is psychological theory supported and professional annotated. Dataset analysis illustrates that SpyIn is not only able to support VEIT, but also more challenging compared with other captioning datasets. Building on SpyIn, we conduct experiments of several image captioning method, and propose a visual-semantic combined model which obtains a SOTA result on SpyIn. The results indicate that VEIT is a more challenging task requiring scene graph information and psychological knowledge. Our work also show a promise for AI to analyze and explain inner world of humanity through visual creations.
Learning Disentangled Label Representations for Multi-label Classification
Dec 02, 2022
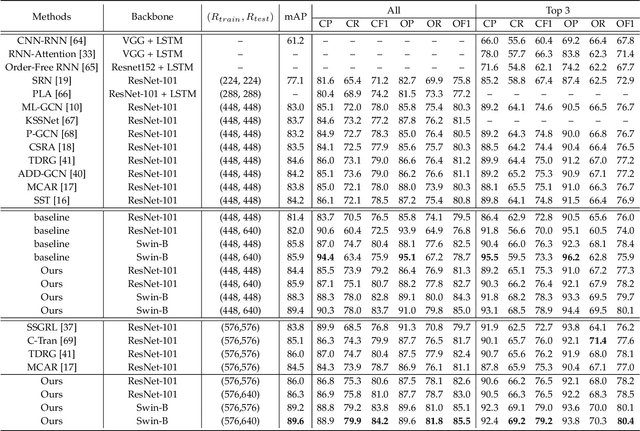
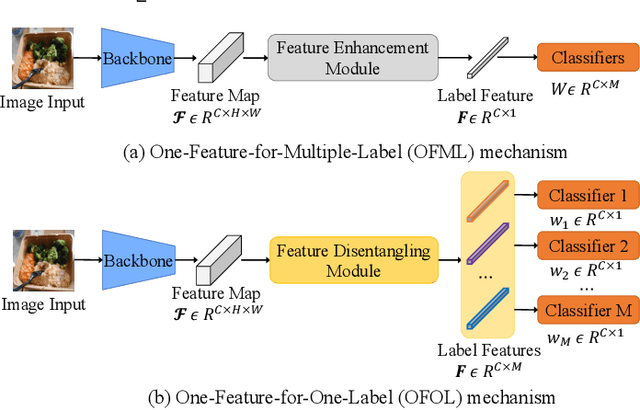
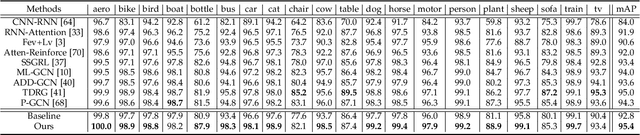
Although various methods have been proposed for multi-label classification, most approaches still follow the feature learning mechanism of the single-label (multi-class) classification, namely, learning a shared image feature to classify multiple labels. However, we find this One-shared-Feature-for-Multiple-Labels (OFML) mechanism is not conducive to learning discriminative label features and makes the model non-robustness. For the first time, we mathematically prove that the inferiority of the OFML mechanism is that the optimal learned image feature cannot maintain high similarities with multiple classifiers simultaneously in the context of minimizing cross-entropy loss. To address the limitations of the OFML mechanism, we introduce the One-specific-Feature-for-One-Label (OFOL) mechanism and propose a novel disentangled label feature learning (DLFL) framework to learn a disentangled representation for each label. The specificity of the framework lies in a feature disentangle module, which contains learnable semantic queries and a Semantic Spatial Cross-Attention (SSCA) module. Specifically, learnable semantic queries maintain semantic consistency between different images of the same label. The SSCA module localizes the label-related spatial regions and aggregates located region features into the corresponding label feature to achieve feature disentanglement. We achieve state-of-the-art performance on eight datasets of three tasks, \ie, multi-label classification, pedestrian attribute recognition, and continual multi-label learning.
A Split Semantic Detection Algorithm for Psychological Sandplay Image
Mar 02, 2022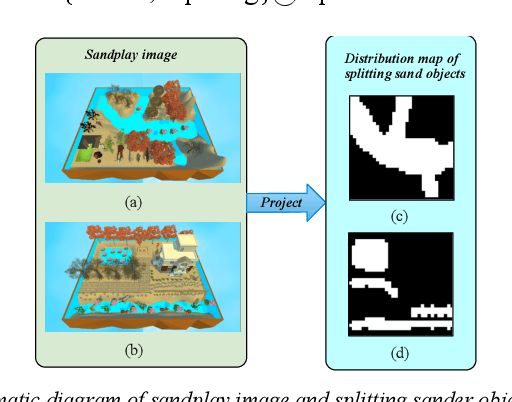

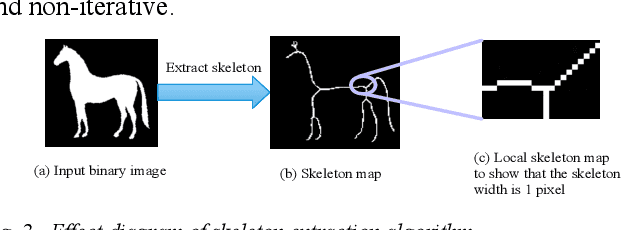

Psychological sandplay, as an important psychological analysis tool, is a visual scene constructed by the tester selecting and placing sand objects (e.g., sand, river, human figures, animals, vegetation, buildings, etc.). As the projection of the tester's inner world, it contains high-level semantic information reflecting the tester's thoughts and feelings. Most of the existing computer vision technologies focus on the objective basic semantics (e.g., object's name, attribute, boundingbox, etc.) in the natural image, while few related works pay attention to the subjective psychological semantics (e.g., emotion, thoughts, feelings, etc.) in the artificial image. We take the latter semantics as the research object, take "split" (a common psychological semantics reflecting the inner integration of testers) as the research goal, and use the method of machine learning to realize the automatic detection of split semantics, so as to explore the application of machine learning in the detection of subjective psychological semantics of sandplay images. To this end, we present a feature dimensionality reduction and extraction algorithm to obtain a one-dimensional vector representing the split feature, and build the split semantic detector based on Multilayer Perceptron network to get the detection results. Experimental results on the real sandplay datasets show the effectiveness of our proposed algorithm.
Spatial and Semantic Consistency Regularizations for Pedestrian Attribute Recognition
Sep 13, 2021
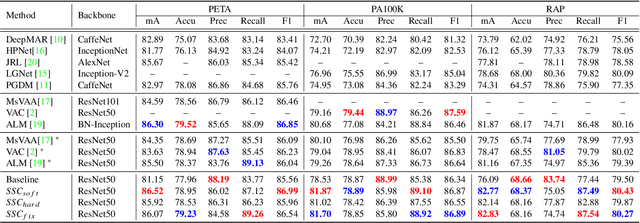
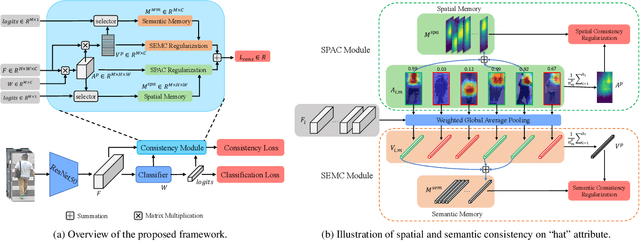

While recent studies on pedestrian attribute recognition have shown remarkable progress in leveraging complicated networks and attention mechanisms, most of them neglect the inter-image relations and an important prior: spatial consistency and semantic consistency of attributes under surveillance scenarios. The spatial locations of the same attribute should be consistent between different pedestrian images, \eg, the ``hat" attribute and the ``boots" attribute are always located at the top and bottom of the picture respectively. In addition, the inherent semantic feature of the ``hat" attribute should be consistent, whether it is a baseball cap, beret, or helmet. To fully exploit inter-image relations and aggregate human prior in the model learning process, we construct a Spatial and Semantic Consistency (SSC) framework that consists of two complementary regularizations to achieve spatial and semantic consistency for each attribute. Specifically, we first propose a spatial consistency regularization to focus on reliable and stable attribute-related regions. Based on the precise attribute locations, we further propose a semantic consistency regularization to extract intrinsic and discriminative semantic features. We conduct extensive experiments on popular benchmarks including PA100K, RAP, and PETA. Results show that the proposed method performs favorably against state-of-the-art methods without increasing parameters.
Rethinking of Pedestrian Attribute Recognition: A Reliable Evaluation under Zero-Shot Pedestrian Identity Setting
Jul 08, 2021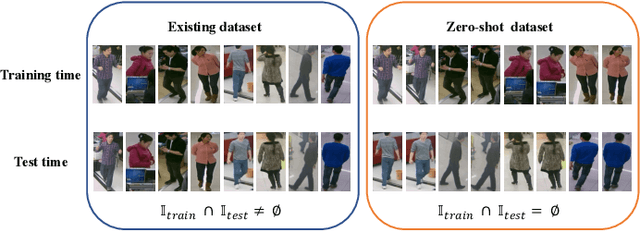


Pedestrian attribute recognition aims to assign multiple attributes to one pedestrian image captured by a video surveillance camera. Although numerous methods are proposed and make tremendous progress, we argue that it is time to step back and analyze the status quo of the area. We review and rethink the recent progress from three perspectives. First, given that there is no explicit and complete definition of pedestrian attribute recognition, we formally define and distinguish pedestrian attribute recognition from other similar tasks. Second, based on the proposed definition, we expose the limitations of the existing datasets, which violate the academic norm and are inconsistent with the essential requirement of practical industry application. Thus, we propose two datasets, PETA\textsubscript{$ZS$} and RAP\textsubscript{$ZS$}, constructed following the zero-shot settings on pedestrian identity. In addition, we also introduce several realistic criteria for future pedestrian attribute dataset construction. Finally, we reimplement existing state-of-the-art methods and introduce a strong baseline method to give reliable evaluations and fair comparisons. Experiments are conducted on four existing datasets and two proposed datasets to measure progress on pedestrian attribute recognition.
Rethinking of Pedestrian Attribute Recognition: Realistic Datasets with Efficient Method
May 26, 2020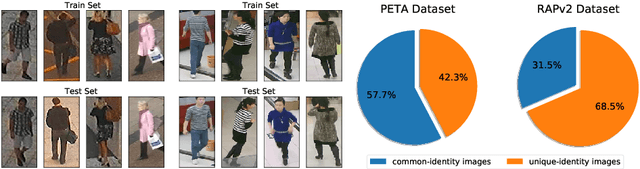
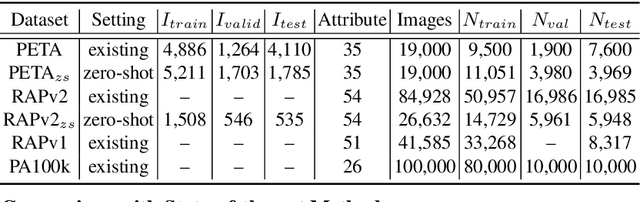
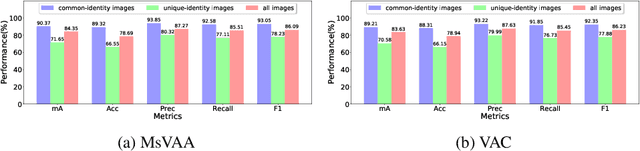
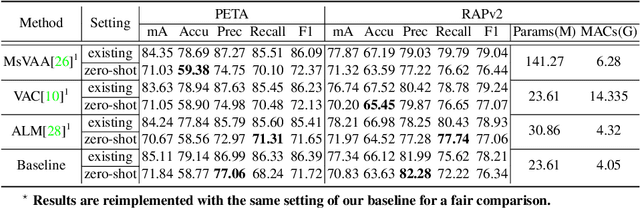
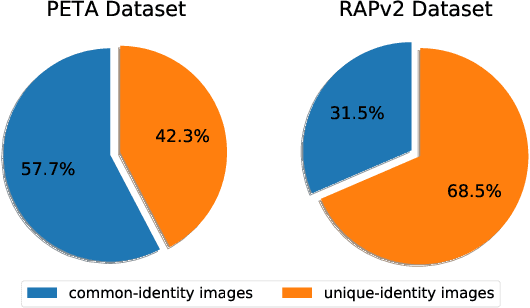
Despite various methods are proposed to make progress in pedestrian attribute recognition, a crucial problem on existing datasets is often neglected, namely, a large number of identical pedestrian identities in train and test set, which is not consistent with practical application. Thus, images of the same pedestrian identity in train set and test set are extremely similar, leading to overestimated performance of state-of-the-art methods on existing datasets. To address this problem, we propose two realistic datasets PETA\textsubscript{$zs$} and RAPv2\textsubscript{$zs$} following zero-shot setting of pedestrian identities based on PETA and RAPv2 datasets. Furthermore, compared to our strong baseline method, we have observed that recent state-of-the-art methods can not make performance improvement on PETA, RAPv2, PETA\textsubscript{$zs$} and RAPv2\textsubscript{$zs$}. Thus, through solving the inherent attribute imbalance in pedestrian attribute recognition, an efficient method is proposed to further improve the performance. Experiments on existing and proposed datasets verify the superiority of our method by achieving state-of-the-art performance.
EANet: Enhancing Alignment for Cross-Domain Person Re-identification
Dec 29, 2018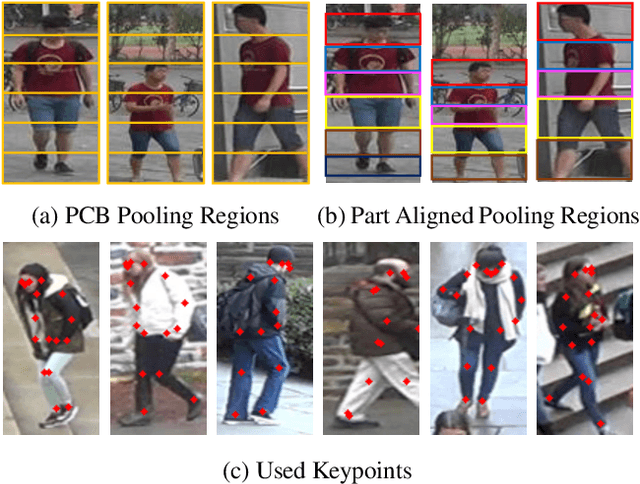

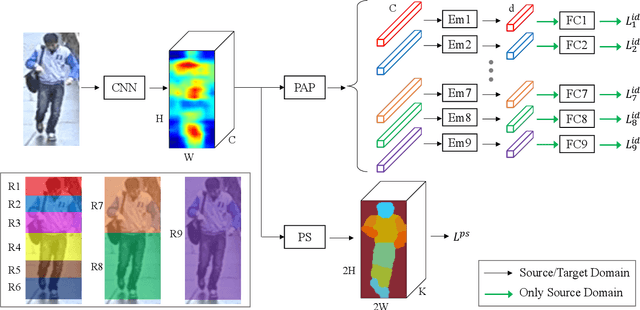

Person re-identification (ReID) has achieved significant improvement under the single-domain setting. However, directly exploiting a model to new domains is always faced with huge performance drop, and adapting the model to new domains without target-domain identity labels is still challenging. In this paper, we address cross-domain ReID and make contributions for both model generalization and adaptation. First, we propose Part Aligned Pooling (PAP) that brings significant improvement for cross-domain testing. Second, we design a Part Segmentation (PS) constraint over ReID feature to enhance alignment and improve model generalization. Finally, we show that applying our PS constraint to unlabeled target domain images serves as effective domain adaptation. We conduct extensive experiments between three large datasets, Market1501, CUHK03 and DukeMTMC-reID. Our model achieves state-of-the-art performance under both source-domain and cross-domain settings. For completeness, we also demonstrate the complementarity of our model to existing domain adaptation methods. The code is available at https://github.com/huanghoujing/EANet.
Learning Deep Context-aware Features over Body and Latent Parts for Person Re-identification
Oct 18, 2017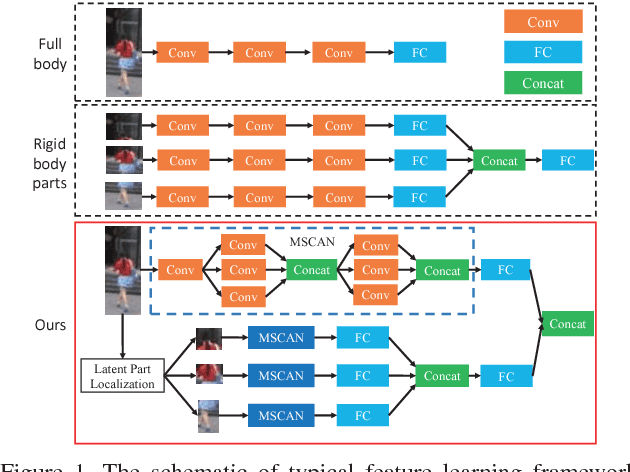
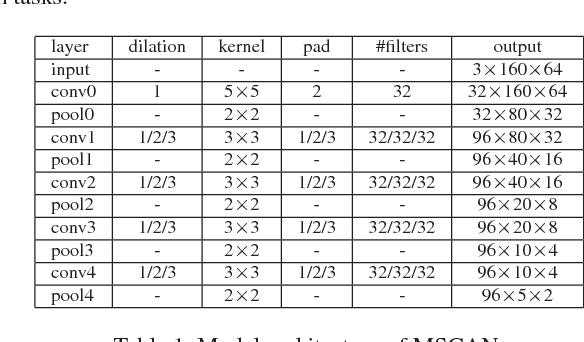
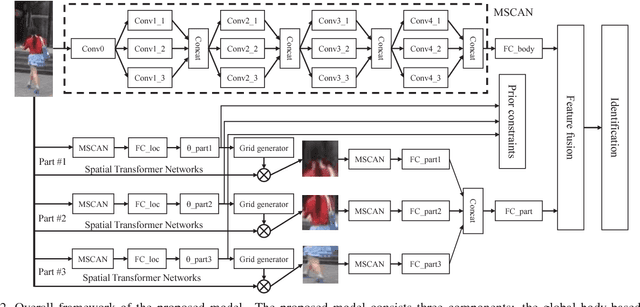
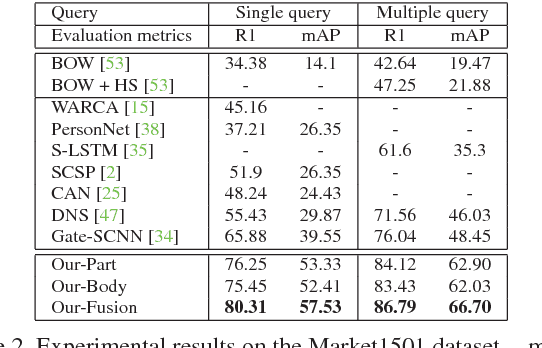
Person Re-identification (ReID) is to identify the same person across different cameras. It is a challenging task due to the large variations in person pose, occlusion, background clutter, etc How to extract powerful features is a fundamental problem in ReID and is still an open problem today. In this paper, we design a Multi-Scale Context-Aware Network (MSCAN) to learn powerful features over full body and body parts, which can well capture the local context knowledge by stacking multi-scale convolutions in each layer. Moreover, instead of using predefined rigid parts, we propose to learn and localize deformable pedestrian parts using Spatial Transformer Networks (STN) with novel spatial constraints. The learned body parts can release some difficulties, eg pose variations and background clutters, in part-based representation. Finally, we integrate the representation learning processes of full body and body parts into a unified framework for person ReID through multi-class person identification tasks. Extensive evaluations on current challenging large-scale person ReID datasets, including the image-based Market1501, CUHK03 and sequence-based MARS datasets, show that the proposed method achieves the state-of-the-art results.
Beyond triplet loss: a deep quadruplet network for person re-identification
Apr 06, 2017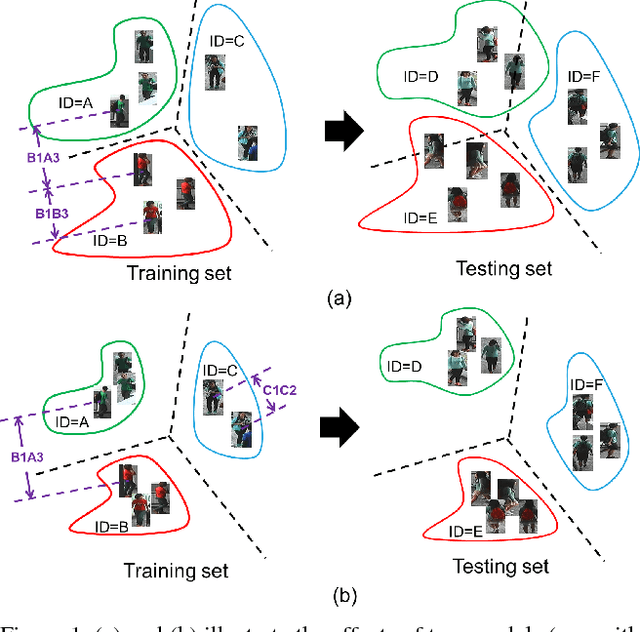
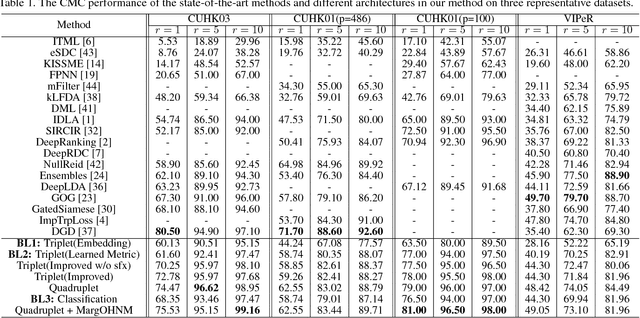
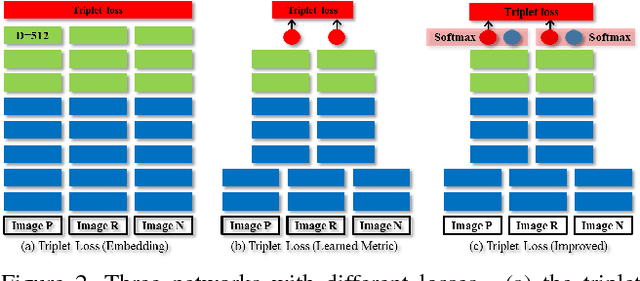
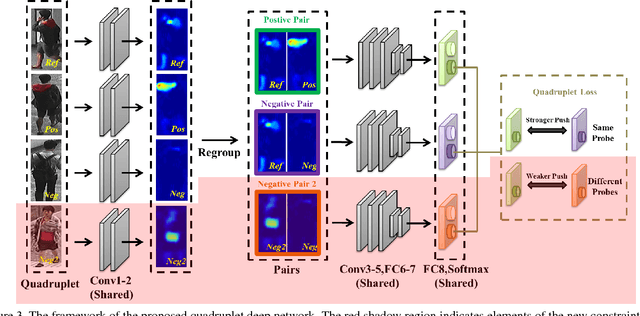
Person re-identification (ReID) is an important task in wide area video surveillance which focuses on identifying people across different cameras. Recently, deep learning networks with a triplet loss become a common framework for person ReID. However, the triplet loss pays main attentions on obtaining correct orders on the training set. It still suffers from a weaker generalization capability from the training set to the testing set, thus resulting in inferior performance. In this paper, we design a quadruplet loss, which can lead to the model output with a larger inter-class variation and a smaller intra-class variation compared to the triplet loss. As a result, our model has a better generalization ability and can achieve a higher performance on the testing set. In particular, a quadruplet deep network using a margin-based online hard negative mining is proposed based on the quadruplet loss for the person ReID. In extensive experiments, the proposed network outperforms most of the state-of-the-art algorithms on representative datasets which clearly demonstrates the effectiveness of our proposed method.