 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Learning with Side Information for Noisy Labeled Images
Sep 04, 2020
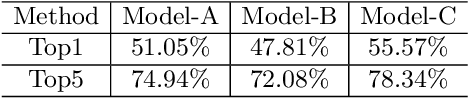
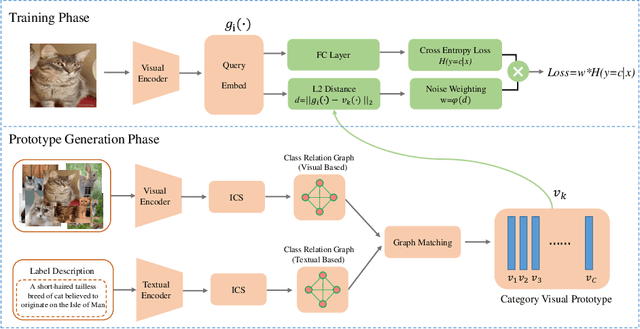

In many real-world datasets, like WebVision, the performance of DNN based classifier is often limited by the noisy labeled data. To tackle this problem, some image related side information, such as captions and tags, often reveal underlying relationships across images. In this paper, we present an efficient weakly supervised learning by using a Side Information Network (SINet), which aims to effectively carry out a large scale classification with severely noisy labels. The proposed SINet consists of a visual prototype module and a noise weighting module. The visual prototype module is designed to generate a compact representation for each category by introducing the side information. The noise weighting module aims to estimate the correctness of each noisy image and produce a confidence score for image ranking during the training procedure. The propsed SINet can largely alleviate the negative impact of noisy image labels, and is beneficial to train a high performance CNN based classifier. Besides, we released a fine-grained product dataset called AliProducts, which contains more than 2.5 million noisy web images crawled from the internet by using queries generated from 50,000 fine-grained semantic classes. Extensive experiments on several popular benchmarks (i.e. Webvision, ImageNet and Clothing-1M) and our proposed AliProducts achieve state-of-the-art performance. The SINet has won the first place in the classification task on WebVision Challenge 2019, and outperformed other competitors by a large margin.
Learning Deep Context-aware Features over Body and Latent Parts for Person Re-identification
Oct 18, 2017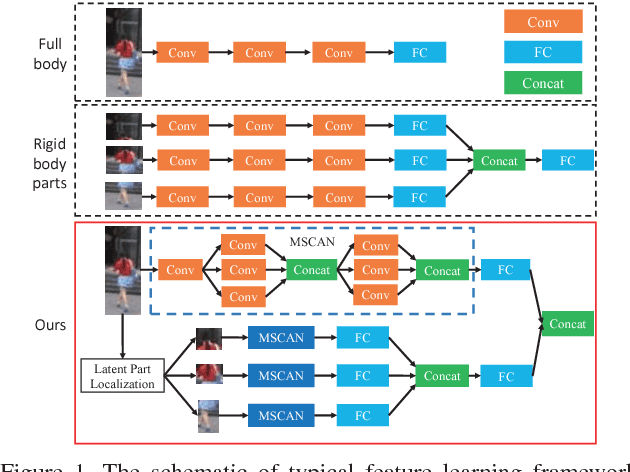
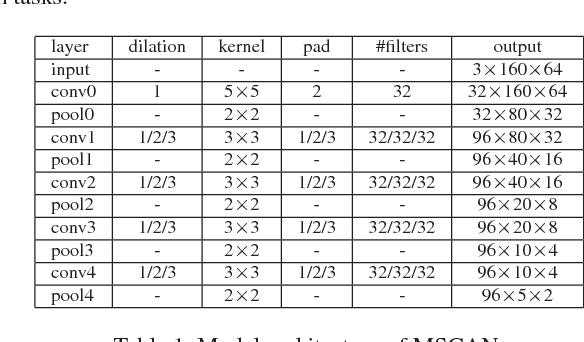
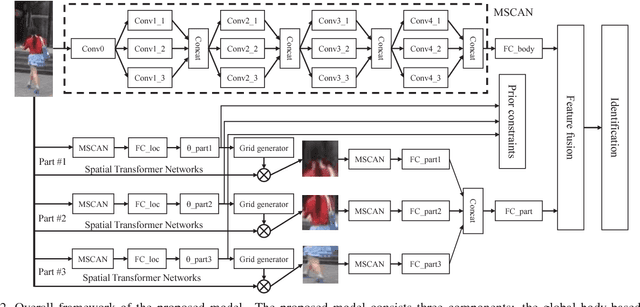
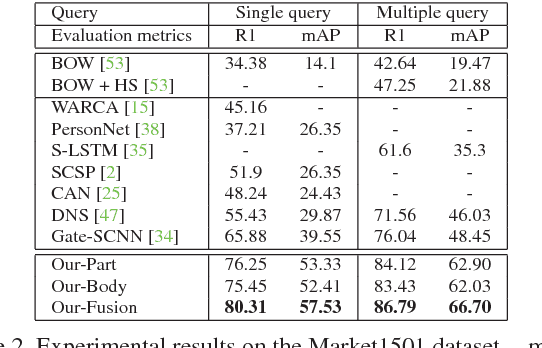
Person Re-identification (ReID) is to identify the same person across different cameras. It is a challenging task due to the large variations in person pose, occlusion, background clutter, etc How to extract powerful features is a fundamental problem in ReID and is still an open problem today. In this paper, we design a Multi-Scale Context-Aware Network (MSCAN) to learn powerful features over full body and body parts, which can well capture the local context knowledge by stacking multi-scale convolutions in each layer. Moreover, instead of using predefined rigid parts, we propose to learn and localize deformable pedestrian parts using Spatial Transformer Networks (STN) with novel spatial constraints. The learned body parts can release some difficulties, eg pose variations and background clutters, in part-based representation. Finally, we integrate the representation learning processes of full body and body parts into a unified framework for person ReID through multi-class person identification tasks. Extensive evaluations on current challenging large-scale person ReID datasets, including the image-based Market1501, CUHK03 and sequence-based MARS datasets, show that the proposed method achieves the state-of-the-art results.
Weakly-supervised Learning of Mid-level Features for Pedestrian Attribute Recognition and Localization
Nov 17, 2016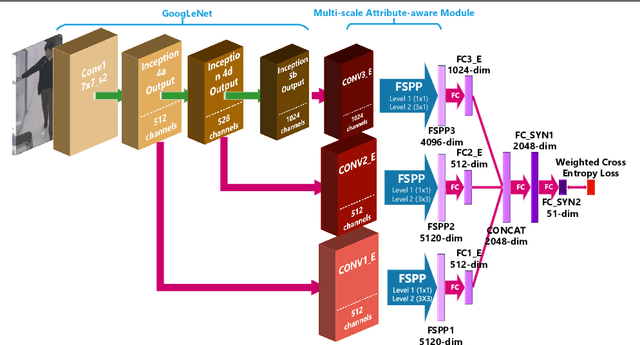

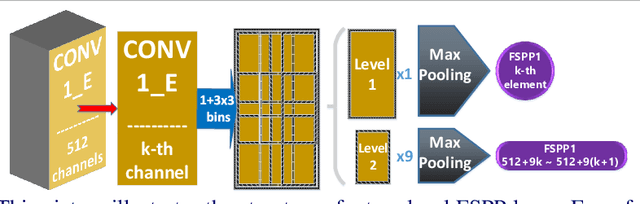
State-of-the-art methods treat pedestrian attribute recognition as a multi-label image classification problem. The location information of person attributes is usually eliminated or simply encoded in the rigid splitting of whole body in previous work. In this paper, we formulate the task in a weakly-supervised attribute localization framework. Based on GoogLeNet, firstly, a set of mid-level attribute features are discovered by novelly designed detection layers, where a max-pooling based weakly-supervised object detection technique is used to train these layers with only image-level labels without the need of bounding box annotations of pedestrian attributes. Secondly, attribute labels are predicted by regression of the detection response magnitudes. Finally, the locations and rough shapes of pedestrian attributes can be inferred by performing clustering on a fusion of activation maps of the detection layers, where the fusion weights are estimated as the correlation strengths between each attribute and its relevant mid-level features. Extensive experiments are performed on the two currently largest pedestrian attribute datasets, i.e. the PETA dataset and the RAP dataset. Results show that the proposed method has achieved competitive performance on attribute recognition, compared to other state-of-the-art methods. Moreover, the results of attribute localization are visualized to understand the characteristics of the proposed method.
A Richly Annotated Dataset for Pedestrian Attribute Recognition
Apr 27, 2016
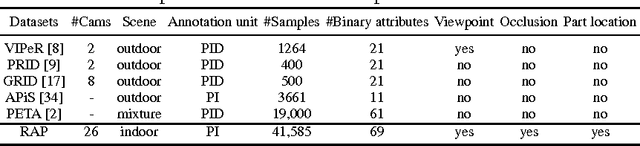
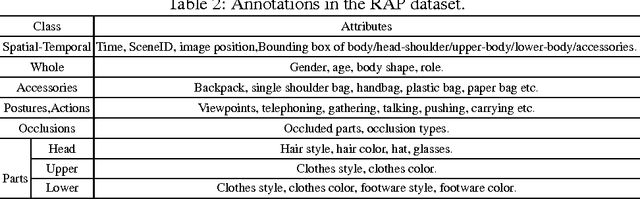
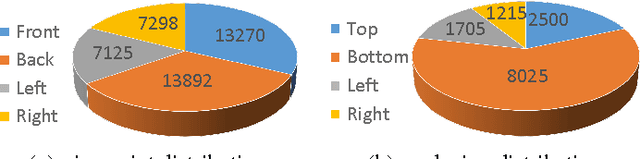
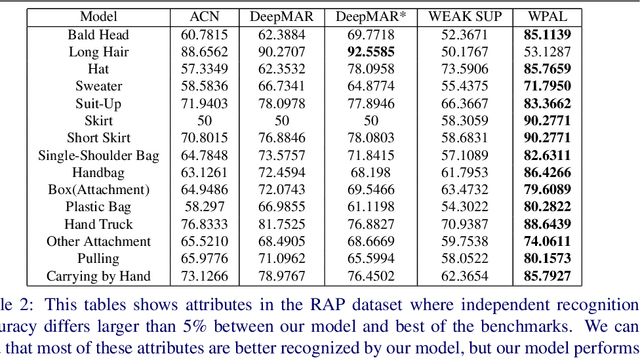
In this paper, we aim to improve the dataset foundation for pedestrian attribute recognition in real surveillance scenarios. Recognition of human attributes, such as gender, and clothes types, has great prospects in real applications. However, the development of suitable benchmark datasets for attribute recognition remains lagged behind. Existing human attribute datasets are collected from various sources or an integration of pedestrian re-identification datasets. Such heterogeneous collection poses a big challenge on developing high quality fine-grained attribute recognition algorithms. Furthermore, human attribute recognition are generally severely affected by environmental or contextual factors, such as viewpoints, occlusions and body parts, while existing attribute datasets barely care about them. To tackle these problems, we build a Richly Annotated Pedestrian (RAP) dataset from real multi-camera surveillance scenarios with long term collection, where data samples are annotated with not only fine-grained human attributes but also environmental and contextual factors. RAP has in total 41,585 pedestrian samples, each of which is annotated with 72 attributes as well as viewpoints, occlusions, body parts information. To our knowledge, the RAP dataset is the largest pedestrian attribute dataset, which is expected to greatly promote the study of large-scale attribute recognition systems. Furthermore, we empirically analyze the effects of different environmental and contextual factors on pedestrian attribute recognition. Experimental results demonstrate that viewpoints, occlusions and body parts information could assist attribute recognition a lot in real applications.