 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-WorldBench: Towards a Comprehensive Interaction-Centric Evaluation for World Models
Mar 23, 2026Video--based world models have emerged along two dominant paradigms: video generation and 3D reconstruction. However, existing evaluation benchmarks either focus narrowly on visual fidelity and text--video alignment for generative models, or rely on static 3D reconstruction metrics that fundamentally neglect temporal dynamics. We argue that the future of world modeling lies in 4D generation, which jointly models spatial structure and temporal evolution. In this paradigm, the core capability is interactive response: the ability to faithfully reflect how interaction actions drive state transitions across space and time. Yet no existing benchmark systematically evaluates this critical dimension. To address this gap, we propose Omni--WorldBench, a comprehensive benchmark specifically designed to evaluate the interactive response capabilities of world models in 4D settings. Omni--WorldBench comprises two key components: Omni--WorldSuite, a systematic prompt suite spanning diverse interaction levels and scene types; and Omni--Metrics, an agent-based evaluation framework that quantifies world modeling capabilities by measuring the causal impact of interaction actions on both final outcomes and intermediate state evolution trajectories. We conduct extensive evaluations of 18 representative world models across multiple paradigms. Our analysis reveals critical limitations of current world models in interactive response, providing actionable insights for future research. Omni-WorldBench will be publicly released to foster progress in interactive 4D world modeling.
Breaking the Tuning Barrier: Zero-Hyperparameters Yield Multi-Corner Analysis Via Learned Priors
Mar 13, 2026Yield Multi-Corner Analysis validates circuits across 25+ Process-Voltage-Temperature corners, resulting in a combinatorial simulation cost of $O(K \times N)$ where $K$ denotes corners and $N$ exceeds $10^4$ samples per corner. Existing methods face a fundamental trade-off: simple models achieve automation but fail on nonlinear circuits, while advanced AI models capture complex behaviors but require hours of hyperparameter tuning per design iteration, forming the Tuning Barrier. We break this barrier by replacing engineered priors (i.e., model specifications) with learned priors from a foundation model pre-trained on millions of regression tasks. This model performs in-context learning, instantly adapting to each circuit without tuning or retraining. Its attention mechanism automatically transfers knowledge across corners by identifying shared circuit physics between operating conditions. Combined with an automated feature selector (1152D to 48D), our method matches state-of-the-art accuracy (mean MREs as low as 0.11\%) with zero tuning, reducing total validation cost by over $10\times$.
Latent Temporal Discrepancy as Motion Prior: A Loss-Weighting Strategy for Dynamic Fidelity in T2V
Jan 28, 2026Video generation models have achieved notable progress in static scenarios, yet their performance in motion video generation remains limited, with quality degrading under drastic dynamic changes. This is due to noise disrupting temporal coherence and increasing the difficulty of learning dynamic regions. {Unfortunately, existing diffusion models rely on static loss for all scenarios, constraining their ability to capture complex dynamics.} To address this issue, we introduce Latent Temporal Discrepancy (LTD) as a motion prior to guide loss weighting. LTD measures frame-to-frame variation in the latent space, assigning larger penalties to regions with higher discrepancy while maintaining regular optimization for stable regions. This motion-aware strategy stabilizes training and enables the model to better reconstruct high-frequency dynamics. Extensive experiments on the general benchmark VBench and the motion-focused VMBench show consistent gains, with our method outperforming strong baselines by 3.31% on VBench and 3.58% on VMBench, achieving significant improvements in motion quality.
SciAgent: A Unified Multi-Agent System for Generalistic Scientific Reasoning
Nov 17, 2025Recent advances in large language models have enabled AI systems to achieve expert-level performance on domain-specific scientific tasks, yet these systems remain narrow and handcrafted. We introduce SciAgent, a unified multi-agent system designed for generalistic scientific reasoning-the ability to adapt reasoning strategies across disciplines and difficulty levels. SciAgent organizes problem solving as a hierarchical process: a Coordinator Agent interprets each problem's domain and complexity, dynamically orchestrating specialized Worker Systems, each composed of interacting reasoning Sub-agents for symbolic deduction, conceptual modeling, numerical computation, and verification. These agents collaboratively assemble and refine reasoning pipelines tailored to each task. Across mathematics and physics Olympiads (IMO, IMC, IPhO, CPhO), SciAgent consistently attains or surpasses human gold-medalist performance, demonstrating both domain generality and reasoning adaptability. Additionally, SciAgent has been tested on the International Chemistry Olympiad (IChO) and selected problems from the Humanity's Last Exam (HLE) benchmark, further confirming the system's ability to generalize across diverse scientific domains. This work establishes SciAgent as a concrete step toward generalistic scientific intelligence-AI systems capable of coherent, cross-disciplinary reasoning at expert levels.
No-Regret Strategy Solving in Imperfect-Information Games via Pre-Trained Embedding
Nov 15, 2025High-quality information set abstraction remains a core challenge in solving large-scale imperfect-information extensive-form games (IIEFGs)-such as no-limit Texas Hold'em-where the finite nature of spatial resources hinders strategy solving over the full game. State-of-the-art AI methods rely on pre-trained discrete clustering for abstraction, yet their hard classification irreversibly loses critical information: specifically, the quantifiable subtle differences between information sets-vital for strategy solving-thereby compromising the quality of such solving. Inspired by the word embedding paradigm in natural language processing, this paper proposes the Embedding CFR algorithm, a novel approach for solving strategies in IIEFGs within an embedding space. The algorithm pre-trains and embeds features of isolated information sets into an interconnected low-dimensional continuous space, where the resulting vectors more precisely capture both the distinctions and connections between information sets. Embedding CFR presents a strategy-solving process driven by regret accumulation and strategy updates within this embedding space, with accompanying theoretical analysis verifying its capacity to reduce cumulative regret. Experiments on poker show that with the same spatial overhead, Embedding CFR achieves significantly faster exploitability convergence compared to cluster-based abstraction algorithms, confirming its effectiveness. Furthermore, to our knowledge, it is the first algorithm in poker AI that pre-trains information set abstractions through low-dimensional embedding for strategy solving.
KrwEmd: Revising the Imperfect-Recall Abstraction from Forgetting Everything
Nov 15, 2025Excessive abstraction is a critical challenge in hand abstraction-a task specific to games like Texas hold'em-when solving large-scale imperfect-information games, as it impairs AI performance. This issue arises from extreme implementations of imperfect-recall abstraction, which entirely discard historical information. This paper presents KrwEmd, the first practical algorithm designed to address this problem. We first introduce the k-recall winrate feature, which not only qualitatively distinguishes signal observation infosets by leveraging both future and, crucially, historical game information, but also quantitatively captures their similarity. We then develop the KrwEmd algorithm, which clusters signal observation infosets using earth mover's distance to measure discrepancies between their features. Experimental results demonstrate that KrwEmd significantly improves AI gameplay performance compared to existing algorithms.
VS-LLM: Visual-Semantic Depression Assessment based on LLM for Drawing Projection Test
Aug 07, 2025The Drawing Projection Test (DPT) is an essential tool in art therapy, allowing psychologists to assess participants' mental states through their sketches. Specifically, through sketches with the theme of "a person picking an apple from a tree (PPAT)", it can be revealed whether the participants are in mental states such as depression. Compared with scales, the DPT can enrich psychologists' understanding of an individual's mental state. However, the interpretation of the PPAT is laborious and depends on the experience of the psychologists. To address this issue, we propose an effective identification method to support psychologists in conducting a large-scale automatic DPT. Unlike traditional sketch recognition, DPT more focus on the overall evaluation of the sketches, such as color usage and space utilization. Moreover, PPAT imposes a time limit and prohibits verbal reminders, resulting in low drawing accuracy and a lack of detailed depiction. To address these challenges, we propose the following efforts: (1) Providing an experimental environment for automated analysis of PPAT sketches for depression assessment; (2) Offering a Visual-Semantic depression assessment based on LLM (VS-LLM) method; (3) Experimental results demonstrate that our method improves by 17.6% compared to the psychologist assessment method. We anticipate that this work will contribute to the research in mental state assessment based on PPAT sketches' elements recognition. Our datasets and codes are available at https://github.com/wmeiqi/VS-LLM.
CausalStep: A Benchmark for Explicit Stepwise Causal Reasoning in Videos
Jul 22, 2025Recent advances in large language models (LLMs) have improved reasoning in text and image domains, yet achieving robust video reasoning remains a significant challenge. Existing video benchmarks mainly assess shallow understanding and reasoning and allow models to exploit global context, failing to rigorously evaluate true causal and stepwise reasoning. We present CausalStep, a benchmark designed for explicit stepwise causal reasoning in videos. CausalStep segments videos into causally linked units and enforces a strict stepwise question-answer (QA) protocol, requiring sequential answers and preventing shortcut solutions. Each question includes carefully constructed distractors based on error type taxonomy to ensure diagnostic value. The benchmark features 100 videos across six categories and 1,852 multiple-choice QA pairs. We introduce seven diagnostic metrics for comprehensive evaluation, enabling precise diagnosis of causal reasoning capabilities. Experiments with leading proprietary and open-source models, as well as human baselines, reveal a significant gap between current models and human-level stepwise reasoning. CausalStep provides a rigorous benchmark to drive progress in robust and interpretable video reasoning.
WGSR-Bench: Wargame-based Game-theoretic Strategic Reasoning Benchmark for Large Language Models
Jun 12, 2025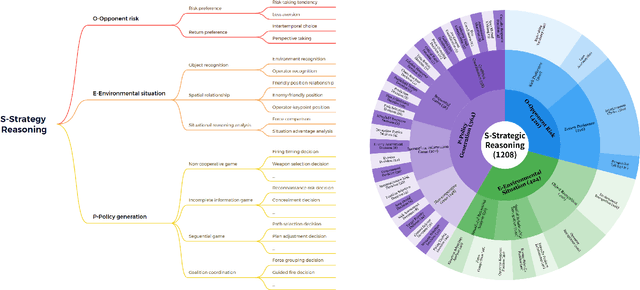
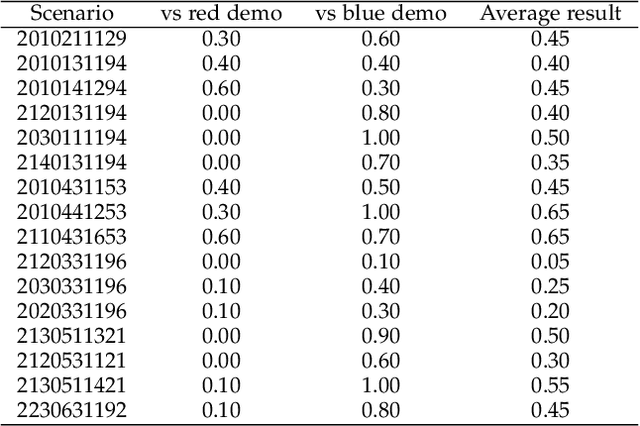
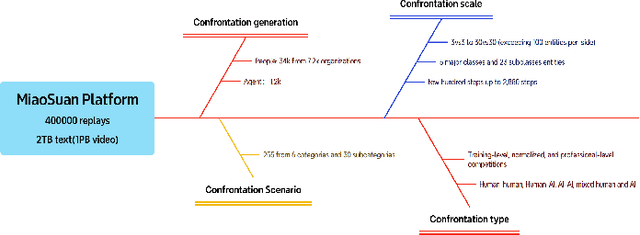
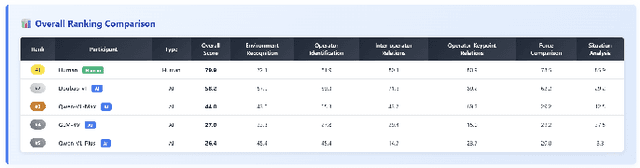
Recent breakthroughs in Large Language Models (LLMs) have led to a qualitative leap in artificial intelligence' s performance on reasoning tasks, particularly demonstrating remarkable capabilities in mathematical, symbolic, and commonsense reasoning. However, as a critical component of advanced human cognition, strategic reasoning, i.e., the ability to assess multi-agent behaviors in dynamic environments, formulate action plans, and adapt strategies, has yet to be systematically evaluated or modeled. To address this gap, this paper introduces WGSR-Bench, the first strategy reasoning benchmark for LLMs using wargame as its evaluation environment. Wargame, a quintessential high-complexity strategic scenario, integrates environmental uncertainty, adversarial dynamics, and non-unique strategic choices, making it an effective testbed for assessing LLMs' capabilities in multi-agent decision-making, intent inference, and counterfactual reasoning. WGSR-Bench designs test samples around three core tasks, i.e., Environmental situation awareness, Opponent risk modeling and Policy generation, which serve as the core S-POE architecture, to systematically assess main abilities of strategic reasoning. Finally, an LLM-based wargame agent is designed to integrate these parts for a comprehensive strategy reasoning assessment. With WGSR-Bench, we hope to assess the strengths and limitations of state-of-the-art LLMs in game-theoretic strategic reasoning and to advance research in large model-driven strategic intelligence.
Finger in Camera Speaks Everything: Unconstrained Air-Writing for Real-World
Dec 27, 2024



Air-writing is a challenging task that combines the fields of computer vision and natural language processing, offering an intuitive and natural approach for human-computer interaction. However, current air-writing solutions face two primary challenges: (1) their dependency on complex sensors (e.g., Radar, EEGs and others) for capturing precise handwritten trajectories, and (2) the absence of a video-based air-writing dataset that covers a comprehensive vocabulary range. These limitations impede their practicality in various real-world scenarios, including the use on devices like iPhones and laptops. To tackle these challenges, we present the groundbreaking air-writing Chinese character video dataset (AWCV-100K-UCAS2024), serving as a pioneering benchmark for video-based air-writing. This dataset captures handwritten trajectories in various real-world scenarios using commonly accessible RGB cameras, eliminating the need for complex sensors. AWCV-100K-UCAS2024 includes 8.8 million video frames, encompassing the complete set of 3,755 characters from the GB2312-80 level-1 set (GB1). Furthermore, we introduce our baseline approach, the video-based character recognizer (VCRec). VCRec adeptly extracts fingertip features from sparse visual cues and employs a spatio-temporal sequence module for analysis. Experimental results showcase the superior performance of VCRec compared to existing models in recognizing air-written characters, both quantitatively and qualitatively. This breakthrough paves the way for enhanced human-computer interaction in real-world contexts. Moreover, our approach leverages affordable RGB cameras, enabling its applicability in a diverse range of scenarios. The code and data examples will be made public at https://github.com/wmeiqi/AWCV.