 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
Step-DeepResearch Technical Report
Dec 24, 2025As LLMs shift toward autonomous agents, Deep Research has emerged as a pivotal metric. However, existing academic benchmarks like BrowseComp often fail to meet real-world demands for open-ended research, which requires robust skills in intent recognition, long-horizon decision-making, and cross-source verification. To address this, we introduce Step-DeepResearch, a cost-effective, end-to-end agent. We propose a Data Synthesis Strategy Based on Atomic Capabilities to reinforce planning and report writing, combined with a progressive training path from agentic mid-training to SFT and RL. Enhanced by a Checklist-style Judger, this approach significantly improves robustness. Furthermore, to bridge the evaluation gap in the Chinese domain, we establish ADR-Bench for realistic deep research scenarios. Experimental results show that Step-DeepResearch (32B) scores 61.4% on Scale AI Research Rubrics. On ADR-Bench, it significantly outperforms comparable models and rivals SOTA closed-source models like OpenAI and Gemini DeepResearch. These findings prove that refined training enables medium-sized models to achieve expert-level capabilities at industry-leading cost-efficiency.
Dyn-Adapter: Towards Disentangled Representation for Efficient Visual Recognition
Jul 19, 2024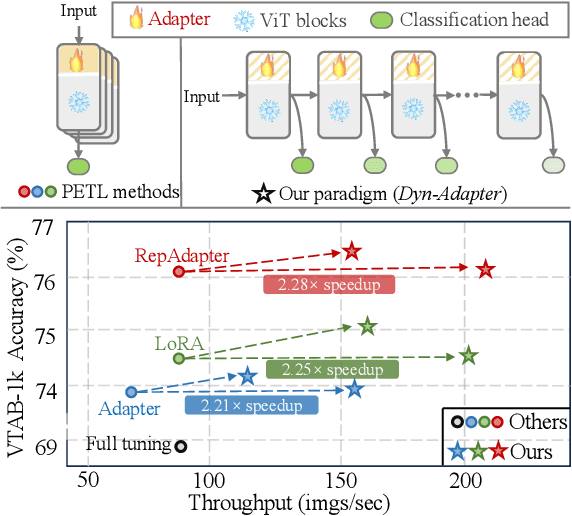
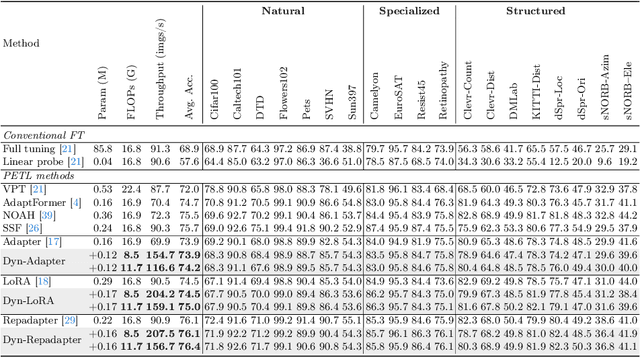
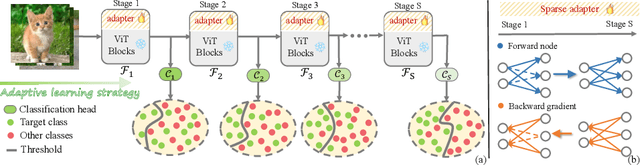
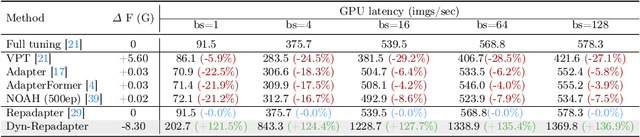
Parameter-efficient transfer learning (PETL) is a promising task, aiming to adapt the large-scale pre-trained model to downstream tasks with a relatively modest cost. However, current PETL methods struggle in compressing computational complexity and bear a heavy inference burden due to the complete forward process. This paper presents an efficient visual recognition paradigm, called Dynamic Adapter (Dyn-Adapter), that boosts PETL efficiency by subtly disentangling features in multiple levels. Our approach is simple: first, we devise a dynamic architecture with balanced early heads for multi-level feature extraction, along with adaptive training strategy. Second, we introduce a bidirectional sparsity strategy driven by the pursuit of powerful generalization ability. These qualities enable us to fine-tune efficiently and effectively: we reduce FLOPs during inference by 50%, while maintaining or even yielding higher recognition accuracy. Extensive experiments on diverse datasets and pretrained backbones demonstrate the potential of Dyn-Adapter serving as a general efficiency booster for PETL in vision recognition tasks.
Revealing the Dark Secrets of Extremely Large Kernel ConvNets on Robustness
Jul 12, 2024



Robustness is a vital aspect to consider when deploying deep learning models into the wild. Numerous studies have been dedicated to the study of the robustness of vision transformers (ViTs), which have dominated as the mainstream backbone choice for vision tasks since the dawn of 2020s. Recently, some large kernel convnets make a comeback with impressive performance and efficiency. However, it still remains unclear whether large kernel networks are robust and the attribution of their robustness. In this paper, we first conduct a comprehensive evaluation of large kernel convnets' robustness and their differences from typical small kernel counterparts and ViTs on six diverse robustness benchmark datasets. Then to analyze the underlying factors behind their strong robustness, we design experiments from both quantitative and qualitative perspectives to reveal large kernel convnets' intriguing properties that are completely different from typical convnets. Our experiments demonstrate for the first time that pure CNNs can achieve exceptional robustness comparable or even superior to that of ViTs. Our analysis on occlusion invariance, kernel attention patterns and frequency characteristics provide novel insights into the source of robustness.
Boosting Video Object Segmentation via Space-time Correspondence Learning
Apr 13, 2023Current top-leading solutions for video object segmentation (VOS) typically follow a matching-based regime: for each query frame, the segmentation mask is inferred according to its correspondence to previously processed and the first annotated frames. They simply exploit the supervisory signals from the groundtruth masks for learning mask prediction only, without posing any constraint on the space-time correspondence matching, which, however, is the fundamental building block of such regime. To alleviate this crucial yet commonly ignored issue, we devise a correspondence-aware training framework, which boosts matching-based VOS solutions by explicitly encouraging robust correspondence matching during network learning. Through comprehensively exploring the intrinsic coherence in videos on pixel and object levels, our algorithm reinforces the standard, fully supervised training of mask segmentation with label-free, contrastive correspondence learning. Without neither requiring extra annotation cost during training, nor causing speed delay during deployment, nor incurring architectural modification, our algorithm provides solid performance gains on four widely used benchmarks, i.e., DAVIS2016&2017, and YouTube-VOS2018&2019, on the top of famous matching-based VOS solutions.