 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdsorbFlow: energy-conditioned flow matching enables fast and realistic adsorbate placement
Feb 22, 2026Identifying low-energy adsorption geometries on catalytic surfaces is a practical bottleneck for computational heterogeneous catalysis: the difficulty lies not only in the cost of density functional theory (DFT) but in proposing initial placements that relax into the correct energy basins. Conditional denoising diffusion has improved success rates, yet requires $\sim$100 iterative steps per sample. Here we introduce AdsorbFlow, a deterministic generative model that learns an energy-conditioned vector field on the rigid-body configuration space of adsorbate translation and rotation via conditional flow matching. Energy information enters through classifier-free guidance conditioning -- not energy-gradient guidance -- and sampling reduces to integrating an ODE in as few as 5 steps. On OC20-Dense with full DFT single-point verification, AdsorbFlow with an EquiformerV2 backbone achieves 61.4% SR@10 and 34.1% SR@1 -- surpassing AdsorbDiff (31.8% SR@1, 41.0% SR@10) at every evaluation level and AdsorbML (47.7% SR@10) -- while using 20 times fewer generative steps and achieving the lowest anomaly rate among generative methods (6.8%). On 50 out-of-distribution systems, AdsorbFlow retains 58.0% SR@10 with a MLFF-to-DFT gap of only 4~percentage points. These results establish that deterministic transport is both faster and more accurate than stochastic denoising for adsorbate placement.
CatMaster: An Agentic Autonomous System for Computational Heterogeneous Catalysis Research
Jan 20, 2026Density functional theory (DFT) is widely used to connect atomic structure with catalytic behavior, but computational heterogeneous catalysis studies often require long workflows that are costly, iterative, and sensitive to setup choices. Besides the intrinsic cost and accuracy limits of first-principles calculations, practical workflow issues such as keeping references consistent, preparing many related inputs, recovering from failed runs on computing clusters, and maintaining a complete record of what was done, can slow down projects and make results difficult to reproduce or extend. Here we present CatMaster, a large-language-model (LLM)-driven agent system that turns natural language requests into complete calculation workspaces, including structures, inputs, outputs, logs, and a concise run record. CatMaster maintains a persistent project record of key facts, constraints, and file pointers to support inspection and restartability. It is paired with a multi-fidelity tool library that covers rapid surrogate relaxations and high-fidelity DFT calculations for validation when needed. We demonstrate CatMaster on four demonstrations of increasing complexity: an O2 spin-state check with remote execution, BCC Fe surface energies with a protocol-sensitivity study and CO adsorption site ranking, high-throughput Pt--Ni--Cu alloy screening for hydrogen evolution reaction (HER) descriptors with surrogate-to-DFT validation, and a demonstration beyond the predefined tool set, including equation-of-state fitting for BCC Fe and CO-FeN4-graphene single-atom catalyst geometry preparation. By reducing manual scripting and bookkeeping while keeping the full evidence trail, CatMaster aims to help catalysis researchers focus on modeling choices and chemical interpretation rather than workflow management.
Emu3.5: Native Multimodal Models are World Learners
Oct 30, 2025We introduce Emu3.5, a large-scale multimodal world model that natively predicts the next state across vision and language. Emu3.5 is pre-trained end-to-end with a unified next-token prediction objective on a corpus of vision-language interleaved data containing over 10 trillion tokens, primarily derived from sequential frames and transcripts of internet videos. The model naturally accepts interleaved vision-language inputs and generates interleaved vision-language outputs. Emu3.5 is further post-trained with large-scale reinforcement learning to enhance multimodal reasoning and generation. To improve inference efficiency, we propose Discrete Diffusion Adaptation (DiDA), which converts token-by-token decoding into bidirectional parallel prediction, accelerating per-image inference by about 20x without sacrificing performance. Emu3.5 exhibits strong native multimodal capabilities, including long-horizon vision-language generation, any-to-image (X2I) generation, and complex text-rich image generation. It also exhibits generalizable world-modeling abilities, enabling spatiotemporally consistent world exploration and open-world embodied manipulation across diverse scenarios and tasks. For comparison, Emu3.5 achieves performance comparable to Gemini 2.5 Flash Image (Nano Banana) on image generation and editing tasks and demonstrates superior results on a suite of interleaved generation tasks. We open-source Emu3.5 at https://github.com/baaivision/Emu3.5 to support community research.
Dyn-Adapter: Towards Disentangled Representation for Efficient Visual Recognition
Jul 19, 2024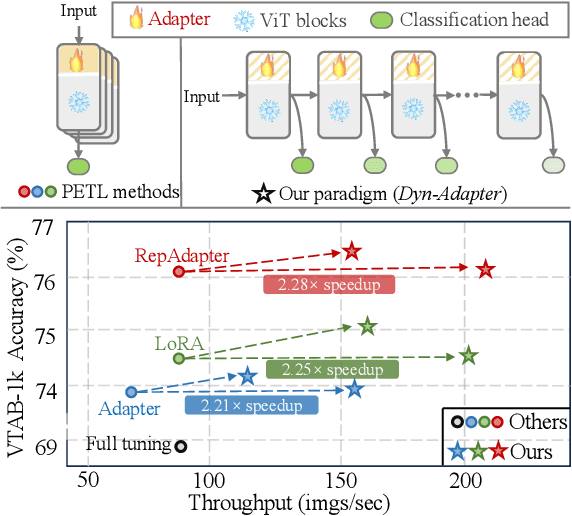
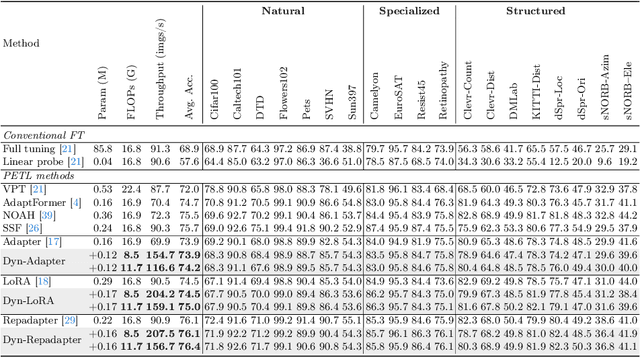
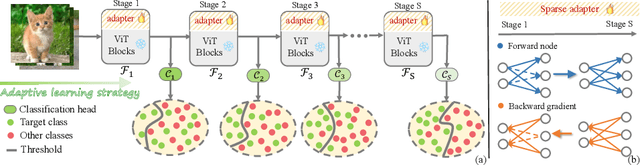
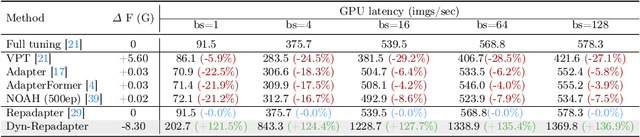
Parameter-efficient transfer learning (PETL) is a promising task, aiming to adapt the large-scale pre-trained model to downstream tasks with a relatively modest cost. However, current PETL methods struggle in compressing computational complexity and bear a heavy inference burden due to the complete forward process. This paper presents an efficient visual recognition paradigm, called Dynamic Adapter (Dyn-Adapter), that boosts PETL efficiency by subtly disentangling features in multiple levels. Our approach is simple: first, we devise a dynamic architecture with balanced early heads for multi-level feature extraction, along with adaptive training strategy. Second, we introduce a bidirectional sparsity strategy driven by the pursuit of powerful generalization ability. These qualities enable us to fine-tune efficiently and effectively: we reduce FLOPs during inference by 50%, while maintaining or even yielding higher recognition accuracy. Extensive experiments on diverse datasets and pretrained backbones demonstrate the potential of Dyn-Adapter serving as a general efficiency booster for PETL in vision recognition tasks.
Revealing the Dark Secrets of Extremely Large Kernel ConvNets on Robustness
Jul 12, 2024



Robustness is a vital aspect to consider when deploying deep learning models into the wild. Numerous studies have been dedicated to the study of the robustness of vision transformers (ViTs), which have dominated as the mainstream backbone choice for vision tasks since the dawn of 2020s. Recently, some large kernel convnets make a comeback with impressive performance and efficiency. However, it still remains unclear whether large kernel networks are robust and the attribution of their robustness. In this paper, we first conduct a comprehensive evaluation of large kernel convnets' robustness and their differences from typical small kernel counterparts and ViTs on six diverse robustness benchmark datasets. Then to analyze the underlying factors behind their strong robustness, we design experiments from both quantitative and qualitative perspectives to reveal large kernel convnets' intriguing properties that are completely different from typical convnets. Our experiments demonstrate for the first time that pure CNNs can achieve exceptional robustness comparable or even superior to that of ViTs. Our analysis on occlusion invariance, kernel attention patterns and frequency characteristics provide novel insights into the source of robustness.
PeLK: Parameter-efficient Large Kernel ConvNets with Peripheral Convolution
Mar 16, 2024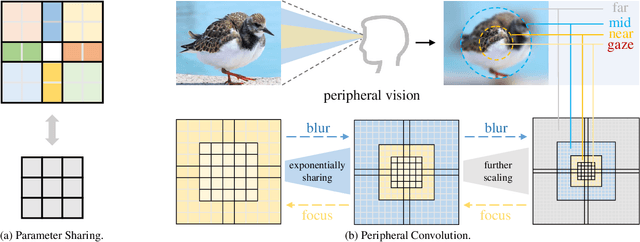

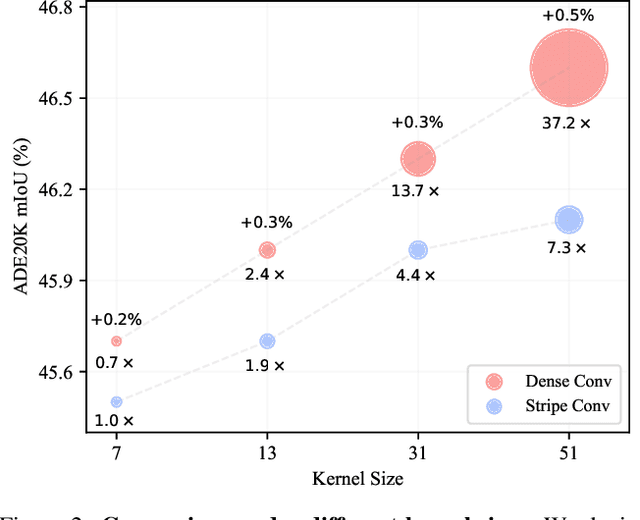
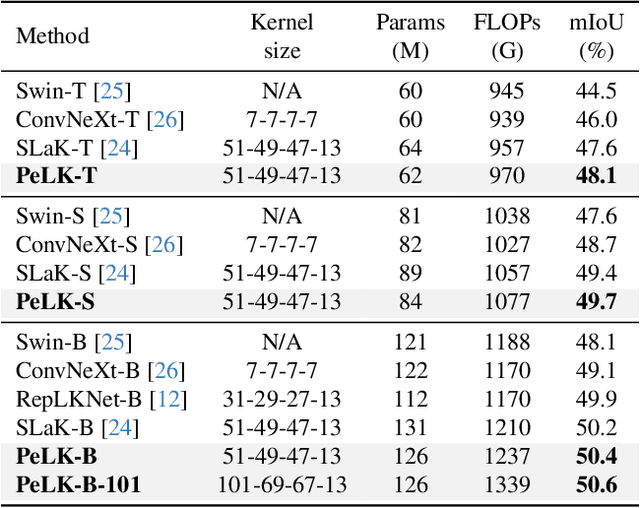
Recently, some large kernel convnets strike back with appealing performance and efficiency. However, given the square complexity of convolution, scaling up kernels can bring about an enormous amount of parameters and the proliferated parameters can induce severe optimization problem. Due to these issues, current CNNs compromise to scale up to 51x51 in the form of stripe convolution (i.e., 51x5 + 5x51) and start to saturate as the kernel size continues growing. In this paper, we delve into addressing these vital issues and explore whether we can continue scaling up kernels for more performance gains. Inspired by human vision, we propose a human-like peripheral convolution that efficiently reduces over 90% parameter count of dense grid convolution through parameter sharing, and manage to scale up kernel size to extremely large. Our peripheral convolution behaves highly similar to human, reducing the complexity of convolution from O(K^2) to O(logK) without backfiring performance. Built on this, we propose Parameter-efficient Large Kernel Network (PeLK). Our PeLK outperforms modern vision Transformers and ConvNet architectures like Swin, ConvNeXt, RepLKNet and SLaK on various vision tasks including ImageNet classification, semantic segmentation on ADE20K and object detection on MS COCO. For the first time, we successfully scale up the kernel size of CNNs to an unprecedented 101x101 and demonstrate consistent improvements.
Re-parameterizing Your Optimizers rather than Architectures
May 30, 2022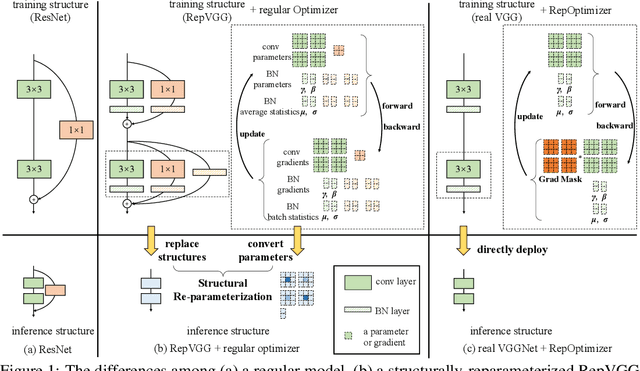



The well-designed structures in neural networks reflect the prior knowledge incorporated into the models. However, though different models have various priors, we are used to training them with model-agnostic optimizers (e.g., SGD). In this paper, we propose a novel paradigm of incorporating model-specific prior knowledge into optimizers and using them to train generic (simple) models. As an implementation, we propose a novel methodology to add prior knowledge by modifying the gradients according to a set of model-specific hyper-parameters, which is referred to as Gradient Re-parameterization, and the optimizers are named RepOptimizers. For the extreme simplicity of model structure, we focus on a VGG-style plain model and showcase that such a simple model trained with a RepOptimizer, which is referred to as RepOpt-VGG, performs on par with the recent well-designed models. From a practical perspective, RepOpt-VGG is a favorable base model because of its simple structure, high inference speed and training efficiency. Compared to Structural Re-parameterization, which adds priors into models via constructing extra training-time structures, RepOptimizers require no extra forward/backward computations and solve the problem of quantization. The code and models are publicly available at https://github.com/DingXiaoH/RepOptimizers.
RepMLPNet: Hierarchical Vision MLP with Re-parameterized Locality
Dec 21, 2021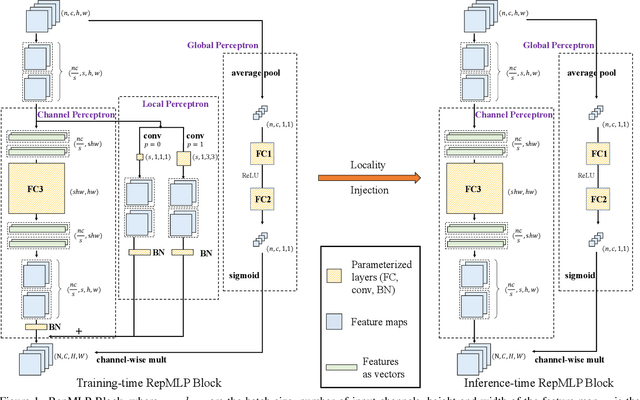
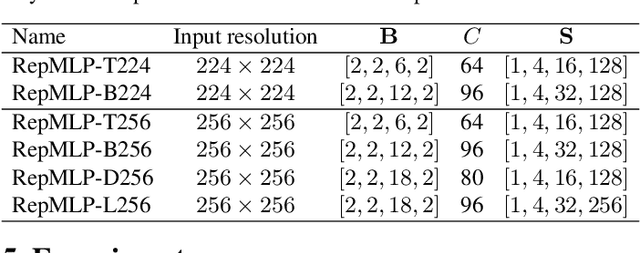
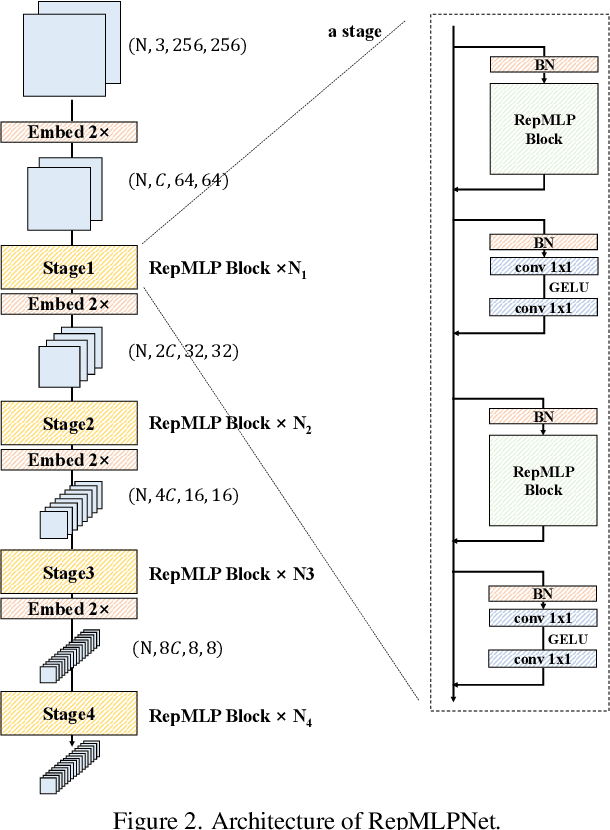

Compared to convolutional layers, fully-connected (FC) layers are better at modeling the long-range dependencies but worse at capturing the local patterns, hence usually less favored for image recognition. In this paper, we propose a methodology, Locality Injection, to incorporate local priors into an FC layer via merging the trained parameters of a parallel conv kernel into the FC kernel. Locality Injection can be viewed as a novel Structural Re-parameterization method since it equivalently converts the structures via transforming the parameters. Based on that, we propose a multi-layer-perceptron (MLP) block named RepMLP Block, which uses three FC layers to extract features, and a novel architecture named RepMLPNet. The hierarchical design distinguishes RepMLPNet from the other concurrently proposed vision MLPs. As it produces feature maps of different levels, it qualifies as a backbone model for downstream tasks like semantic segmentation. Our results reveal that 1) Locality Injection is a general methodology for MLP models; 2) RepMLPNet has favorable accuracy-efficiency trade-off compared to the other MLPs; 3) RepMLPNet is the first MLP that seamlessly transfer to Cityscapes semantic segmentation. The code and models are available at https://github.com/DingXiaoH/RepMLP.