 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Human-AI Triadic Programming: Uncovering the Role of AI Agent and the Value of Human Partner in Collaborative Learning
Jan 17, 2026As AI assistance becomes embedded in programming practice, researchers have increasingly examined how these systems help learners generate code and work more efficiently. However, these studies often position AI as a replacement for human collaboration and overlook the social and learning-oriented aspects that emerge in collaborative programming. Our work introduces human-human-AI (HHAI) triadic programming, where an AI agent serves as an additional collaborator rather than a substitute for a human partner. Through a within-subjects study with 20 participants, we show that triadic collaboration enhances collaborative learning and social presence compared to the dyadic human-AI (HAI) baseline. In the triadic HHAI conditions, participants relied significantly less on AI-generated code in their work. This effect was strongest in the HHAI-shared condition, where participants had an increased sense of responsibility to understand AI suggestions before applying them. These findings demonstrate how triadic settings activate socially shared regulation of learning by making AI use visible and accountable to a human peer, suggesting that AI systems that augment rather than automate peer collaboration can better preserve the learning processes that collaborative programming relies on.
How Managers Perceive AI-Assisted Conversational Training for Workplace Communication
May 21, 2025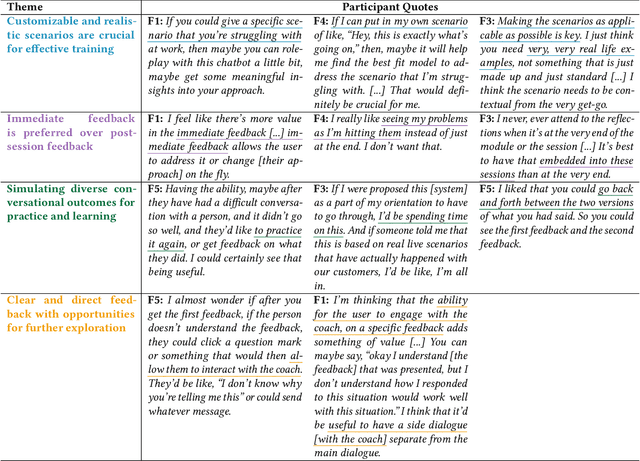
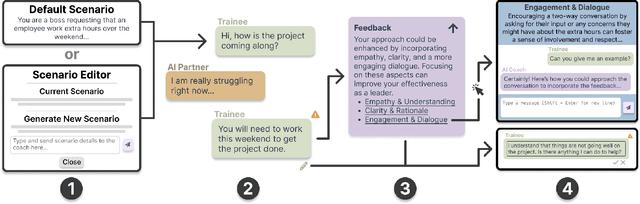
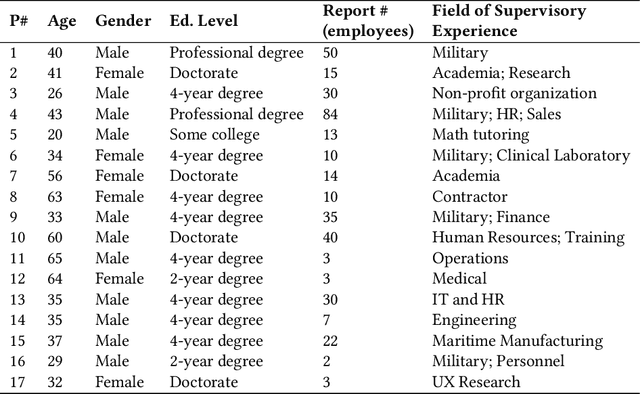
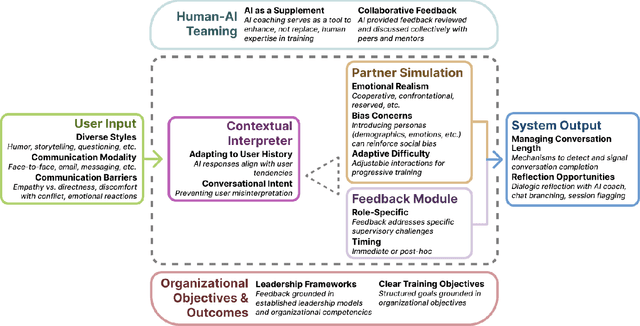
Effective workplace communication is essential for managerial success, yet many managers lack access to tailored and sustained training. Although AI-assisted communication systems may offer scalable training solutions, little is known about how managers envision the role of AI in helping them improve their communication skills. To investigate this, we designed a conversational role-play system, CommCoach, as a functional probe to understand how managers anticipate using AI to practice their communication skills. Through semi-structured interviews, participants emphasized the value of adaptive, low-risk simulations for practicing difficult workplace conversations. They also highlighted opportunities, including human-AI teaming, transparent and context-aware feedback, and greater control over AI-generated personas. AI-assisted communication training should balance personalization, structured learning objectives, and adaptability to different user styles and contexts. However, achieving this requires carefully navigating tensions between adaptive and consistent AI feedback, realism and potential bias, and the open-ended nature of AI conversations versus structured workplace discourse.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
Vision Search Assistant: Empower Vision-Language Models as Multimodal Search Engines
Oct 28, 2024



Search engines enable the retrieval of unknown information with texts. However, traditional methods fall short when it comes to understanding unfamiliar visual content, such as identifying an object that the model has never seen before. This challenge is particularly pronounced for large vision-language models (VLMs): if the model has not been exposed to the object depicted in an image, it struggles to generate reliable answers to the user's question regarding that image. Moreover, as new objects and events continuously emerge, frequently updating VLMs is impractical due to heavy computational burdens. To address this limitation, we propose Vision Search Assistant, a novel framework that facilitates collaboration between VLMs and web agents. This approach leverages VLMs' visual understanding capabilities and web agents' real-time information access to perform open-world Retrieval-Augmented Generation via the web. By integrating visual and textual representations through this collaboration, the model can provide informed responses even when the image is novel to the system. Extensive experiments conducted on both open-set and closed-set QA benchmarks demonstrate that the Vision Search Assistant significantly outperforms the other models and can be widely applied to existing VLMs.
Scaling Up Your Kernels: Large Kernel Design in ConvNets towards Universal Representations
Oct 10, 2024



This paper proposes the paradigm of large convolutional kernels in designing modern Convolutional Neural Networks (ConvNets). We establish that employing a few large kernels, instead of stacking multiple smaller ones, can be a superior design strategy. Our work introduces a set of architecture design guidelines for large-kernel ConvNets that optimize their efficiency and performance. We propose the UniRepLKNet architecture, which offers systematical architecture design principles specifically crafted for large-kernel ConvNets, emphasizing their unique ability to capture extensive spatial information without deep layer stacking. This results in a model that not only surpasses its predecessors with an ImageNet accuracy of 88.0%, an ADE20K mIoU of 55.6%, and a COCO box AP of 56.4% but also demonstrates impressive scalability and performance on various modalities such as time-series forecasting, audio, point cloud, and video recognition. These results indicate the universal modeling abilities of large-kernel ConvNets with faster inference speed compared with vision transformers. Our findings reveal that large-kernel ConvNets possess larger effective receptive fields and a higher shape bias, moving away from the texture bias typical of smaller-kernel CNNs. All codes and models are publicly available at https://github.com/AILab-CVC/UniRepLKNet promoting further research and development in the community.
CounterQuill: Investigating the Potential of Human-AI Collaboration in Online Counterspeech Writing
Oct 03, 2024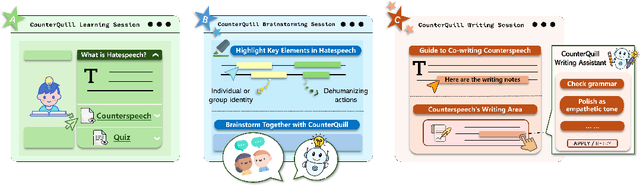



Online hate speech has become increasingly prevalent on social media platforms, causing harm to individuals and society. While efforts have been made to combat this issue through content moderation, the potential of user-driven counterspeech as an alternative solution remains underexplored. Existing counterspeech methods often face challenges such as fear of retaliation and skill-related barriers. To address these challenges, we introduce CounterQuill, an AI-mediated system that assists users in composing effective and empathetic counterspeech. CounterQuill provides a three-step process: (1) a learning session to help users understand hate speech and counterspeech; (2) a brainstorming session that guides users in identifying key elements of hate speech and exploring counterspeech strategies; and (3) a co-writing session that enables users to draft and refine their counterspeech with CounterQuill. We conducted a within-subjects user study with 20 participants to evaluate CounterQuill in comparison to ChatGPT. Results show that CounterQuill's guidance and collaborative writing process provided users a stronger sense of ownership over their co-authored counterspeech. Users perceived CounterQuill as a writing partner and thus were more willing to post the co-written counterspeech online compared to the one written with ChatGPT.
Quantized Prompt for Efficient Generalization of Vision-Language Models
Jul 15, 2024In the past few years, large-scale pre-trained vision-language models like CLIP have achieved tremendous success in various fields. Naturally, how to transfer the rich knowledge in such huge pre-trained models to downstream tasks and datasets becomes a hot topic. During downstream adaptation, the most challenging problems are overfitting and catastrophic forgetting, which can cause the model to overly focus on the current data and lose more crucial domain-general knowledge. Existing works use classic regularization techniques to solve the problems. As solutions become increasingly complex, the ever-growing storage and inference costs are also a significant problem that urgently needs to be addressed. While in this paper, we start from an observation that proper random noise can suppress overfitting and catastrophic forgetting. Then we regard quantization error as a kind of noise, and explore quantization for regularizing vision-language model, which is quite efficiency and effective. Furthermore, to improve the model's generalization capability while maintaining its specialization capacity at minimal cost, we deeply analyze the characteristics of the weight distribution in prompts, conclude several principles for quantization module design and follow such principles to create several competitive baselines. The proposed method is significantly efficient due to its inherent lightweight nature, making it possible to adapt on extremely resource-limited devices. Our method can be fruitfully integrated into many existing approaches like MaPLe, enhancing accuracy while reducing storage overhead, making it more powerful yet versatile. Extensive experiments on 11 datasets shows great superiority of our method sufficiently. Code is available at https://github.com/beyondhtx/QPrompt.
SEED-X: Multimodal Models with Unified Multi-granularity Comprehension and Generation
Apr 22, 2024The rapid evolution of multimodal foundation model has demonstrated significant progresses in vision-language understanding and generation, e.g., our previous work SEED-LLaMA. However, there remains a gap between its capability and the real-world applicability, primarily due to the model's limited capacity to effectively respond to various user instructions and interact with diverse visual data. In this work, we focus on bridging this gap through integrating two enhanced features: (1) comprehending images of arbitrary sizes and ratios, and (2) enabling multi-granularity image generation. We present a unified and versatile foundation model, namely, SEED-X, which is able to model multi-granularity visual semantics for comprehension and generation tasks. Besides the competitive results on public benchmarks, SEED-X demonstrates its effectiveness in handling real-world applications across various domains after instruction tuning. We hope that our work will inspire future research into what can be achieved by versatile multimodal foundation models in real-world applications. The models, codes, and datasets will be released in https://github.com/AILab-CVC/SEED-X.
Leveraging Prompt-Based Large Language Models: Predicting Pandemic Health Decisions and Outcomes Through Social Media Language
Mar 01, 2024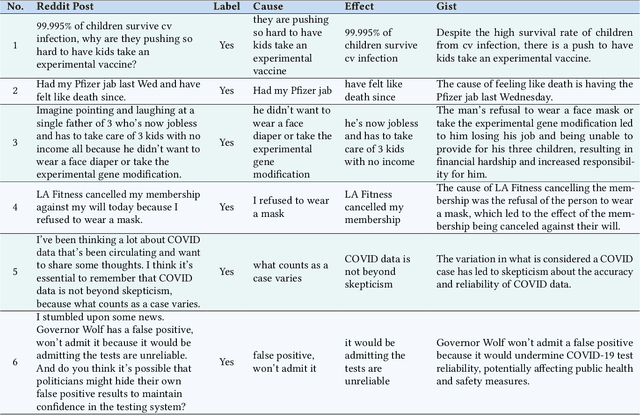
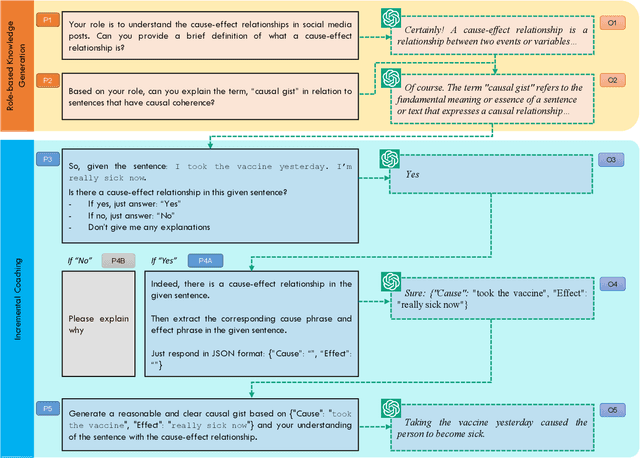
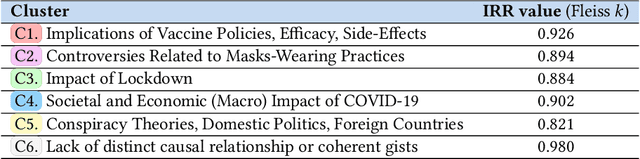
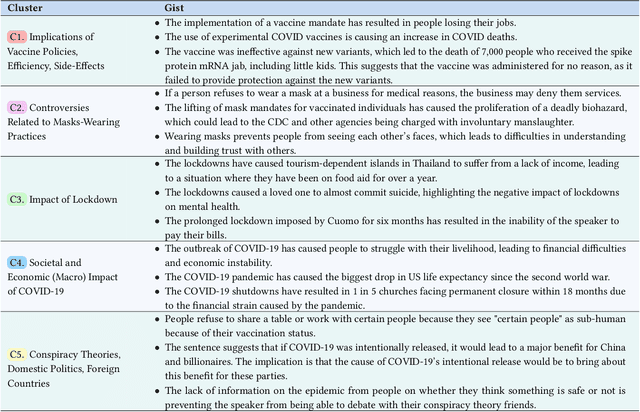
We introduce a multi-step reasoning framework using prompt-based LLMs to examine the relationship between social media language patterns and trends in national health outcomes. Grounded in fuzzy-trace theory, which emphasizes the importance of gists of causal coherence in effective health communication, we introduce Role-Based Incremental Coaching (RBIC), a prompt-based LLM framework, to identify gists at-scale. Using RBIC, we systematically extract gists from subreddit discussions opposing COVID-19 health measures (Study 1). We then track how these gists evolve across key events (Study 2) and assess their influence on online engagement (Study 3). Finally, we investigate how the volume of gists is associated with national health trends like vaccine uptake and hospitalizations (Study 4). Our work is the first to empirically link social media linguistic patterns to real-world public health trends, highlighting the potential of prompt-based LLMs in identifying critical online discussion patterns that can form the basis of public health communication strategies.
InteractiveVideo: User-Centric Controllable Video Generation with Synergistic Multimodal Instructions
Feb 05, 2024We introduce $\textit{InteractiveVideo}$, a user-centric framework for video generation. Different from traditional generative approaches that operate based on user-provided images or text, our framework is designed for dynamic interaction, allowing users to instruct the generative model through various intuitive mechanisms during the whole generation process, e.g. text and image prompts, painting, drag-and-drop, etc. We propose a Synergistic Multimodal Instruction mechanism, designed to seamlessly integrate users' multimodal instructions into generative models, thus facilitating a cooperative and responsive interaction between user inputs and the generative process. This approach enables iterative and fine-grained refinement of the generation result through precise and effective user instructions. With $\textit{InteractiveVideo}$, users are given the flexibility to meticulously tailor key aspects of a video. They can paint the reference image, edit semantics, and adjust video motions until their requirements are fully met. Code, models, and demo are available at https://github.com/invictus717/InteractiveVideo