 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Human-AI Triadic Programming: Uncovering the Role of AI Agent and the Value of Human Partner in Collaborative Learning
Jan 17, 2026As AI assistance becomes embedded in programming practice, researchers have increasingly examined how these systems help learners generate code and work more efficiently. However, these studies often position AI as a replacement for human collaboration and overlook the social and learning-oriented aspects that emerge in collaborative programming. Our work introduces human-human-AI (HHAI) triadic programming, where an AI agent serves as an additional collaborator rather than a substitute for a human partner. Through a within-subjects study with 20 participants, we show that triadic collaboration enhances collaborative learning and social presence compared to the dyadic human-AI (HAI) baseline. In the triadic HHAI conditions, participants relied significantly less on AI-generated code in their work. This effect was strongest in the HHAI-shared condition, where participants had an increased sense of responsibility to understand AI suggestions before applying them. These findings demonstrate how triadic settings activate socially shared regulation of learning by making AI use visible and accountable to a human peer, suggesting that AI systems that augment rather than automate peer collaboration can better preserve the learning processes that collaborative programming relies on.
How Managers Perceive AI-Assisted Conversational Training for Workplace Communication
May 21, 2025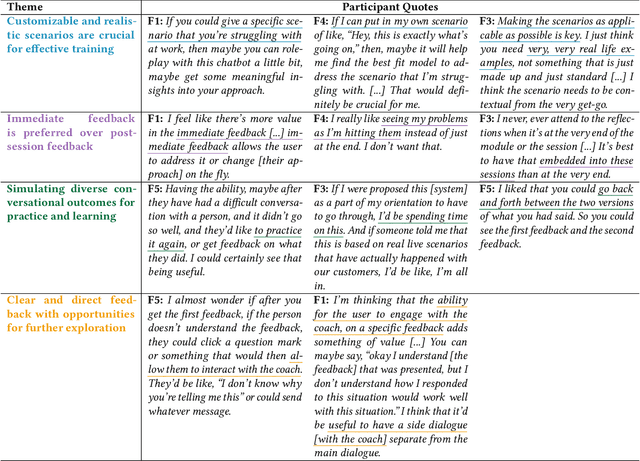
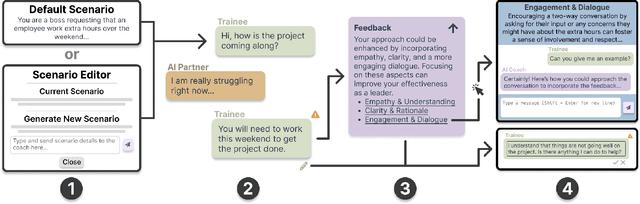
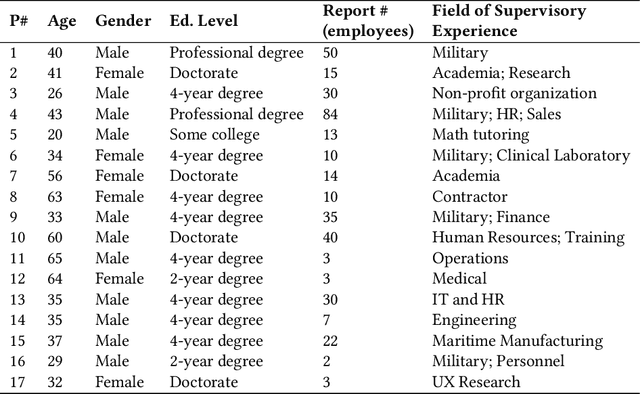
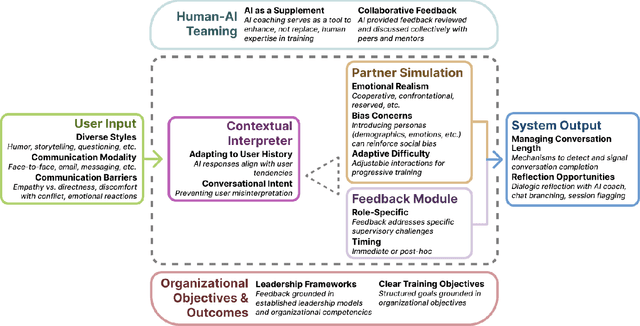
Effective workplace communication is essential for managerial success, yet many managers lack access to tailored and sustained training. Although AI-assisted communication systems may offer scalable training solutions, little is known about how managers envision the role of AI in helping them improve their communication skills. To investigate this, we designed a conversational role-play system, CommCoach, as a functional probe to understand how managers anticipate using AI to practice their communication skills. Through semi-structured interviews, participants emphasized the value of adaptive, low-risk simulations for practicing difficult workplace conversations. They also highlighted opportunities, including human-AI teaming, transparent and context-aware feedback, and greater control over AI-generated personas. AI-assisted communication training should balance personalization, structured learning objectives, and adaptability to different user styles and contexts. However, achieving this requires carefully navigating tensions between adaptive and consistent AI feedback, realism and potential bias, and the open-ended nature of AI conversations versus structured workplace discourse.
A Design Space for Intelligent and Interactive Writing Assistants
Mar 26, 2024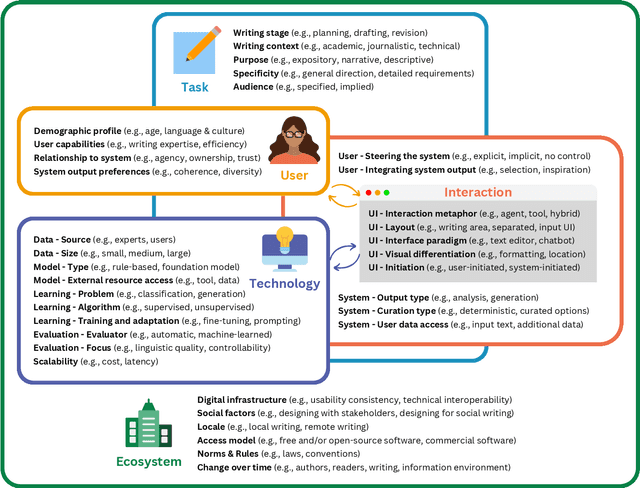
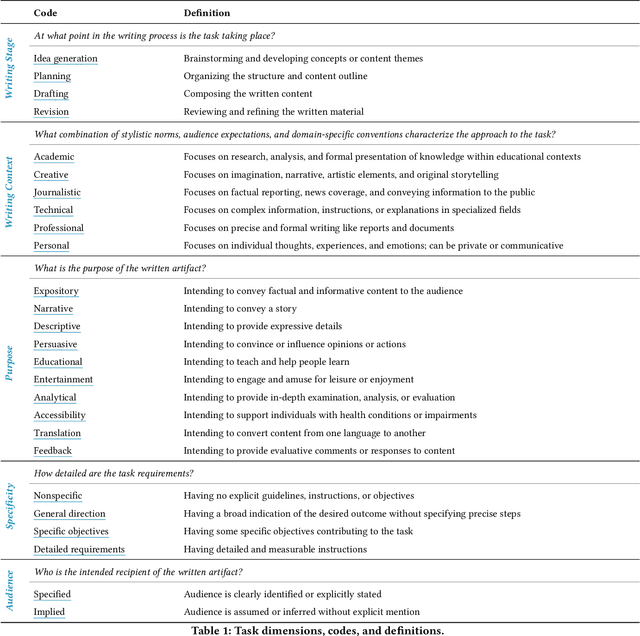
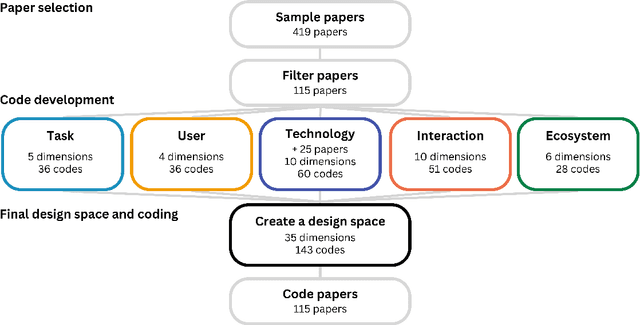
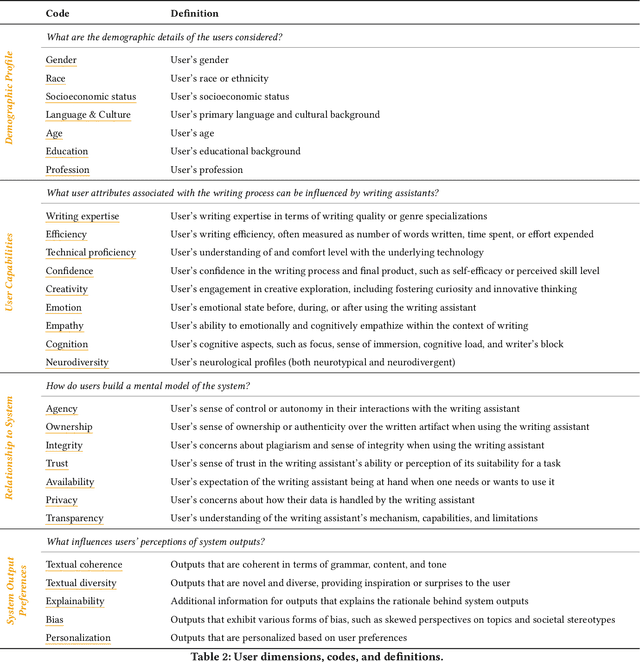
In our era of rapid technological advancement, the research landscape for writing assistants has become increasingly fragmented across various research communities. We seek to address this challenge by proposing a design space as a structured way to examine and explore the multidimensional space of intelligent and interactive writing assistants. Through a large community collaboration, we explore five aspects of writing assistants: task, user, technology, interaction, and ecosystem. Within each aspect, we define dimensions (i.e., fundamental components of an aspect) and codes (i.e., potential options for each dimension) by systematically reviewing 115 papers. Our design space aims to offer researchers and designers a practical tool to navigate, comprehend, and compare the various possibilities of writing assistants, and aid in the envisioning and design of new writing assistants.
Leveraging Prompt-Based Large Language Models: Predicting Pandemic Health Decisions and Outcomes Through Social Media Language
Mar 01, 2024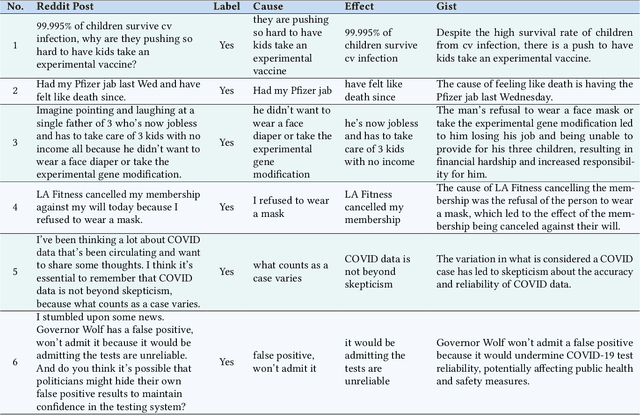
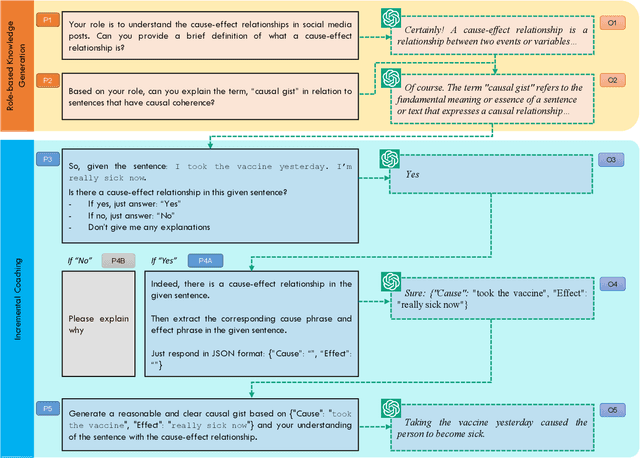
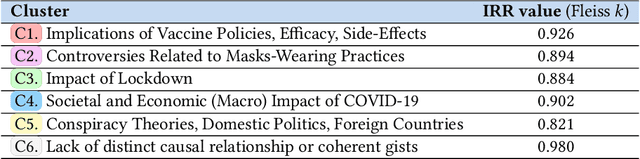
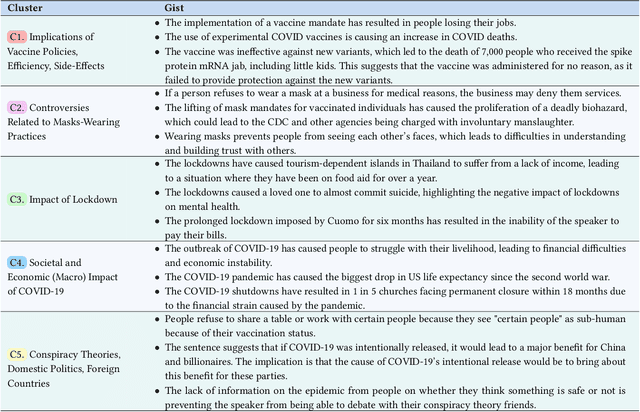
We introduce a multi-step reasoning framework using prompt-based LLMs to examine the relationship between social media language patterns and trends in national health outcomes. Grounded in fuzzy-trace theory, which emphasizes the importance of gists of causal coherence in effective health communication, we introduce Role-Based Incremental Coaching (RBIC), a prompt-based LLM framework, to identify gists at-scale. Using RBIC, we systematically extract gists from subreddit discussions opposing COVID-19 health measures (Study 1). We then track how these gists evolve across key events (Study 2) and assess their influence on online engagement (Study 3). Finally, we investigate how the volume of gists is associated with national health trends like vaccine uptake and hospitalizations (Study 4). Our work is the first to empirically link social media linguistic patterns to real-world public health trends, highlighting the potential of prompt-based LLMs in identifying critical online discussion patterns that can form the basis of public health communication strategies.
ToxVis: Enabling Interpretability of Implicit vs. Explicit Toxicity Detection Models with Interactive Visualization
Mar 01, 2023The rise of hate speech on online platforms has led to an urgent need for effective content moderation. However, the subjective and multi-faceted nature of hateful online content, including implicit hate speech, poses significant challenges to human moderators and content moderation systems. To address this issue, we developed ToxVis, a visually interactive and explainable tool for classifying hate speech into three categories: implicit, explicit, and non-hateful. We fine-tuned two transformer-based models using RoBERTa, XLNET, and GPT-3 and used deep learning interpretation techniques to provide explanations for the classification results. ToxVis enables users to input potentially hateful text and receive a classification result along with a visual explanation of which words contributed most to the decision. By making the classification process explainable, ToxVis provides a valuable tool for understanding the nuances of hateful content and supporting more effective content moderation. Our research contributes to the growing body of work aimed at mitigating the harms caused by online hate speech and demonstrates the potential for combining state-of-the-art natural language processing models with interpretable deep learning techniques to address this critical issue. Finally, ToxVis can serve as a resource for content moderators, social media platforms, and researchers working to combat the spread of hate speech online.
Same Words, Different Meanings: Semantic Polarization in Broadcast Media Language Forecasts Polarization on Social Media Discourse
Jan 25, 2023With the growth of online news over the past decade, empirical studies on political discourse and news consumption have focused on the phenomenon of filter bubbles and echo chambers. Yet recently, scholars have revealed limited evidence around the impact of such phenomenon, leading some to argue that partisan segregation across news audiences cannot be fully explained by online news consumption alone and that the role of traditional legacy media may be as salient in polarizing public discourse around current events. In this work, we expand the scope of analysis to include both online and more traditional media by investigating the relationship between broadcast news media language and social media discourse. By analyzing a decade's worth of closed captions (2 million speaker turns) from CNN and Fox News along with topically corresponding discourse from Twitter, we provide a novel framework for measuring semantic polarization between America's two major broadcast networks to demonstrate how semantic polarization between these outlets has evolved (Study 1), peaked (Study 2) and influenced partisan discussions on Twitter (Study 3) across the last decade. Our results demonstrate a sharp increase in polarization in how topically important keywords are discussed between the two channels, especially after 2016, with overall highest peaks occurring in 2020. The two stations discuss identical topics in drastically distinct contexts in 2020, to the extent that there is barely any linguistic overlap in how identical keywords are contextually discussed. Further, we demonstrate at scale, how such partisan division in broadcast media language significantly shapes semantic polarity trends on Twitter (and vice-versa), empirically linking for the first time, how online discussions are influenced by televised media.