 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClaw-Anything: Benchmarking Always-On Personal Assistants with Broader Access to User's Digital World
May 25, 2026Large language model agents are increasingly envisioned as always-on personal assistants with access to anything relevant in the user's digital world. Yet current systems operate over only narrow slices of that world, limiting context-sensitive reasoning and effective assistance. Existing benchmarks similarly provide only partial user state and therefore fail to capture performance in such a broad, always-on setting. To address this gap, we introduce Claw-Anything, a benchmark that expands agent context along three dimensions: long-horizon activity histories, interdependent backend services, and integrated GUI and CLI interaction across multiple devices. To instantiate this setting, we simulate months of user activity through multi-round event injection, producing complex world states and realistic noise, including irrelevant events and conflicting signals. Agents must reason over rich contextual environments while remaining robust to such noise. This expanded scope also enables the evaluation of proactive assistance, requiring agents to anticipate user needs and deliver timely recommendations. Experiments show that GPT-5.5 achieves only 34.5% pass@1, substantially below prior benchmarks, underscoring a gap between current agent capabilities and the demands of always-on personal assistance. Alongside the benchmark, we release an automated data-generation pipeline that yields 2,000 training environments and improves the base model by 23.7%, demonstrating its utility of scalable data infrastructure.
CLI-Gym: Scalable CLI Task Generation via Agentic Environment Inversion
Feb 11, 2026Agentic coding requires agents to effectively interact with runtime environments, e.g., command line interfaces (CLI), so as to complete tasks like resolving dependency issues, fixing system problems, etc. But it remains underexplored how such environment-intensive tasks can be obtained at scale to enhance agents' capabilities. To address this, based on an analogy between the Dockerfile and the agentic task, we propose to employ agents to simulate and explore environment histories, guided by execution feedback. By tracing histories of a healthy environment, its state can be inverted to an earlier one with runtime failures, from which a task can be derived by packing the buggy state and the corresponding error messages. With our method, named CLI-Gym, a total of 1,655 environment-intensive tasks are derived, being the largest collection of its kind. Moreover, with curated successful trajectories, our fine-tuned model, named LiberCoder, achieves substantial absolute improvements of +21.1% (to 46.1%) on Terminal-Bench, outperforming various strong baselines. To our knowledge, this is the first public pipeline for scalable derivation of environment-intensive tasks.
World knowledge-enhanced Reasoning Using Instruction-guided Interactor in Autonomous Driving
Dec 09, 2024



The Multi-modal Large Language Models (MLLMs) with extensive world knowledge have revitalized autonomous driving, particularly in reasoning tasks within perceivable regions. However, when faced with perception-limited areas (dynamic or static occlusion regions), MLLMs struggle to effectively integrate perception ability with world knowledge for reasoning. These perception-limited regions can conceal crucial safety information, especially for vulnerable road users. In this paper, we propose a framework, which aims to improve autonomous driving performance under perceptionlimited conditions by enhancing the integration of perception capabilities and world knowledge. Specifically, we propose a plug-and-play instruction-guided interaction module that bridges modality gaps and significantly reduces the input sequence length, allowing it to adapt effectively to multi-view video inputs. Furthermore, to better integrate world knowledge with driving-related tasks, we have collected and refined a large-scale multi-modal dataset that includes 2 million natural language QA pairs, 1.7 million grounding task data. To evaluate the model's utilization of world knowledge, we introduce an object-level risk assessment dataset comprising 200K QA pairs, where the questions necessitate multi-step reasoning leveraging world knowledge for resolution. Extensive experiments validate the effectiveness of our proposed method.
RepVF: A Unified Vector Fields Representation for Multi-task 3D Perception
Jul 15, 2024Concurrent processing of multiple autonomous driving 3D perception tasks within the same spatiotemporal scene poses a significant challenge, in particular due to the computational inefficiencies and feature competition between tasks when using traditional multi-task learning approaches. This paper addresses these issues by proposing a novel unified representation, RepVF, which harmonizes the representation of various perception tasks such as 3D object detection and 3D lane detection within a single framework. RepVF characterizes the structure of different targets in the scene through a vector field, enabling a single-head, multi-task learning model that significantly reduces computational redundancy and feature competition. Building upon RepVF, we introduce RFTR, a network designed to exploit the inherent connections between different tasks by utilizing a hierarchical structure of queries that implicitly model the relationships both between and within tasks. This approach eliminates the need for task-specific heads and parameters, fundamentally reducing the conflicts inherent in traditional multi-task learning paradigms. We validate our approach by combining labels from the OpenLane dataset with the Waymo Open dataset. Our work presents a significant advancement in the efficiency and effectiveness of multi-task perception in autonomous driving, offering a new perspective on handling multiple 3D perception tasks synchronously and in parallel. The code will be available at: https://github.com/jbji/RepVF
InteractiveVideo: User-Centric Controllable Video Generation with Synergistic Multimodal Instructions
Feb 05, 2024We introduce $\textit{InteractiveVideo}$, a user-centric framework for video generation. Different from traditional generative approaches that operate based on user-provided images or text, our framework is designed for dynamic interaction, allowing users to instruct the generative model through various intuitive mechanisms during the whole generation process, e.g. text and image prompts, painting, drag-and-drop, etc. We propose a Synergistic Multimodal Instruction mechanism, designed to seamlessly integrate users' multimodal instructions into generative models, thus facilitating a cooperative and responsive interaction between user inputs and the generative process. This approach enables iterative and fine-grained refinement of the generation result through precise and effective user instructions. With $\textit{InteractiveVideo}$, users are given the flexibility to meticulously tailor key aspects of a video. They can paint the reference image, edit semantics, and adjust video motions until their requirements are fully met. Code, models, and demo are available at https://github.com/invictus717/InteractiveVideo
TextFormer: A Query-based End-to-End Text Spotter with Mixed Supervision
Jun 06, 2023End-to-end text spotting is a vital computer vision task that aims to integrate scene text detection and recognition into a unified framework. Typical methods heavily rely on Region-of-Interest (RoI) operations to extract local features and complex post-processing steps to produce final predictions. To address these limitations, we propose TextFormer, a query-based end-to-end text spotter with Transformer architecture. Specifically, using query embedding per text instance, TextFormer builds upon an image encoder and a text decoder to learn a joint semantic understanding for multi-task modeling. It allows for mutual training and optimization of classification, segmentation, and recognition branches, resulting in deeper feature sharing without sacrificing flexibility or simplicity. Additionally, we design an Adaptive Global aGgregation (AGG) module to transfer global features into sequential features for reading arbitrarily-shaped texts, which overcomes the sub-optimization problem of RoI operations. Furthermore, potential corpus information is utilized from weak annotations to full labels through mixed supervision, further improving text detection and end-to-end text spotting results. Extensive experiments on various bilingual (i.e., English and Chinese) benchmarks demonstrate the superiority of our method. Especially on TDA-ReCTS dataset, TextFormer surpasses the state-of-the-art method in terms of 1-NED by 13.2%.
Generalized Few-Shot 3D Object Detection of LiDAR Point Cloud for Autonomous Driving
Feb 08, 2023Recent years have witnessed huge successes in 3D object detection to recognize common objects for autonomous driving (e.g., vehicles and pedestrians). However, most methods rely heavily on a large amount of well-labeled training data. This limits their capability of detecting rare fine-grained objects (e.g., police cars and ambulances), which is important for special cases, such as emergency rescue, and so on. To achieve simultaneous detection for both common and rare objects, we propose a novel task, called generalized few-shot 3D object detection, where we have a large amount of training data for common (base) objects, but only a few data for rare (novel) classes. Specifically, we analyze in-depth differences between images and point clouds, and then present a practical principle for the few-shot setting in the 3D LiDAR dataset. To solve this task, we propose a simple and effective detection framework, including (1) an incremental fine-tuning method to extend existing 3D detection models to recognize both common and rare objects, and (2) a sample adaptive balance loss to alleviate the issue of long-tailed data distribution in autonomous driving scenarios. On the nuScenes dataset, we conduct sufficient experiments to demonstrate that our approach can successfully detect the rare (novel) classes that contain only a few training data, while also maintaining the detection accuracy of common objects.
Bilateral Cross-Modality Graph Matching Attention for Feature Fusion in Visual Question Answering
Dec 14, 2021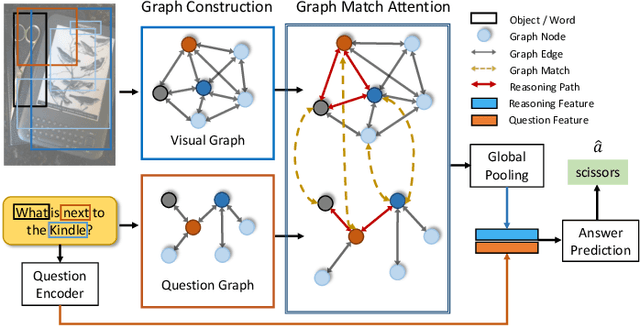
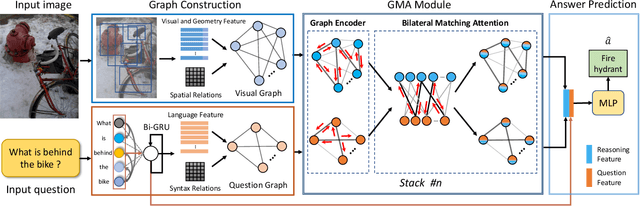
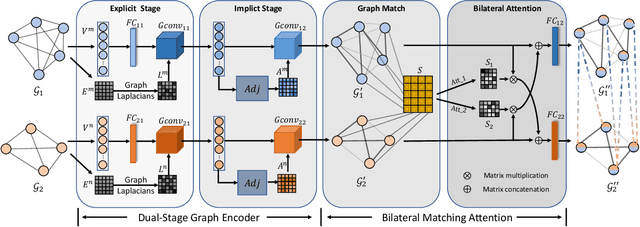
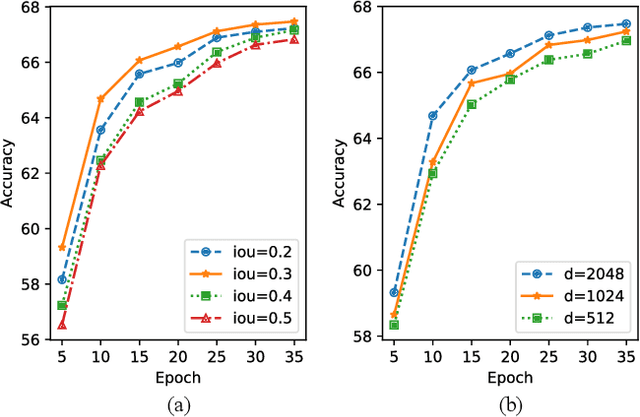
Answering semantically-complicated questions according to an image is challenging in Visual Question Answering (VQA) task. Although the image can be well represented by deep learning, the question is always simply embedded and cannot well indicate its meaning. Besides, the visual and textual features have a gap for different modalities, it is difficult to align and utilize the cross-modality information. In this paper, we focus on these two problems and propose a Graph Matching Attention (GMA) network. Firstly, it not only builds graph for the image, but also constructs graph for the question in terms of both syntactic and embedding information. Next, we explore the intra-modality relationships by a dual-stage graph encoder and then present a bilateral cross-modality graph matching attention to infer the relationships between the image and the question. The updated cross-modality features are then sent into the answer prediction module for final answer prediction. Experiments demonstrate that our network achieves state-of-the-art performance on the GQA dataset and the VQA 2.0 dataset. The ablation studies verify the effectiveness of each modules in our GMA network.
Self-Learning with Rectification Strategy for Human Parsing
Apr 17, 2020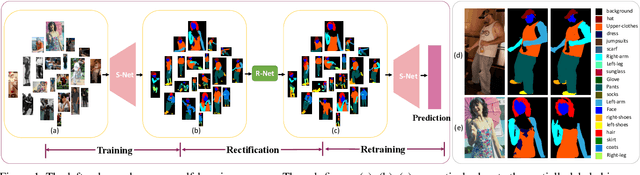
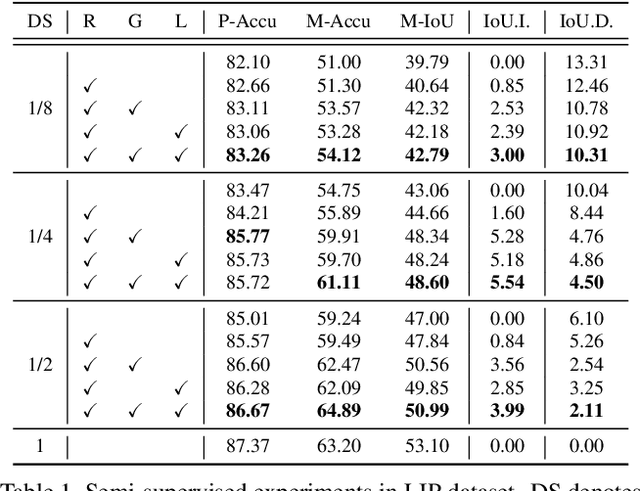
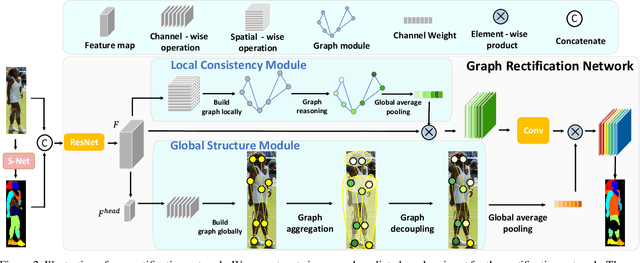
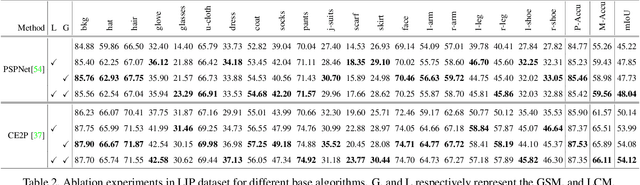
In this paper, we solve the sample shortage problem in the human parsing task. We begin with the self-learning strategy, which generates pseudo-labels for unlabeled data to retrain the model. However, directly using noisy pseudo-labels will cause error amplification and accumulation. Considering the topology structure of human body, we propose a trainable graph reasoning method that establishes internal structural connections between graph nodes to correct two typical errors in the pseudo-labels, i.e., the global structural error and the local consistency error. For the global error, we first transform category-wise features into a high-level graph model with coarse-grained structural information, and then decouple the high-level graph to reconstruct the category features. The reconstructed features have a stronger ability to represent the topology structure of the human body. Enlarging the receptive field of features can effectively reducing the local error. We first project feature pixels into a local graph model to capture pixel-wise relations in a hierarchical graph manner, then reverse the relation information back to the pixels. With the global structural and local consistency modules, these errors are rectified and confident pseudo-labels are generated for retraining. Extensive experiments on the LIP and the ATR datasets demonstrate the effectiveness of our global and local rectification modules. Our method outperforms other state-of-the-art methods in supervised human parsing tasks.
Improved Face Detection and Alignment using Cascade Deep Convolutional Network
Jul 28, 2017

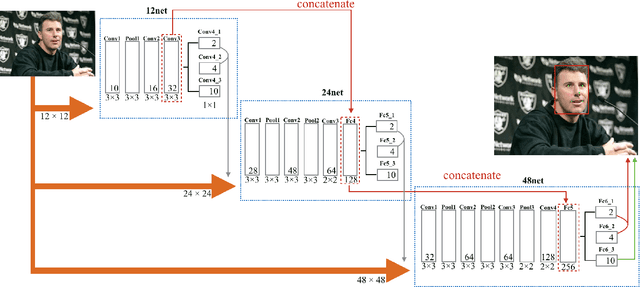

Real-world face detection and alignment demand an advanced discriminative model to address challenges by pose, lighting and expression. Illuminated by the deep learning algorithm, some convolutional neural networks based face detection and alignment methods have been proposed. Recent studies have utilized the relation between face detection and alignment to make models computationally efficiency, however they ignore the connection between each cascade CNNs. In this paper, we propose an structure to propose higher quality training data for End-to-End cascade network training, which give computers more space to automatic adjust weight parameter and accelerate convergence. Experiments demonstrate considerable improvement over existing detection and alignment models.