 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld knowledge-enhanced Reasoning Using Instruction-guided Interactor in Autonomous Driving
Dec 09, 2024The Multi-modal Large Language Models (MLLMs) with extensive world knowledge have revitalized autonomous driving, particularly in reasoning tasks within perceivable regions. However, when faced with perception-limited areas (dynamic or static occlusion regions), MLLMs struggle to effectively integrate perception ability with world knowledge for reasoning. These perception-limited regions can conceal crucial safety information, especially for vulnerable road users. In this paper, we propose a framework, which aims to improve autonomous driving performance under perceptionlimited conditions by enhancing the integration of perception capabilities and world knowledge. Specifically, we propose a plug-and-play instruction-guided interaction module that bridges modality gaps and significantly reduces the input sequence length, allowing it to adapt effectively to multi-view video inputs. Furthermore, to better integrate world knowledge with driving-related tasks, we have collected and refined a large-scale multi-modal dataset that includes 2 million natural language QA pairs, 1.7 million grounding task data. To evaluate the model's utilization of world knowledge, we introduce an object-level risk assessment dataset comprising 200K QA pairs, where the questions necessitate multi-step reasoning leveraging world knowledge for resolution. Extensive experiments validate the effectiveness of our proposed method.
Seeing Beyond Views: Multi-View Driving Scene Video Generation with Holistic Attention
Dec 04, 2024Generating multi-view videos for autonomous driving training has recently gained much attention, with the challenge of addressing both cross-view and cross-frame consistency. Existing methods typically apply decoupled attention mechanisms for spatial, temporal, and view dimensions. However, these approaches often struggle to maintain consistency across dimensions, particularly when handling fast-moving objects that appear at different times and viewpoints. In this paper, we present CogDriving, a novel network designed for synthesizing high-quality multi-view driving videos. CogDriving leverages a Diffusion Transformer architecture with holistic-4D attention modules, enabling simultaneous associations across the spatial, temporal, and viewpoint dimensions. We also propose a lightweight controller tailored for CogDriving, i.e., Micro-Controller, which uses only 1.1% of the parameters of the standard ControlNet, enabling precise control over Bird's-Eye-View layouts. To enhance the generation of object instances crucial for autonomous driving, we propose a re-weighted learning objective, dynamically adjusting the learning weights for object instances during training. CogDriving demonstrates strong performance on the nuScenes validation set, achieving an FVD score of 37.8, highlighting its ability to generate realistic driving videos. The project can be found at https://luhannan.github.io/CogDrivingPage/.
Collaborative Position Reasoning Network for Referring Image Segmentation
Jan 22, 2024Given an image and a natural language expression as input, the goal of referring image segmentation is to segment the foreground masks of the entities referred by the expression. Existing methods mainly focus on interactive learning between vision and language to enhance the multi-modal representations for global context reasoning. However, predicting directly in pixel-level space can lead to collapsed positioning and poor segmentation results. Its main challenge lies in how to explicitly model entity localization, especially for non-salient entities. In this paper, we tackle this problem by executing a Collaborative Position Reasoning Network (CPRN) via the proposed novel Row-and-Column interactive (RoCo) and Guided Holistic interactive (Holi) modules. Specifically, RoCo aggregates the visual features into the row- and column-wise features corresponding two directional axes respectively. It offers a fine-grained matching behavior that perceives the associations between the linguistic features and two decoupled visual features to perform position reasoning over a hierarchical space. Holi integrates features of the two modalities by a cross-modal attention mechanism, which suppresses the irrelevant redundancy under the guide of positioning information from RoCo. Thus, with the incorporation of RoCo and Holi modules, CPRN captures the visual details of position reasoning so that the model can achieve more accurate segmentation. To our knowledge, this is the first work that explicitly focuses on position reasoning modeling. We also validate the proposed method on three evaluation datasets. It consistently outperforms existing state-of-the-art methods.
MataDoc: Margin and Text Aware Document Dewarping for Arbitrary Boundary
Jul 24, 2023Document dewarping from a distorted camera-captured image is of great value for OCR and document understanding. The document boundary plays an important role which is more evident than the inner region in document dewarping. Current learning-based methods mainly focus on complete boundary cases, leading to poor document correction performance of documents with incomplete boundaries. In contrast to these methods, this paper proposes MataDoc, the first method focusing on arbitrary boundary document dewarping with margin and text aware regularizations. Specifically, we design the margin regularization by explicitly considering background consistency to enhance boundary perception. Moreover, we introduce word position consistency to keep text lines straight in rectified document images. To produce a comprehensive evaluation of MataDoc, we propose a novel benchmark ArbDoc, mainly consisting of document images with arbitrary boundaries in four typical scenarios. Extensive experiments confirm the superiority of MataDoc with consideration for the incomplete boundary on ArbDoc and also demonstrate the effectiveness of the proposed method on DocUNet, DIR300, and WarpDoc datasets.
TextFormer: A Query-based End-to-End Text Spotter with Mixed Supervision
Jun 06, 2023End-to-end text spotting is a vital computer vision task that aims to integrate scene text detection and recognition into a unified framework. Typical methods heavily rely on Region-of-Interest (RoI) operations to extract local features and complex post-processing steps to produce final predictions. To address these limitations, we propose TextFormer, a query-based end-to-end text spotter with Transformer architecture. Specifically, using query embedding per text instance, TextFormer builds upon an image encoder and a text decoder to learn a joint semantic understanding for multi-task modeling. It allows for mutual training and optimization of classification, segmentation, and recognition branches, resulting in deeper feature sharing without sacrificing flexibility or simplicity. Additionally, we design an Adaptive Global aGgregation (AGG) module to transfer global features into sequential features for reading arbitrarily-shaped texts, which overcomes the sub-optimization problem of RoI operations. Furthermore, potential corpus information is utilized from weak annotations to full labels through mixed supervision, further improving text detection and end-to-end text spotting results. Extensive experiments on various bilingual (i.e., English and Chinese) benchmarks demonstrate the superiority of our method. Especially on TDA-ReCTS dataset, TextFormer surpasses the state-of-the-art method in terms of 1-NED by 13.2%.
Fast-StrucTexT: An Efficient Hourglass Transformer with Modality-guided Dynamic Token Merge for Document Understanding
May 19, 2023Transformers achieve promising performance in document understanding because of their high effectiveness and still suffer from quadratic computational complexity dependency on the sequence length. General efficient transformers are challenging to be directly adapted to model document. They are unable to handle the layout representation in documents, e.g. word, line and paragraph, on different granularity levels and seem hard to achieve a good trade-off between efficiency and performance. To tackle the concerns, we propose Fast-StrucTexT, an efficient multi-modal framework based on the StrucTexT algorithm with an hourglass transformer architecture, for visual document understanding. Specifically, we design a modality-guided dynamic token merging block to make the model learn multi-granularity representation and prunes redundant tokens. Additionally, we present a multi-modal interaction module called Symmetry Cross Attention (SCA) to consider multi-modal fusion and efficiently guide the token mergence. The SCA allows one modality input as query to calculate cross attention with another modality in a dual phase. Extensive experiments on FUNSD, SROIE, and CORD datasets demonstrate that our model achieves the state-of-the-art performance and almost 1.9X faster inference time than the state-of-the-art methods.
StrucTexTv2: Masked Visual-Textual Prediction for Document Image Pre-training
Mar 01, 2023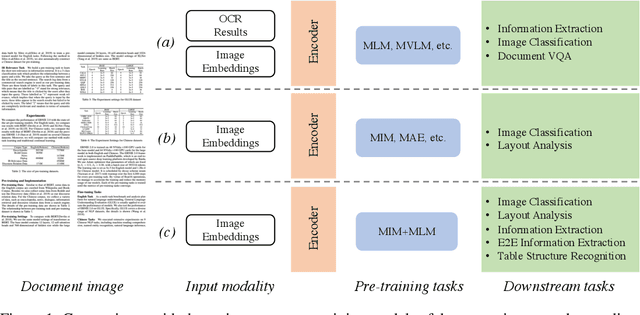
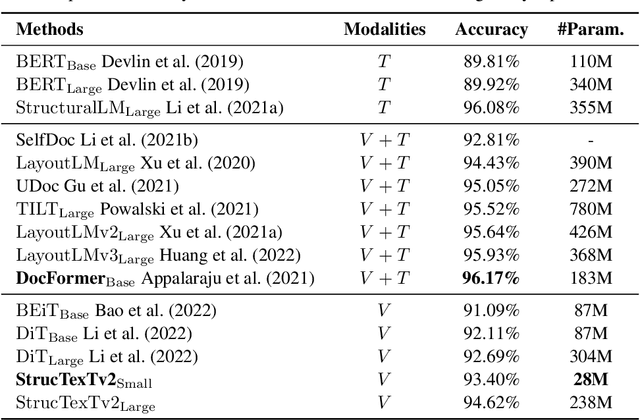
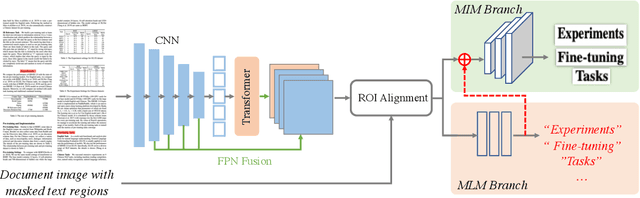

In this paper, we present StrucTexTv2, an effective document image pre-training framework, by performing masked visual-textual prediction. It consists of two self-supervised pre-training tasks: masked image modeling and masked language modeling, based on text region-level image masking. The proposed method randomly masks some image regions according to the bounding box coordinates of text words. The objectives of our pre-training tasks are reconstructing the pixels of masked image regions and the corresponding masked tokens simultaneously. Hence the pre-trained encoder can capture more textual semantics in comparison to the masked image modeling that usually predicts the masked image patches. Compared to the masked multi-modal modeling methods for document image understanding that rely on both the image and text modalities, StrucTexTv2 models image-only input and potentially deals with more application scenarios free from OCR pre-processing. Extensive experiments on mainstream benchmarks of document image understanding demonstrate the effectiveness of StrucTexTv2. It achieves competitive or even new state-of-the-art performance in various downstream tasks such as image classification, layout analysis, table structure recognition, document OCR, and information extraction under the end-to-end scenario.
Bilateral Cross-Modality Graph Matching Attention for Feature Fusion in Visual Question Answering
Dec 14, 2021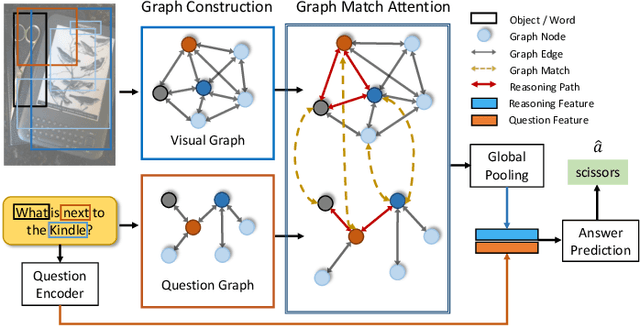
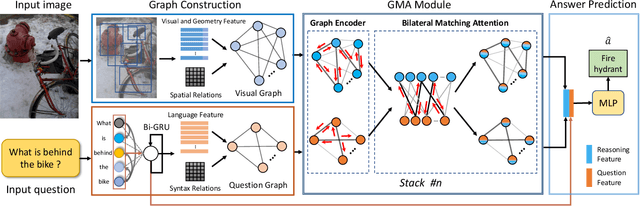
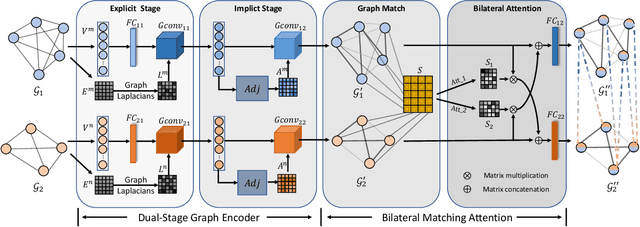
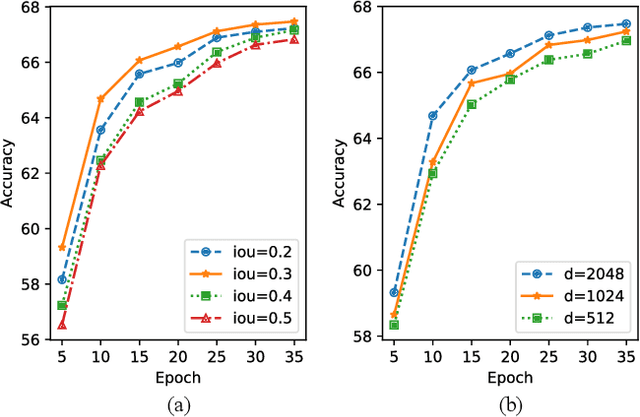
Answering semantically-complicated questions according to an image is challenging in Visual Question Answering (VQA) task. Although the image can be well represented by deep learning, the question is always simply embedded and cannot well indicate its meaning. Besides, the visual and textual features have a gap for different modalities, it is difficult to align and utilize the cross-modality information. In this paper, we focus on these two problems and propose a Graph Matching Attention (GMA) network. Firstly, it not only builds graph for the image, but also constructs graph for the question in terms of both syntactic and embedding information. Next, we explore the intra-modality relationships by a dual-stage graph encoder and then present a bilateral cross-modality graph matching attention to infer the relationships between the image and the question. The updated cross-modality features are then sent into the answer prediction module for final answer prediction. Experiments demonstrate that our network achieves state-of-the-art performance on the GQA dataset and the VQA 2.0 dataset. The ablation studies verify the effectiveness of each modules in our GMA network.
StrucTexT: Structured Text Understanding with Multi-Modal Transformers
Aug 10, 2021
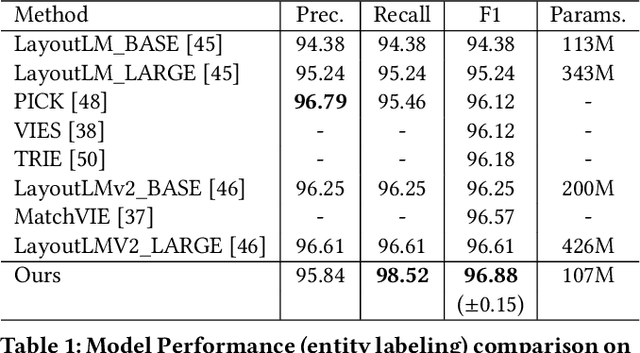
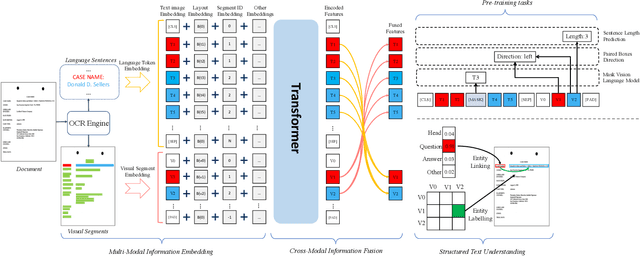
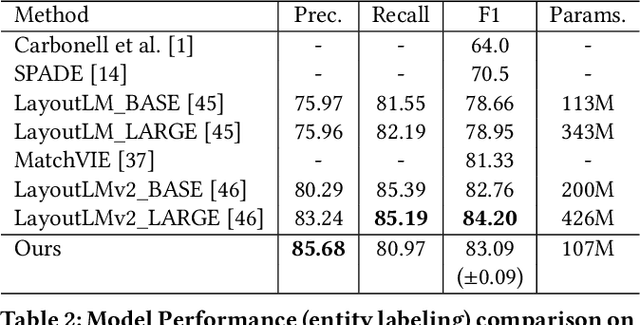
Structured text understanding on Visually Rich Documents (VRDs) is a crucial part of Document Intelligence. Due to the complexity of content and layout in VRDs, structured text understanding has been a challenging task. Most existing studies decoupled this problem into two sub-tasks: entity labeling and entity linking, which require an entire understanding of the context of documents at both token and segment levels. However, little work has been concerned with the solutions that efficiently extract the structured data from different levels. This paper proposes a unified framework named StrucTexT, which is flexible and effective for handling both sub-tasks. Specifically, based on the transformer, we introduce a segment-token aligned encoder to deal with the entity labeling and entity linking tasks at different levels of granularity. Moreover, we design a novel pre-training strategy with three self-supervised tasks to learn a richer representation. StrucTexT uses the existing Masked Visual Language Modeling task and the new Sentence Length Prediction and Paired Boxes Direction tasks to incorporate the multi-modal information across text, image, and layout. We evaluate our method for structured text understanding at segment-level and token-level and show it outperforms the state-of-the-art counterparts with significantly superior performance on the FUNSD, SROIE, and EPHOIE datasets.
EATEN: Entity-aware Attention for Single Shot Visual Text Extraction
Sep 20, 2019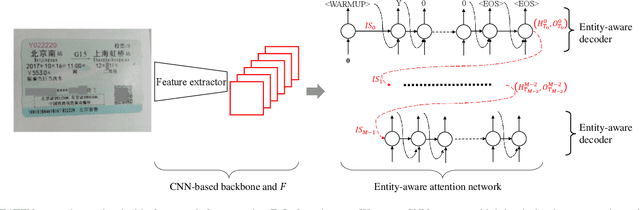
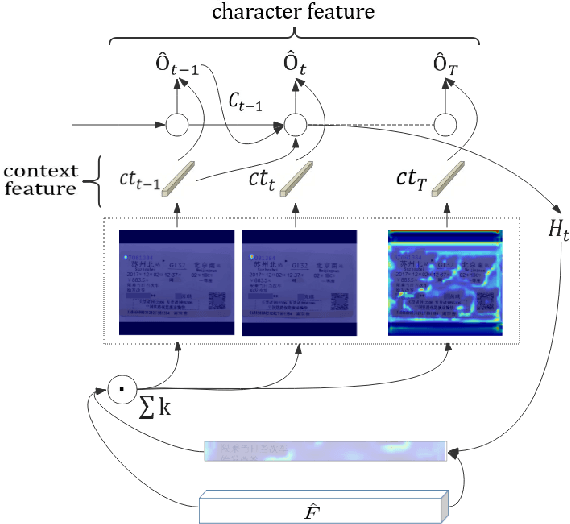


Extracting entity from images is a crucial part of many OCR applications, such as entity recognition of cards, invoices, and receipts. Most of the existing works employ classical detection and recognition paradigm. This paper proposes an Entity-aware Attention Text Extraction Network called EATEN, which is an end-to-end trainable system to extract the entities without any post-processing. In the proposed framework, each entity is parsed by its corresponding entity-aware decoder, respectively. Moreover, we innovatively introduce a state transition mechanism which further improves the robustness of entity extraction. In consideration of the absence of public benchmarks, we construct a dataset of almost 0.6 million images in three real-world scenarios (train ticket, passport and business card), which is publicly available at https://github.com/beacandler/EATEN. To the best of our knowledge, EATEN is the first single shot method to extract entities from images. Extensive experiments on these benchmarks demonstrate the state-of-the-art performance of EATEN.