 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKaLM: Knowledge-aligned Autoregressive Language Modeling via Dual-view Knowledge Graph Contrastive Learning
Dec 06, 2024Autoregressive large language models (LLMs) pre-trained by next token prediction are inherently proficient in generative tasks. However, their performance on knowledge-driven tasks such as factual knowledge querying remains unsatisfactory. Knowledge graphs (KGs), as high-quality structured knowledge bases, can provide reliable knowledge for LLMs, potentially compensating for their knowledge deficiencies. Aligning LLMs with explicit, structured knowledge from KGs has been a challenge; previous attempts either failed to effectively align knowledge representations or compromised the generative capabilities of LLMs, leading to less-than-optimal outcomes. This paper proposes \textbf{KaLM}, a \textit{Knowledge-aligned Language Modeling} approach, which fine-tunes autoregressive LLMs to align with KG knowledge via the joint objective of explicit knowledge alignment and implicit knowledge alignment. The explicit knowledge alignment objective aims to directly optimize the knowledge representation of LLMs through dual-view knowledge graph contrastive learning. The implicit knowledge alignment objective focuses on incorporating textual patterns of knowledge into LLMs through triple completion language modeling. Notably, our method achieves a significant performance boost in evaluations of knowledge-driven tasks, specifically embedding-based knowledge graph completion and generation-based knowledge graph question answering.
Collaborative Position Reasoning Network for Referring Image Segmentation
Jan 22, 2024Given an image and a natural language expression as input, the goal of referring image segmentation is to segment the foreground masks of the entities referred by the expression. Existing methods mainly focus on interactive learning between vision and language to enhance the multi-modal representations for global context reasoning. However, predicting directly in pixel-level space can lead to collapsed positioning and poor segmentation results. Its main challenge lies in how to explicitly model entity localization, especially for non-salient entities. In this paper, we tackle this problem by executing a Collaborative Position Reasoning Network (CPRN) via the proposed novel Row-and-Column interactive (RoCo) and Guided Holistic interactive (Holi) modules. Specifically, RoCo aggregates the visual features into the row- and column-wise features corresponding two directional axes respectively. It offers a fine-grained matching behavior that perceives the associations between the linguistic features and two decoupled visual features to perform position reasoning over a hierarchical space. Holi integrates features of the two modalities by a cross-modal attention mechanism, which suppresses the irrelevant redundancy under the guide of positioning information from RoCo. Thus, with the incorporation of RoCo and Holi modules, CPRN captures the visual details of position reasoning so that the model can achieve more accurate segmentation. To our knowledge, this is the first work that explicitly focuses on position reasoning modeling. We also validate the proposed method on three evaluation datasets. It consistently outperforms existing state-of-the-art methods.
GeoGalactica: A Scientific Large Language Model in Geoscience
Dec 31, 2023

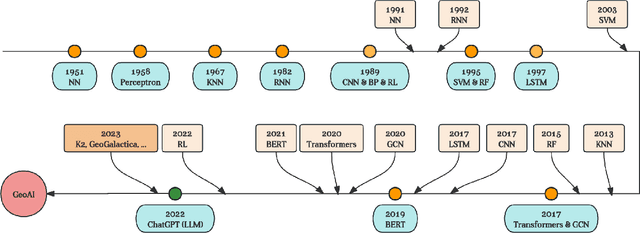
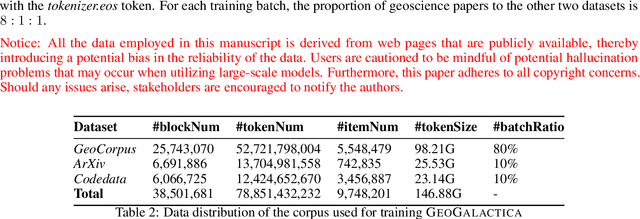
Large language models (LLMs) have achieved huge success for their general knowledge and ability to solve a wide spectrum of tasks in natural language processing (NLP). Due to their impressive abilities, LLMs have shed light on potential inter-discipline applications to foster scientific discoveries of a specific domain by using artificial intelligence (AI for science, AI4S). In the meantime, utilizing NLP techniques in geoscience research and practice is wide and convoluted, contributing from knowledge extraction and document classification to question answering and knowledge discovery. In this work, we take the initial step to leverage LLM for science, through a rather straightforward approach. We try to specialize an LLM into geoscience, by further pre-training the model with a vast amount of texts in geoscience, as well as supervised fine-tuning (SFT) the resulting model with our custom collected instruction tuning dataset. These efforts result in a model GeoGalactica consisting of 30 billion parameters. To our best knowledge, it is the largest language model for the geoscience domain. More specifically, GeoGalactica is from further pre-training of Galactica. We train GeoGalactica over a geoscience-related text corpus containing 65 billion tokens curated from extensive data sources in the big science project Deep-time Digital Earth (DDE), preserving as the largest geoscience-specific text corpus. Then we fine-tune the model with 1 million pairs of instruction-tuning data consisting of questions that demand professional geoscience knowledge to answer. In this technical report, we will illustrate in detail all aspects of GeoGalactica, including data collection, data cleaning, base model selection, pre-training, SFT, and evaluation. We open-source our data curation tools and the checkpoints of GeoGalactica during the first 3/4 of pre-training.
MataDoc: Margin and Text Aware Document Dewarping for Arbitrary Boundary
Jul 24, 2023Document dewarping from a distorted camera-captured image is of great value for OCR and document understanding. The document boundary plays an important role which is more evident than the inner region in document dewarping. Current learning-based methods mainly focus on complete boundary cases, leading to poor document correction performance of documents with incomplete boundaries. In contrast to these methods, this paper proposes MataDoc, the first method focusing on arbitrary boundary document dewarping with margin and text aware regularizations. Specifically, we design the margin regularization by explicitly considering background consistency to enhance boundary perception. Moreover, we introduce word position consistency to keep text lines straight in rectified document images. To produce a comprehensive evaluation of MataDoc, we propose a novel benchmark ArbDoc, mainly consisting of document images with arbitrary boundaries in four typical scenarios. Extensive experiments confirm the superiority of MataDoc with consideration for the incomplete boundary on ArbDoc and also demonstrate the effectiveness of the proposed method on DocUNet, DIR300, and WarpDoc datasets.