 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing large language models to produce literature reviews: Usages and systematic biases of microphysics parametrizations in 2699 publications
Mar 27, 2025Large language models afford opportunities for using computers for intensive tasks, realizing research opportunities that have not been considered before. One such opportunity could be a systematic interrogation of the scientific literature. Here, we show how a large language model can be used to construct a literature review of 2699 publications associated with microphysics parametrizations in the Weather and Research Forecasting (WRF) model, with the goal of learning how they were used and their systematic biases, when simulating precipitation. The database was constructed of publications identified from Web of Science and Scopus searches. The large language model GPT-4 Turbo was used to extract information about model configurations and performance from the text of 2699 publications. Our results reveal the landscape of how nine of the most popular microphysics parameterizations have been used around the world: Lin, Ferrier, WRF Single-Moment, Goddard Cumulus Ensemble, Morrison, Thompson, and WRF Double-Moment. More studies used one-moment parameterizations before 2020 and two-moment parameterizations after 2020. Seven out of nine parameterizations tended to overestimate precipitation. However, systematic biases of parameterizations differed in various regions. Except simulations using the Lin, Ferrier, and Goddard parameterizations that tended to underestimate precipitation over almost all locations, the remaining six parameterizations tended to overestimate, particularly over China, southeast Asia, western United States, and central Africa. This method could be used by other researchers to help understand how the increasingly massive body of scientific literature can be harnessed through the power of artificial intelligence to solve their research problems.
ECon: On the Detection and Resolution of Evidence Conflicts
Oct 05, 2024



The rise of large language models (LLMs) has significantly influenced the quality of information in decision-making systems, leading to the prevalence of AI-generated content and challenges in detecting misinformation and managing conflicting information, or "inter-evidence conflicts." This study introduces a method for generating diverse, validated evidence conflicts to simulate real-world misinformation scenarios. We evaluate conflict detection methods, including Natural Language Inference (NLI) models, factual consistency (FC) models, and LLMs, on these conflicts (RQ1) and analyze LLMs' conflict resolution behaviors (RQ2). Our key findings include: (1) NLI and LLM models exhibit high precision in detecting answer conflicts, though weaker models suffer from low recall; (2) FC models struggle with lexically similar answer conflicts, while NLI and LLM models handle these better; and (3) stronger models like GPT-4 show robust performance, especially with nuanced conflicts. For conflict resolution, LLMs often favor one piece of conflicting evidence without justification and rely on internal knowledge if they have prior beliefs.
RAGChecker: A Fine-grained Framework for Diagnosing Retrieval-Augmented Generation
Aug 15, 2024



Despite Retrieval-Augmented Generation (RAG) has shown promising capability in leveraging external knowledge, a comprehensive evaluation of RAG systems is still challenging due to the modular nature of RAG, evaluation of long-form responses and reliability of measurements. In this paper, we propose a fine-grained evaluation framework, RAGChecker, that incorporates a suite of diagnostic metrics for both the retrieval and generation modules. Meta evaluation verifies that RAGChecker has significantly better correlations with human judgments than other evaluation metrics. Using RAGChecker, we evaluate 8 RAG systems and conduct an in-depth analysis of their performance, revealing insightful patterns and trade-offs in the design choices of RAG architectures. The metrics of RAGChecker can guide researchers and practitioners in developing more effective RAG systems.
Attention Fusion Reverse Distillation for Multi-Lighting Image Anomaly Detection
Jun 07, 2024



This study targets Multi-Lighting Image Anomaly Detection (MLIAD), where multiple lighting conditions are utilized to enhance imaging quality and anomaly detection performance. While numerous image anomaly detection methods have been proposed, they lack the capacity to handle multiple inputs for a single sample, like multi-lighting images in MLIAD. Hence, this study proposes Attention Fusion Reverse Distillation (AFRD) to handle multiple inputs in MLIAD. For this purpose, AFRD utilizes a pre-trained teacher network to extract features from multiple inputs. Then these features are aggregated into fused features through an attention module. Subsequently, a corresponding student net-work is utilized to regress the attention fused features. The regression errors are denoted as anomaly scores during inference. Experiments on Eyecandies demonstrates that AFRD achieves superior MLIAD performance than other MLIAD alternatives, also highlighting the benefit of using multiple lighting conditions for anomaly detection.
RefChecker: Reference-based Fine-grained Hallucination Checker and Benchmark for Large Language Models
May 23, 2024
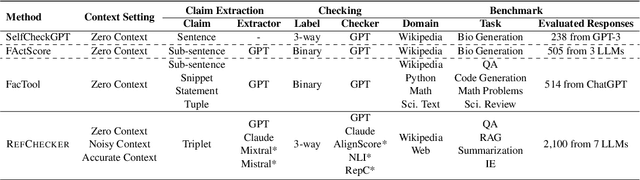

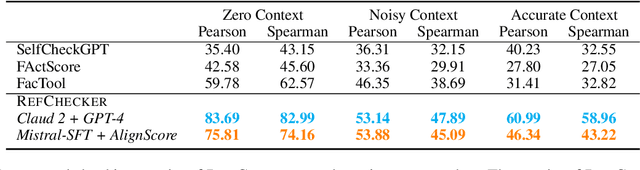
Large Language Models (LLMs) have shown impressive capabilities but also a concerning tendency to hallucinate. This paper presents RefChecker, a framework that introduces claim-triplets to represent claims in LLM responses, aiming to detect fine-grained hallucinations. In RefChecker, an extractor generates claim-triplets from a response, which are then evaluated by a checker against a reference. We delineate three task settings: Zero, Noisy and Accurate Context, to reflect various real-world use cases. We curated a benchmark spanning various NLP tasks and annotated 11k claim-triplets from 2.1k responses by seven LLMs. RefChecker supports both proprietary and open-source models as the extractor and checker. Experiments demonstrate that claim-triplets enable superior hallucination detection, compared to other granularities such as response, sentence and sub-sentence level claims. RefChecker outperforms prior methods by 6.8 to 26.1 points on our benchmark and the checking results of RefChecker are strongly aligned with human judgments. This work is open sourced at https://github.com/amazon-science/RefChecker
RepEval: Effective Text Evaluation with LLM Representation
Apr 30, 2024Automatic evaluation metrics for generated texts play an important role in the NLG field, especially with the rapid growth of LLMs. However, existing metrics are often limited to specific scenarios, making it challenging to meet the evaluation requirements of expanding LLM applications. Therefore, there is a demand for new, flexible, and effective metrics. In this study, we introduce RepEval, the first metric leveraging the projection of LLM representations for evaluation. RepEval requires minimal sample pairs for training, and through simple prompt modifications, it can easily transition to various tasks. Results on ten datasets from three tasks demonstrate the high effectiveness of our method, which exhibits stronger correlations with human judgments compared to previous metrics, even outperforming GPT-4. Our work underscores the richness of information regarding text quality embedded within LLM representations, offering insights for the development of new metrics.
SH2: Self-Highlighted Hesitation Helps You Decode More Truthfully
Jan 11, 2024



Large language models (LLMs) demonstrate great performance in text generation. However, LLMs are still suffering from hallucinations. In this work, we propose an inference-time method, Self-Highlighted Hesitation (SH2), to help LLMs decode more truthfully. SH2 is based on a simple fact rooted in information theory that for an LLM, the tokens predicted with lower probabilities are prone to be more informative than others. Our analysis shows that the tokens assigned with lower probabilities by an LLM are more likely to be closely related to factual information, such as nouns, proper nouns, and adjectives. Therefore, we propose to ''highlight'' the factual information by selecting the tokens with the lowest probabilities and concatenating them to the original context, thus forcing the model to repeatedly read and hesitate on these tokens before generation. During decoding, we also adopt contrastive decoding to emphasize the difference in the output probabilities brought by the hesitation. Experimental results demonstrate that our SH2, requiring no additional data or models, can effectively help LLMs elicit factual knowledge and distinguish hallucinated contexts. Significant and consistent improvements are achieved by SH2 for LLaMA-7b and LLaMA2-7b on multiple hallucination tasks.
GeoGalactica: A Scientific Large Language Model in Geoscience
Dec 31, 2023

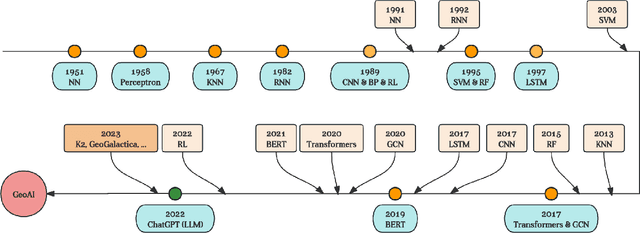
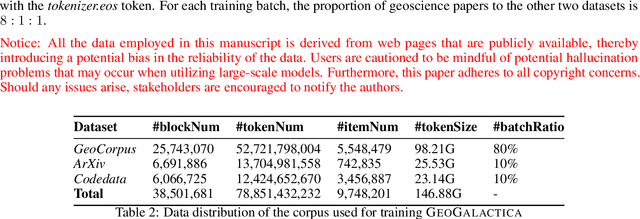
Large language models (LLMs) have achieved huge success for their general knowledge and ability to solve a wide spectrum of tasks in natural language processing (NLP). Due to their impressive abilities, LLMs have shed light on potential inter-discipline applications to foster scientific discoveries of a specific domain by using artificial intelligence (AI for science, AI4S). In the meantime, utilizing NLP techniques in geoscience research and practice is wide and convoluted, contributing from knowledge extraction and document classification to question answering and knowledge discovery. In this work, we take the initial step to leverage LLM for science, through a rather straightforward approach. We try to specialize an LLM into geoscience, by further pre-training the model with a vast amount of texts in geoscience, as well as supervised fine-tuning (SFT) the resulting model with our custom collected instruction tuning dataset. These efforts result in a model GeoGalactica consisting of 30 billion parameters. To our best knowledge, it is the largest language model for the geoscience domain. More specifically, GeoGalactica is from further pre-training of Galactica. We train GeoGalactica over a geoscience-related text corpus containing 65 billion tokens curated from extensive data sources in the big science project Deep-time Digital Earth (DDE), preserving as the largest geoscience-specific text corpus. Then we fine-tune the model with 1 million pairs of instruction-tuning data consisting of questions that demand professional geoscience knowledge to answer. In this technical report, we will illustrate in detail all aspects of GeoGalactica, including data collection, data cleaning, base model selection, pre-training, SFT, and evaluation. We open-source our data curation tools and the checkpoints of GeoGalactica during the first 3/4 of pre-training.
Enhancing Uncertainty-Based Hallucination Detection with Stronger Focus
Nov 22, 2023Large Language Models (LLMs) have gained significant popularity for their impressive performance across diverse fields. However, LLMs are prone to hallucinate untruthful or nonsensical outputs that fail to meet user expectations in many real-world applications. Existing works for detecting hallucinations in LLMs either rely on external knowledge for reference retrieval or require sampling multiple responses from the LLM for consistency verification, making these methods costly and inefficient. In this paper, we propose a novel reference-free, uncertainty-based method for detecting hallucinations in LLMs. Our approach imitates human focus in factuality checking from three aspects: 1) focus on the most informative and important keywords in the given text; 2) focus on the unreliable tokens in historical context which may lead to a cascade of hallucinations; and 3) focus on the token properties such as token type and token frequency. Experimental results on relevant datasets demonstrate the effectiveness of our proposed method, which achieves state-of-the-art performance across all the evaluation metrics and eliminates the need for additional information.
Survey on Factuality in Large Language Models: Knowledge, Retrieval and Domain-Specificity
Oct 18, 2023



This survey addresses the crucial issue of factuality in Large Language Models (LLMs). As LLMs find applications across diverse domains, the reliability and accuracy of their outputs become vital. We define the Factuality Issue as the probability of LLMs to produce content inconsistent with established facts. We first delve into the implications of these inaccuracies, highlighting the potential consequences and challenges posed by factual errors in LLM outputs. Subsequently, we analyze the mechanisms through which LLMs store and process facts, seeking the primary causes of factual errors. Our discussion then transitions to methodologies for evaluating LLM factuality, emphasizing key metrics, benchmarks, and studies. We further explore strategies for enhancing LLM factuality, including approaches tailored for specific domains. We focus two primary LLM configurations standalone LLMs and Retrieval-Augmented LLMs that utilizes external data, we detail their unique challenges and potential enhancements. Our survey offers a structured guide for researchers aiming to fortify the factual reliability of LLMs.