 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNewtonBench: Benchmarking Generalizable Scientific Law Discovery in LLM Agents
Oct 08, 2025Large language models are emerging as powerful tools for scientific law discovery, a foundational challenge in AI-driven science. However, existing benchmarks for this task suffer from a fundamental methodological trilemma, forcing a trade-off between scientific relevance, scalability, and resistance to memorization. Furthermore, they oversimplify discovery as static function fitting, failing to capture the authentic scientific process of uncovering embedded laws through the interactive exploration of complex model systems. To address these critical gaps, we introduce NewtonBench, a benchmark comprising 324 scientific law discovery tasks across 12 physics domains. Our design mitigates the evaluation trilemma by using metaphysical shifts - systematic alterations of canonical laws - to generate a vast suite of problems that are scalable, scientifically relevant, and memorization-resistant. Moreover, we elevate the evaluation from static function fitting to interactive model discovery, requiring agents to experimentally probe simulated complex systems to uncover hidden principles. Our extensive experiment reveals a clear but fragile capability for discovery in frontier LLMs: this ability degrades precipitously with increasing system complexity and exhibits extreme sensitivity to observational noise. Notably, we uncover a paradoxical effect of tool assistance: providing a code interpreter can hinder more capable models by inducing a premature shift from exploration to exploitation, causing them to satisfice on suboptimal solutions. These results demonstrate that robust, generalizable discovery in complex, interactive environments remains the core challenge. By providing a scalable, robust, and scientifically authentic testbed, NewtonBench offers a crucial tool for measuring true progress and guiding the development of next-generation AI agents capable of genuine scientific discovery.
Top Ten Challenges Towards Agentic Neural Graph Databases
Jan 24, 2025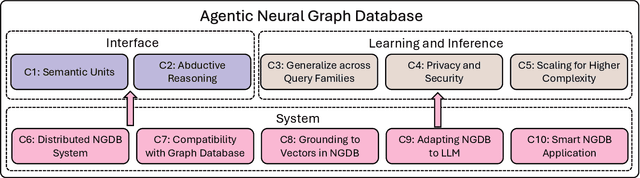
Graph databases (GDBs) like Neo4j and TigerGraph excel at handling interconnected data but lack advanced inference capabilities. Neural Graph Databases (NGDBs) address this by integrating Graph Neural Networks (GNNs) for predictive analysis and reasoning over incomplete or noisy data. However, NGDBs rely on predefined queries and lack autonomy and adaptability. This paper introduces Agentic Neural Graph Databases (Agentic NGDBs), which extend NGDBs with three core functionalities: autonomous query construction, neural query execution, and continuous learning. We identify ten key challenges in realizing Agentic NGDBs: semantic unit representation, abductive reasoning, scalable query execution, and integration with foundation models like large language models (LLMs). By addressing these challenges, Agentic NGDBs can enable intelligent, self-improving systems for modern data-driven applications, paving the way for adaptable and autonomous data management solutions.
ActPlan-1K: Benchmarking the Procedural Planning Ability of Visual Language Models in Household Activities
Oct 04, 2024



Large language models~(LLMs) have been adopted to process textual task description and accomplish procedural planning in embodied AI tasks because of their powerful reasoning ability. However, there is still lack of study on how vision language models~(VLMs) behave when multi-modal task inputs are considered. Counterfactual planning that evaluates the model's reasoning ability over alternative task situations are also under exploited. In order to evaluate the planning ability of both multi-modal and counterfactual aspects, we propose ActPlan-1K. ActPlan-1K is a multi-modal planning benchmark constructed based on ChatGPT and household activity simulator iGibson2. The benchmark consists of 153 activities and 1,187 instances. Each instance describing one activity has a natural language task description and multiple environment images from the simulator. The gold plan of each instance is action sequences over the objects in provided scenes. Both the correctness and commonsense satisfaction are evaluated on typical VLMs. It turns out that current VLMs are still struggling at generating human-level procedural plans for both normal activities and counterfactual activities. We further provide automatic evaluation metrics by finetuning over BLEURT model to facilitate future research on our benchmark.
Privacy Checklist: Privacy Violation Detection Grounding on Contextual Integrity Theory
Aug 19, 2024



Privacy research has attracted wide attention as individuals worry that their private data can be easily leaked during interactions with smart devices, social platforms, and AI applications. Computer science researchers, on the other hand, commonly study privacy issues through privacy attacks and defenses on segmented fields. Privacy research is conducted on various sub-fields, including Computer Vision (CV), Natural Language Processing (NLP), and Computer Networks. Within each field, privacy has its own formulation. Though pioneering works on attacks and defenses reveal sensitive privacy issues, they are narrowly trapped and cannot fully cover people's actual privacy concerns. Consequently, the research on general and human-centric privacy research remains rather unexplored. In this paper, we formulate the privacy issue as a reasoning problem rather than simple pattern matching. We ground on the Contextual Integrity (CI) theory which posits that people's perceptions of privacy are highly correlated with the corresponding social context. Based on such an assumption, we develop the first comprehensive checklist that covers social identities, private attributes, and existing privacy regulations. Unlike prior works on CI that either cover limited expert annotated norms or model incomplete social context, our proposed privacy checklist uses the whole Health Insurance Portability and Accountability Act of 1996 (HIPAA) as an example, to show that we can resort to large language models (LLMs) to completely cover the HIPAA's regulations. Additionally, our checklist also gathers expert annotations across multiple ontologies to determine private information including but not limited to personally identifiable information (PII). We use our preliminary results on the HIPAA to shed light on future context-centric privacy research to cover more privacy regulations, social norms and standards.
RAGChecker: A Fine-grained Framework for Diagnosing Retrieval-Augmented Generation
Aug 15, 2024



Despite Retrieval-Augmented Generation (RAG) has shown promising capability in leveraging external knowledge, a comprehensive evaluation of RAG systems is still challenging due to the modular nature of RAG, evaluation of long-form responses and reliability of measurements. In this paper, we propose a fine-grained evaluation framework, RAGChecker, that incorporates a suite of diagnostic metrics for both the retrieval and generation modules. Meta evaluation verifies that RAGChecker has significantly better correlations with human judgments than other evaluation metrics. Using RAGChecker, we evaluate 8 RAG systems and conduct an in-depth analysis of their performance, revealing insightful patterns and trade-offs in the design choices of RAG architectures. The metrics of RAGChecker can guide researchers and practitioners in developing more effective RAG systems.
LLMs Assist NLP Researchers: Critique Paper (Meta-)Reviewing
Jun 25, 2024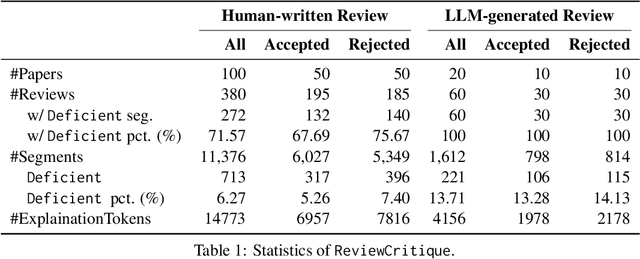
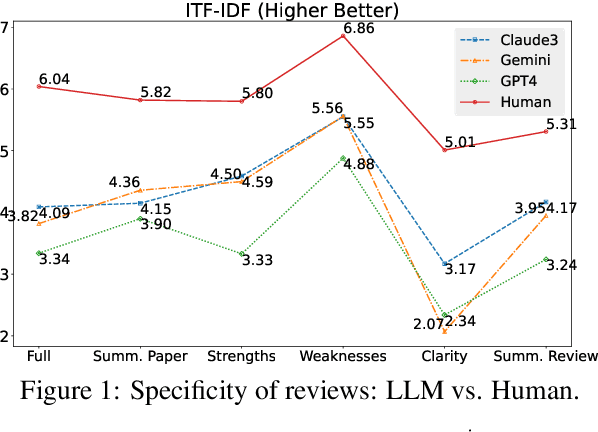

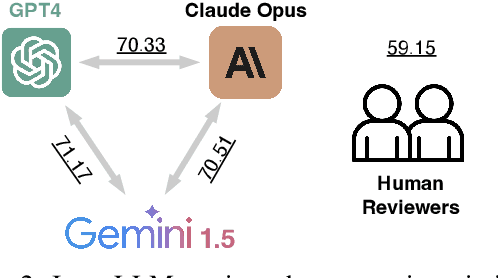
This work is motivated by two key trends. On one hand, large language models (LLMs) have shown remarkable versatility in various generative tasks such as writing, drawing, and question answering, significantly reducing the time required for many routine tasks. On the other hand, researchers, whose work is not only time-consuming but also highly expertise-demanding, face increasing challenges as they have to spend more time reading, writing, and reviewing papers. This raises the question: how can LLMs potentially assist researchers in alleviating their heavy workload? This study focuses on the topic of LLMs assist NLP Researchers, particularly examining the effectiveness of LLM in assisting paper (meta-)reviewing and its recognizability. To address this, we constructed the ReviewCritique dataset, which includes two types of information: (i) NLP papers (initial submissions rather than camera-ready) with both human-written and LLM-generated reviews, and (ii) each review comes with "deficiency" labels and corresponding explanations for individual segments, annotated by experts. Using ReviewCritique, this study explores two threads of research questions: (i) "LLMs as Reviewers", how do reviews generated by LLMs compare with those written by humans in terms of quality and distinguishability? (ii) "LLMs as Metareviewers", how effectively can LLMs identify potential issues, such as Deficient or unprofessional review segments, within individual paper reviews? To our knowledge, this is the first work to provide such a comprehensive analysis.
CANDLE: Iterative Conceptualization and Instantiation Distillation from Large Language Models for Commonsense Reasoning
Jan 14, 2024The sequential process of conceptualization and instantiation is essential to generalizable commonsense reasoning as it allows the application of existing knowledge to unfamiliar scenarios. However, existing works tend to undervalue the step of instantiation and heavily rely on pre-built concept taxonomies and human annotations to collect both types of knowledge, resulting in a lack of instantiated knowledge to complete reasoning, high cost, and limited scalability. To tackle these challenges, we introduce CANDLE, a distillation framework that iteratively performs contextualized conceptualization and instantiation over commonsense knowledge bases by instructing large language models to generate both types of knowledge with critic filtering. By applying CANDLE to ATOMIC, we construct a comprehensive knowledge base comprising six million conceptualizations and instantiated commonsense knowledge triples. Both types of knowledge are firmly rooted in the original ATOMIC dataset, and intrinsic evaluations demonstrate their exceptional quality and diversity. Empirical results indicate that distilling CANDLE on student models provides benefits across four downstream tasks. Our code, data, and models are publicly available at https://github.com/HKUST-KnowComp/CANDLE.
Self-Consistent Narrative Prompts on Abductive Natural Language Inference
Sep 15, 2023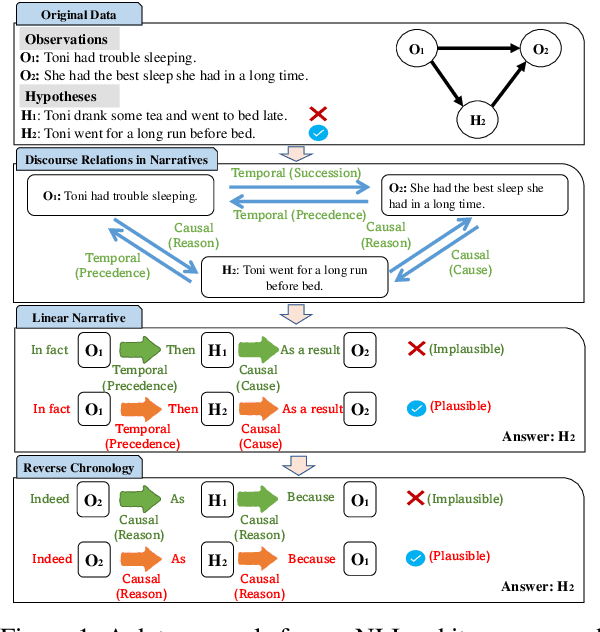

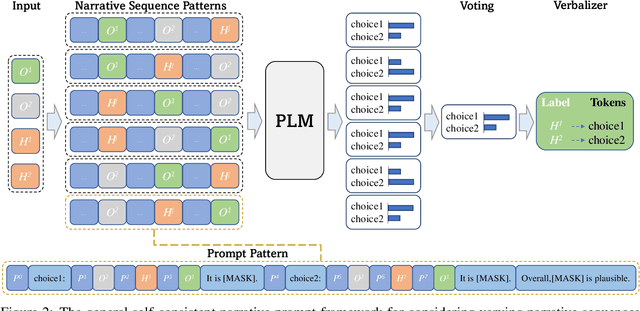

Abduction has long been seen as crucial for narrative comprehension and reasoning about everyday situations. The abductive natural language inference ($\alpha$NLI) task has been proposed, and this narrative text-based task aims to infer the most plausible hypothesis from the candidates given two observations. However, the inter-sentential coherence and the model consistency have not been well exploited in the previous works on this task. In this work, we propose a prompt tuning model $\alpha$-PACE, which takes self-consistency and inter-sentential coherence into consideration. Besides, we propose a general self-consistent framework that considers various narrative sequences (e.g., linear narrative and reverse chronology) for guiding the pre-trained language model in understanding the narrative context of input. We conduct extensive experiments and thorough ablation studies to illustrate the necessity and effectiveness of $\alpha$-PACE. The performance of our method shows significant improvement against extensive competitive baselines.
ChatGPT Evaluation on Sentence Level Relations: A Focus on Temporal, Causal, and Discourse Relations
May 11, 2023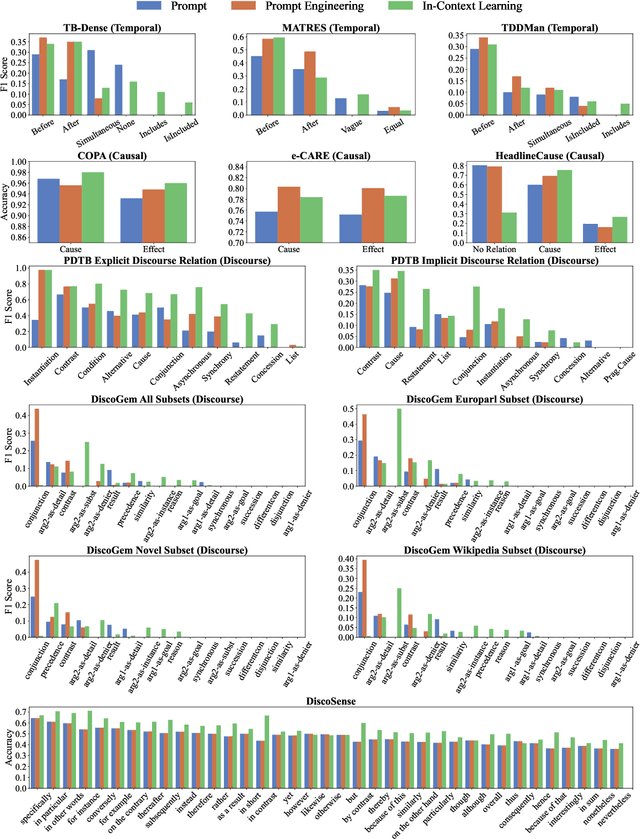
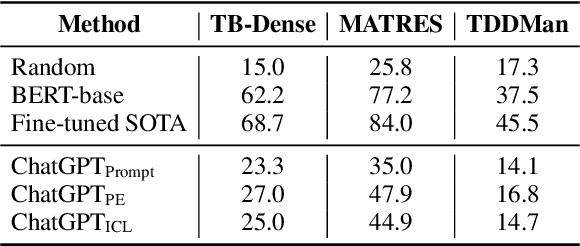
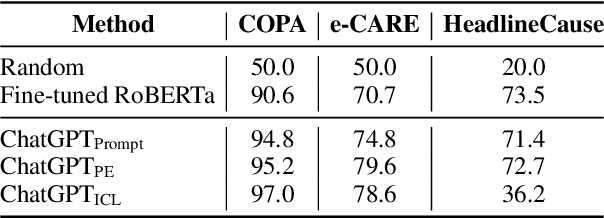
This paper aims to quantitatively evaluate the performance of ChatGPT, an interactive large language model, on inter-sentential relations such as temporal relations, causal relations, and discourse relations. Given ChatGPT's promising performance across various tasks, we conduct extensive evaluations on the whole test sets of 13 datasets, including temporal and causal relations, PDTB2.0-based and dialogue-based discourse relations, and downstream applications on discourse understanding. To achieve reliable results, we adopt three tailored prompt templates for each task, including the zero-shot prompt template, zero-shot prompt engineering (PE) template, and in-context learning (ICL) prompt template, to establish the initial baseline scores for all popular sentence-pair relation classification tasks for the first time. We find that ChatGPT exhibits strong performance in detecting and reasoning about causal relations, while it may not be proficient in identifying the temporal order between two events. It can recognize most discourse relations with existing explicit discourse connectives, but the implicit discourse relation still remains a challenging task. Meanwhile, ChatGPT performs poorly in the dialogue discourse parsing task that requires structural understanding in a dialogue before being aware of the discourse relation.
DiscoPrompt: Path Prediction Prompt Tuning for Implicit Discourse Relation Recognition
May 06, 2023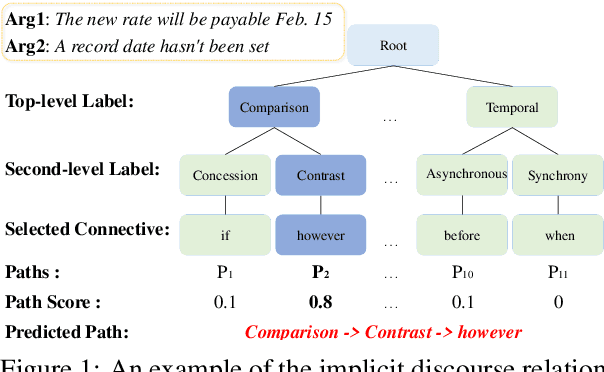
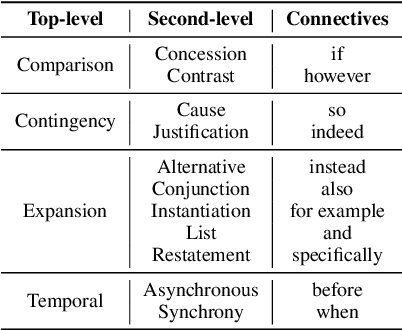
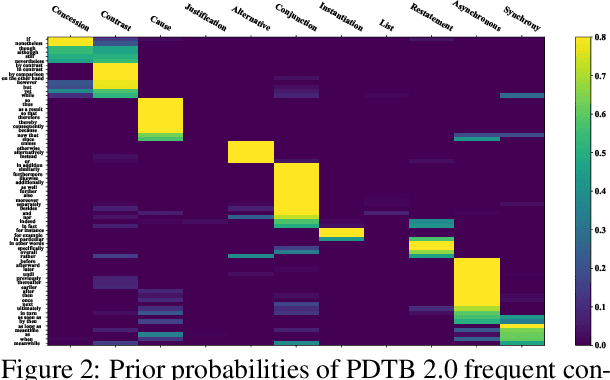
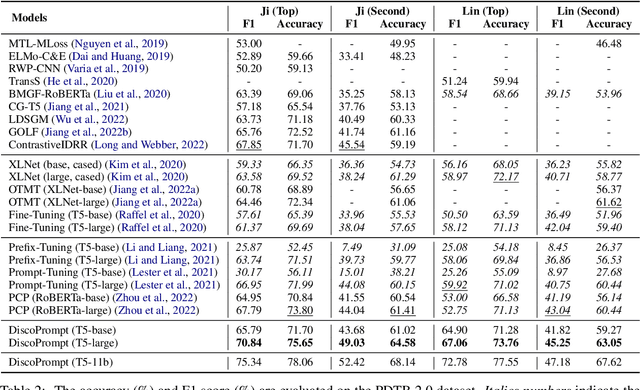
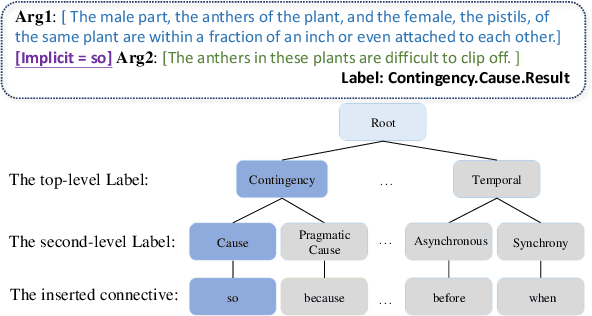
Implicit Discourse Relation Recognition (IDRR) is a sophisticated and challenging task to recognize the discourse relations between the arguments with the absence of discourse connectives. The sense labels for each discourse relation follow a hierarchical classification scheme in the annotation process (Prasad et al., 2008), forming a hierarchy structure. Most existing works do not well incorporate the hierarchy structure but focus on the syntax features and the prior knowledge of connectives in the manner of pure text classification. We argue that it is more effective to predict the paths inside the hierarchical tree (e.g., "Comparison -> Contrast -> however") rather than flat labels (e.g., Contrast) or connectives (e.g., however). We propose a prompt-based path prediction method to utilize the interactive information and intrinsic senses among the hierarchy in IDRR. This is the first work that injects such structure information into pre-trained language models via prompt tuning, and the performance of our solution shows significant and consistent improvement against competitive baselines.