 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHDLdebugger: Streamlining HDL debugging with Large Language Models
Mar 18, 2024In the domain of chip design, Hardware Description Languages (HDLs) play a pivotal role. However, due to the complex syntax of HDLs and the limited availability of online resources, debugging HDL codes remains a difficult and time-intensive task, even for seasoned engineers. Consequently, there is a pressing need to develop automated HDL code debugging models, which can alleviate the burden on hardware engineers. Despite the strong capabilities of Large Language Models (LLMs) in generating, completing, and debugging software code, their utilization in the specialized field of HDL debugging has been limited and, to date, has not yielded satisfactory results. In this paper, we propose an LLM-assisted HDL debugging framework, namely HDLdebugger, which consists of HDL debugging data generation via a reverse engineering approach, a search engine for retrieval-augmented generation, and a retrieval-augmented LLM fine-tuning approach. Through the integration of these components, HDLdebugger can automate and streamline HDL debugging for chip design. Our comprehensive experiments, conducted on an HDL code dataset sourced from Huawei, reveal that HDLdebugger outperforms 13 cutting-edge LLM baselines, displaying exceptional effectiveness in HDL code debugging.
IB-Net: Initial Branch Network for Variable Decision in Boolean Satisfiability
Mar 06, 2024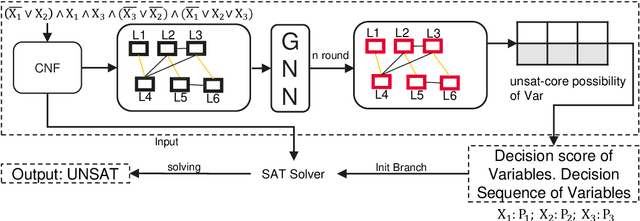
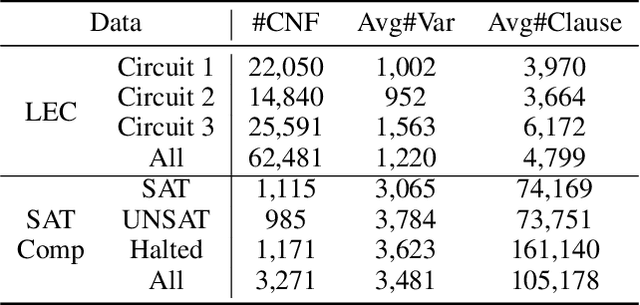
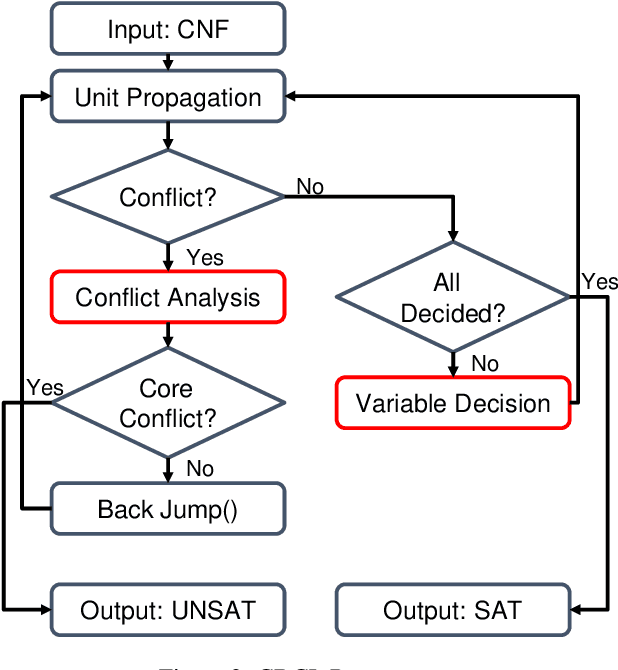
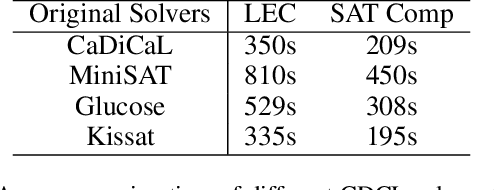
Boolean Satisfiability problems are vital components in Electronic Design Automation, particularly within the Logic Equivalence Checking process. Currently, SAT solvers are employed for these problems and neural network is tried as assistance to solvers. However, as SAT problems in the LEC context are distinctive due to their predominantly unsatisfiability nature and a substantial proportion of UNSAT-core variables, existing neural network assistance has proven unsuccessful in this specialized domain. To tackle this challenge, we propose IB-Net, an innovative framework utilizing graph neural networks and novel graph encoding techniques to model unsatisfiable problems and interact with state-of-the-art solvers. Extensive evaluations across solvers and datasets demonstrate IB-Net's acceleration, achieving an average runtime speedup of 5.0% on industrial data and 8.3% on SAT competition data empirically. This breakthrough advances efficient solving in LEC workflows.
StoryAnalogy: Deriving Story-level Analogies from Large Language Models to Unlock Analogical Understanding
Oct 23, 2023Analogy-making between narratives is crucial for human reasoning. In this paper, we evaluate the ability to identify and generate analogies by constructing a first-of-its-kind large-scale story-level analogy corpus, \textsc{StoryAnalogy}, which contains 24K story pairs from diverse domains with human annotations on two similarities from the extended Structure-Mapping Theory. We design a set of tests on \textsc{StoryAnalogy}, presenting the first evaluation of story-level analogy identification and generation. Interestingly, we find that the analogy identification tasks are incredibly difficult not only for sentence embedding models but also for the recent large language models (LLMs) such as ChatGPT and LLaMa. ChatGPT, for example, only achieved around 30% accuracy in multiple-choice questions (compared to over 85% accuracy for humans). Furthermore, we observe that the data in \textsc{StoryAnalogy} can improve the quality of analogy generation in LLMs, where a fine-tuned FlanT5-xxl model achieves comparable performance to zero-shot ChatGPT.
Self-Consistent Narrative Prompts on Abductive Natural Language Inference
Sep 15, 2023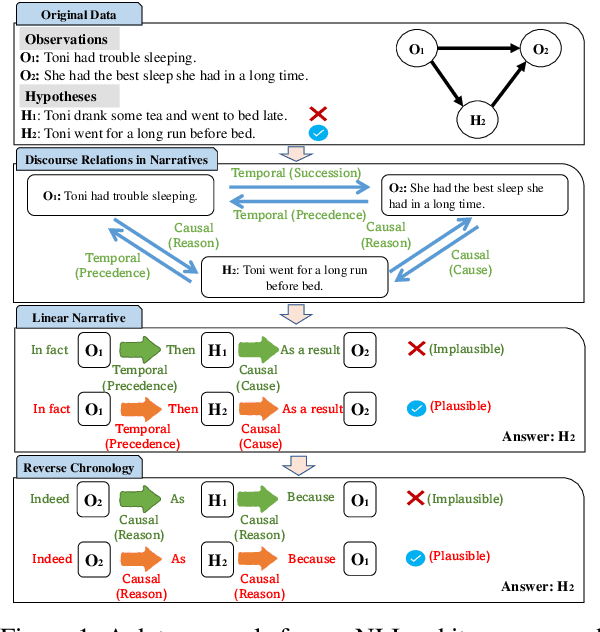

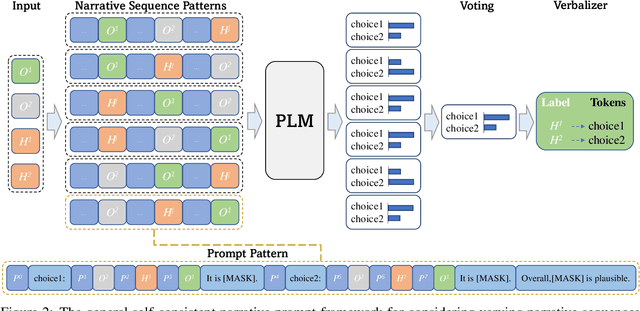

Abduction has long been seen as crucial for narrative comprehension and reasoning about everyday situations. The abductive natural language inference ($\alpha$NLI) task has been proposed, and this narrative text-based task aims to infer the most plausible hypothesis from the candidates given two observations. However, the inter-sentential coherence and the model consistency have not been well exploited in the previous works on this task. In this work, we propose a prompt tuning model $\alpha$-PACE, which takes self-consistency and inter-sentential coherence into consideration. Besides, we propose a general self-consistent framework that considers various narrative sequences (e.g., linear narrative and reverse chronology) for guiding the pre-trained language model in understanding the narrative context of input. We conduct extensive experiments and thorough ablation studies to illustrate the necessity and effectiveness of $\alpha$-PACE. The performance of our method shows significant improvement against extensive competitive baselines.