 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoIB: Geometry-Aware Information Bottleneck via Statistical-Manifold Compression
Feb 03, 2026Information Bottleneck (IB) is widely used, but in deep learning, it is usually implemented through tractable surrogates, such as variational bounds or neural mutual information (MI) estimators, rather than directly controlling the MI I(X;Z) itself. The looseness and estimator-dependent bias can make IB "compression" only indirectly controlled and optimization fragile. We revisit the IB problem through the lens of information geometry and propose a \textbf{Geo}metric \textbf{I}nformation \textbf{B}ottleneck (\textbf{GeoIB}) that dispenses with mutual information (MI) estimation. We show that I(X;Z) and I(Z;Y) admit exact projection forms as minimal Kullback-Leibler (KL) distances from the joint distributions to their respective independence manifolds. Guided by this view, GeoIB controls information compression with two complementary terms: (i) a distribution-level Fisher-Rao (FR) discrepancy, which matches KL to second order and is reparameterization-invariant; and (ii) a geometry-level Jacobian-Frobenius (JF) term that provides a local capacity-type upper bound on I(Z;X) by penalizing pullback volume expansion of the encoder. We further derive a natural-gradient optimizer consistent with the FR metric and prove that the standard additive natural-gradient step is first-order equivalent to the geodesic update. We conducted extensive experiments and observed that the GeoIB achieves a better trade-off between prediction accuracy and compression ratio in the information plane than the mainstream IB baselines on popular datasets. GeoIB improves invariance and optimization stability by unifying distributional and geometric regularization under a single bottleneck multiplier. The source code of GeoIB is released at "https://anonymous.4open.science/r/G-IB-0569".
EVE: Efficient Verification of Data Erasure through Customized Perturbation in Approximate Unlearning
Feb 03, 2026Verifying whether the machine unlearning process has been properly executed is critical but remains underexplored. Some existing approaches propose unlearning verification methods based on backdooring techniques. However, these methods typically require participation in the model's initial training phase to backdoor the model for later verification, which is inefficient and impractical. In this paper, we propose an efficient verification of erasure method (EVE) for verifying machine unlearning without requiring involvement in the model's initial training process. The core idea is to perturb the unlearning data to ensure the model prediction of the specified samples will change before and after unlearning with perturbed data. The unlearning users can leverage the observation of the changes as a verification signal. Specifically, the perturbations are designed with two key objectives: ensuring the unlearning effect and altering the unlearned model's prediction of target samples. We formalize the perturbation generation as an adversarial optimization problem, solving it by aligning the unlearning gradient with the gradient of boundary change for target samples. We conducted extensive experiments, and the results show that EVE can verify machine unlearning without involving the model's initial training process, unlike backdoor-based methods. Moreover, EVE significantly outperforms state-of-the-art unlearning verification methods, offering significant speedup in efficiency while enhancing verification accuracy. The source code of EVE is released at \uline{https://anonymous.4open.science/r/EVE-C143}, providing a novel tool for verification of machine unlearning.
HeaPA: Difficulty-Aware Heap Sampling and On-Policy Query Augmentation for LLM Reinforcement Learning
Jan 30, 2026RLVR is now a standard way to train LLMs on reasoning tasks with verifiable outcomes, but when rollout generation dominates the cost, efficiency depends heavily on which prompts you sample and when. In practice, prompt pools are often static or only loosely tied to the model's learning progress, so uniform sampling can't keep up with the shifting capability frontier and ends up wasting rollouts on prompts that are already solved or still out of reach. Existing approaches improve efficiency through filtering, curricula, adaptive rollout allocation, or teacher guidance, but they typically assume a fixed pool-which makes it hard to support stable on-policy pool growth-or they add extra teacher cost and latency. We introduce HeaPA (Heap Sampling and On-Policy Query Augmentation), which maintains a bounded, evolving pool, tracks the frontier using heap-based boundary sampling, expands the pool via on-policy augmentation with lightweight asynchronous validation, and stabilizes correlated queries through topology-aware re-estimation of pool statistics and controlled reinsertion. Across two training corpora, two training recipes, and seven benchmarks, HeaPA consistently improves accuracy and reaches target performance with fewer computations while keeping wall-clock time comparable. Our analyses suggest these gains come from frontier-focused sampling and on-policy pool growth, with the benefits becoming larger as model scale increases. Our code is available at https://github.com/horizon-rl/HeaPA.
BlindU: Blind Machine Unlearning without Revealing Erasing Data
Jan 12, 2026Machine unlearning enables data holders to remove the contribution of their specified samples from trained models to protect their privacy. However, it is paradoxical that most unlearning methods require the unlearning requesters to firstly upload their data to the server as a prerequisite for unlearning. These methods are infeasible in many privacy-preserving scenarios where servers are prohibited from accessing users' data, such as federated learning (FL). In this paper, we explore how to implement unlearning under the condition of not uncovering the erasing data to the server. We propose \textbf{Blind Unlearning (BlindU)}, which carries out unlearning using compressed representations instead of original inputs. BlindU only involves the server and the unlearning user: the user locally generates privacy-preserving representations, and the server performs unlearning solely on these representations and their labels. For the FL model training, we employ the information bottleneck (IB) mechanism. The encoder of the IB-based FL model learns representations that distort maximum task-irrelevant information from inputs, allowing FL users to generate compressed representations locally. For effective unlearning using compressed representation, BlindU integrates two dedicated unlearning modules tailored explicitly for IB-based models and uses a multiple gradient descent algorithm to balance forgetting and utility retaining. While IB compression already provides protection for task-irrelevant information of inputs, to further enhance the privacy protection, we introduce a noise-free differential privacy (DP) masking method to deal with the raw erasing data before compressing. Theoretical analysis and extensive experimental results illustrate the superiority of BlindU in privacy protection and unlearning effectiveness compared with the best existing privacy-preserving unlearning benchmarks.
Beyond Accuracy: A Geometric Stability Analysis of Large Language Models in Chess Evaluation
Dec 17, 2025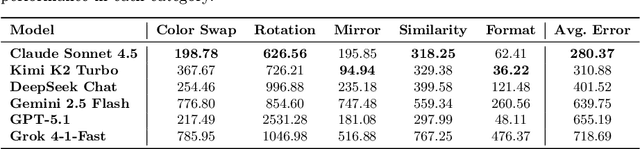
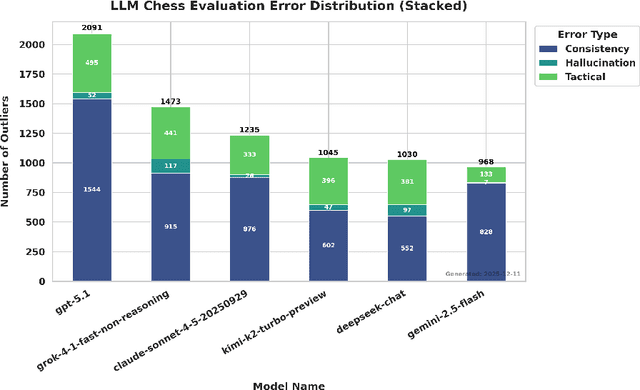


The evaluation of Large Language Models (LLMs) in complex reasoning domains typically relies on performance alignment with ground-truth oracles. In the domain of chess, this standard manifests as accuracy benchmarks against strong engines like Stockfish. However, high scalar accuracy does not necessarily imply robust conceptual understanding. This paper argues that standard accuracy metrics fail to distinguish between genuine geometric reasoning and the superficial memorization of canonical board states. To address this gap, we propose a Geometric Stability Framework, a novel evaluation methodology that rigorously tests model consistency under invariant transformations-including board rotation, mirror symmetry, color inversion, and format conversion. We applied this framework to a comparative analysis of six state-of-the-art LLMs including GPT-5.1, Claude Sonnet 4.5, and Kimi K2 Turbo, utilizing a dataset of approximately 3,000 positions. Our results reveal a significant Accuracy-Stability Paradox. While models such as GPT-5.1 achieve near-optimal accuracy on standard positions, they exhibit catastrophic degradation under geometric perturbation, specifically in rotation tasks where error rates surge by over 600%. This disparity suggests a reliance on pattern matching over abstract spatial logic. Conversely, Claude Sonnet 4.5 and Kimi K2 Turbo demonstrate superior dual robustness, maintaining high consistency across all transformation axes. Furthermore, we analyze the trade-off between helpfulness and safety, identifying Gemini 2.5 Flash as the leader in illegal state rejection (96.0%). We conclude that geometric stability provides an orthogonal and essential metric for AI evaluation, offering a necessary proxy for disentangling reasoning capabilities from data contamination and overfitting in large-scale models.
NewtonBench: Benchmarking Generalizable Scientific Law Discovery in LLM Agents
Oct 08, 2025Large language models are emerging as powerful tools for scientific law discovery, a foundational challenge in AI-driven science. However, existing benchmarks for this task suffer from a fundamental methodological trilemma, forcing a trade-off between scientific relevance, scalability, and resistance to memorization. Furthermore, they oversimplify discovery as static function fitting, failing to capture the authentic scientific process of uncovering embedded laws through the interactive exploration of complex model systems. To address these critical gaps, we introduce NewtonBench, a benchmark comprising 324 scientific law discovery tasks across 12 physics domains. Our design mitigates the evaluation trilemma by using metaphysical shifts - systematic alterations of canonical laws - to generate a vast suite of problems that are scalable, scientifically relevant, and memorization-resistant. Moreover, we elevate the evaluation from static function fitting to interactive model discovery, requiring agents to experimentally probe simulated complex systems to uncover hidden principles. Our extensive experiment reveals a clear but fragile capability for discovery in frontier LLMs: this ability degrades precipitously with increasing system complexity and exhibits extreme sensitivity to observational noise. Notably, we uncover a paradoxical effect of tool assistance: providing a code interpreter can hinder more capable models by inducing a premature shift from exploration to exploitation, causing them to satisfice on suboptimal solutions. These results demonstrate that robust, generalizable discovery in complex, interactive environments remains the core challenge. By providing a scalable, robust, and scientifically authentic testbed, NewtonBench offers a crucial tool for measuring true progress and guiding the development of next-generation AI agents capable of genuine scientific discovery.
The Cognitive Bandwidth Bottleneck: Shifting Long-Horizon Agent from Planning with Actions to Planning with Schemas
Oct 08, 2025Enabling LLMs to effectively operate long-horizon task which requires long-term planning and multiple interactions is essential for open-world autonomy. Conventional methods adopt planning with actions where a executable action list would be provided as reference. However, this action representation choice would be impractical when the environment action space is combinatorial exploded (e.g., open-ended real world). This naturally leads to a question: As environmental action space scales, what is the optimal action representation for long-horizon agents? In this paper, we systematically study the effectiveness of two different action representations. The first one is conventional planning with actions (PwA) which is predominantly adopted for its effectiveness on existing benchmarks. The other one is planning with schemas (PwS) which instantiate an action schema into action lists (e.g., "move [OBJ] to [OBJ]" -> "move apple to desk") to ensure concise action space and reliable scalability. This alternative is motivated by its alignment with human cognition and its compliance with environment-imposed action format restriction. We propose cognitive bandwidth perspective as a conceptual framework to qualitatively understand the differences between these two action representations and empirically observe a representation-choice inflection point between ALFWorld (~35 actions) and SciWorld (~500 actions), which serve as evidence of the need for scalable representations. We further conduct controlled experiments to study how the location of this inflection point interacts with different model capacities: stronger planning proficiency shifts the inflection rightward, whereas better schema instantiation shifts it leftward. Finally, noting the suboptimal performance of PwS agents, we provide an actionable guide for building more capable PwS agents for better scalable autonomy.
Structuring the Unstructured: A Systematic Review of Text-to-Structure Generation for Agentic AI with a Universal Evaluation Framework
Aug 17, 2025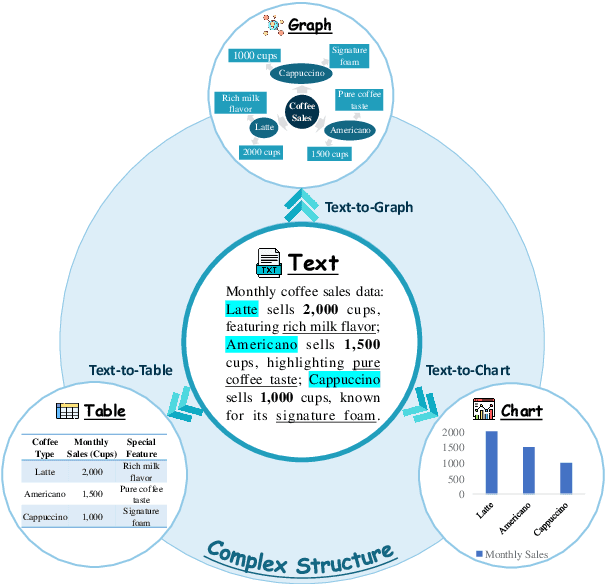
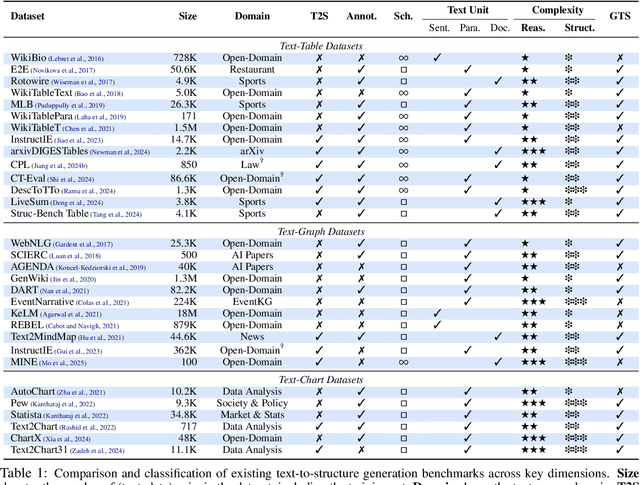

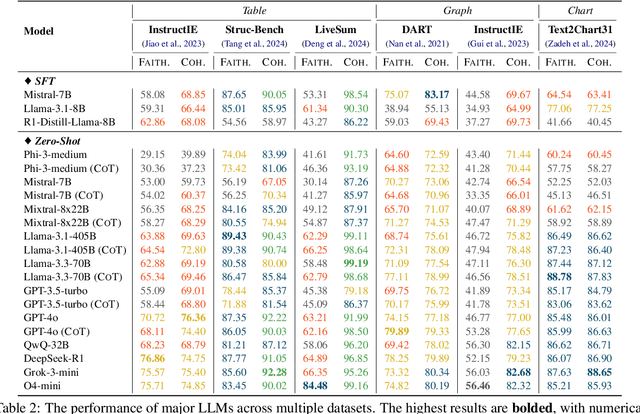
The evolution of AI systems toward agentic operation and context-aware retrieval necessitates transforming unstructured text into structured formats like tables, knowledge graphs, and charts. While such conversions enable critical applications from summarization to data mining, current research lacks a comprehensive synthesis of methodologies, datasets, and metrics. This systematic review examines text-to-structure techniques and the encountered challenges, evaluates current datasets and assessment criteria, and outlines potential directions for future research. We also introduce a universal evaluation framework for structured outputs, establishing text-to-structure as foundational infrastructure for next-generation AI systems.
Prospect Theory Fails for LLMs: Revealing Instability of Decision-Making under Epistemic Uncertainty
Aug 12, 2025
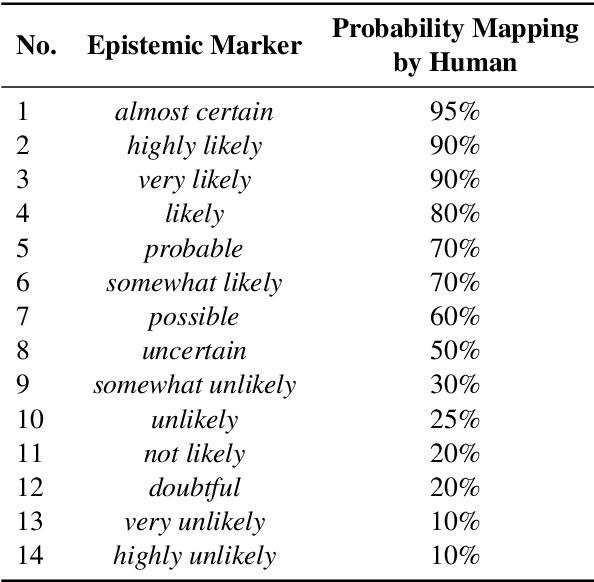

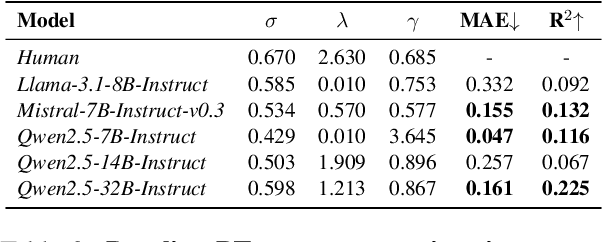
Prospect Theory (PT) models human decision-making under uncertainty, while epistemic markers (e.g., maybe) serve to express uncertainty in language. However, it remains largely unexplored whether Prospect Theory applies to contemporary Large Language Models and whether epistemic markers, which express human uncertainty, affect their decision-making behaviour. To address these research gaps, we design a three-stage experiment based on economic questionnaires. We propose a more general and precise evaluation framework to model LLMs' decision-making behaviour under PT, introducing uncertainty through the empirical probability values associated with commonly used epistemic markers in comparable contexts. We then incorporate epistemic markers into the evaluation framework based on their corresponding probability values to examine their influence on LLM decision-making behaviours. Our findings suggest that modelling LLMs' decision-making with PT is not consistently reliable, particularly when uncertainty is expressed in diverse linguistic forms. Our code is released in https://github.com/HKUST-KnowComp/MarPT.
SessionIntentBench: A Multi-task Inter-session Intention-shift Modeling Benchmark for E-commerce Customer Behavior Understanding
Jul 27, 2025Session history is a common way of recording user interacting behaviors throughout a browsing activity with multiple products. For example, if an user clicks a product webpage and then leaves, it might because there are certain features that don't satisfy the user, which serve as an important indicator of on-the-spot user preferences. However, all prior works fail to capture and model customer intention effectively because insufficient information exploitation and only apparent information like descriptions and titles are used. There is also a lack of data and corresponding benchmark for explicitly modeling intention in E-commerce product purchase sessions. To address these issues, we introduce the concept of an intention tree and propose a dataset curation pipeline. Together, we construct a sibling multimodal benchmark, SessionIntentBench, that evaluates L(V)LMs' capability on understanding inter-session intention shift with four subtasks. With 1,952,177 intention entries, 1,132,145 session intention trajectories, and 13,003,664 available tasks mined using 10,905 sessions, we provide a scalable way to exploit the existing session data for customer intention understanding. We conduct human annotations to collect ground-truth label for a subset of collected data to form an evaluation gold set. Extensive experiments on the annotated data further confirm that current L(V)LMs fail to capture and utilize the intention across the complex session setting. Further analysis show injecting intention enhances LLMs' performances.