 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering Beyond the Support: Adversarial Training on Unsupervised Jailbroken Activation Simulation
May 23, 2026Jailbreak prompts can trigger harmful completions on aligned LLMs, In accordance, safety steering has been proposed: test-time activation interventions that steer jailbreak activations to trigger refusal while preserving benign utility. However, existing steering methods are fundamentally supervised and tied to a static, limited training set, whereas real jailbreaks evolve and are often out-of-distributed from the training set, leading to failures on unseen attacks. In this paper, we tackle the failure on unseen jailbreaks problem, base on unsupervised latent direction discovery. We propose a bi-level adversarial training framework for zero-shot jailbreak defense. In the inner step, we simulate diverse jail-broken activations by extrapolating from refusal-state harmful-request activations via unsupervised latent direction discovery, which expands the coverage of real jailbreak activation subspaces. In the outer step, we train a potential-induced steering field to push these adversarial jailbroken states into refusal regions while keeping benign unchanged. Across three LLMs and six classical jailbreak families, our method achieves strong defense with attack success rates mostly below 5%, and rising subspace coverage throughout training helps explain the improved generalization.
EVE: Efficient Verification of Data Erasure through Customized Perturbation in Approximate Unlearning
Feb 03, 2026Verifying whether the machine unlearning process has been properly executed is critical but remains underexplored. Some existing approaches propose unlearning verification methods based on backdooring techniques. However, these methods typically require participation in the model's initial training phase to backdoor the model for later verification, which is inefficient and impractical. In this paper, we propose an efficient verification of erasure method (EVE) for verifying machine unlearning without requiring involvement in the model's initial training process. The core idea is to perturb the unlearning data to ensure the model prediction of the specified samples will change before and after unlearning with perturbed data. The unlearning users can leverage the observation of the changes as a verification signal. Specifically, the perturbations are designed with two key objectives: ensuring the unlearning effect and altering the unlearned model's prediction of target samples. We formalize the perturbation generation as an adversarial optimization problem, solving it by aligning the unlearning gradient with the gradient of boundary change for target samples. We conducted extensive experiments, and the results show that EVE can verify machine unlearning without involving the model's initial training process, unlike backdoor-based methods. Moreover, EVE significantly outperforms state-of-the-art unlearning verification methods, offering significant speedup in efficiency while enhancing verification accuracy. The source code of EVE is released at \uline{https://anonymous.4open.science/r/EVE-C143}, providing a novel tool for verification of machine unlearning.
GeoIB: Geometry-Aware Information Bottleneck via Statistical-Manifold Compression
Feb 03, 2026Information Bottleneck (IB) is widely used, but in deep learning, it is usually implemented through tractable surrogates, such as variational bounds or neural mutual information (MI) estimators, rather than directly controlling the MI I(X;Z) itself. The looseness and estimator-dependent bias can make IB "compression" only indirectly controlled and optimization fragile. We revisit the IB problem through the lens of information geometry and propose a \textbf{Geo}metric \textbf{I}nformation \textbf{B}ottleneck (\textbf{GeoIB}) that dispenses with mutual information (MI) estimation. We show that I(X;Z) and I(Z;Y) admit exact projection forms as minimal Kullback-Leibler (KL) distances from the joint distributions to their respective independence manifolds. Guided by this view, GeoIB controls information compression with two complementary terms: (i) a distribution-level Fisher-Rao (FR) discrepancy, which matches KL to second order and is reparameterization-invariant; and (ii) a geometry-level Jacobian-Frobenius (JF) term that provides a local capacity-type upper bound on I(Z;X) by penalizing pullback volume expansion of the encoder. We further derive a natural-gradient optimizer consistent with the FR metric and prove that the standard additive natural-gradient step is first-order equivalent to the geodesic update. We conducted extensive experiments and observed that the GeoIB achieves a better trade-off between prediction accuracy and compression ratio in the information plane than the mainstream IB baselines on popular datasets. GeoIB improves invariance and optimization stability by unifying distributional and geometric regularization under a single bottleneck multiplier. The source code of GeoIB is released at "https://anonymous.4open.science/r/G-IB-0569".
BlindU: Blind Machine Unlearning without Revealing Erasing Data
Jan 12, 2026Machine unlearning enables data holders to remove the contribution of their specified samples from trained models to protect their privacy. However, it is paradoxical that most unlearning methods require the unlearning requesters to firstly upload their data to the server as a prerequisite for unlearning. These methods are infeasible in many privacy-preserving scenarios where servers are prohibited from accessing users' data, such as federated learning (FL). In this paper, we explore how to implement unlearning under the condition of not uncovering the erasing data to the server. We propose \textbf{Blind Unlearning (BlindU)}, which carries out unlearning using compressed representations instead of original inputs. BlindU only involves the server and the unlearning user: the user locally generates privacy-preserving representations, and the server performs unlearning solely on these representations and their labels. For the FL model training, we employ the information bottleneck (IB) mechanism. The encoder of the IB-based FL model learns representations that distort maximum task-irrelevant information from inputs, allowing FL users to generate compressed representations locally. For effective unlearning using compressed representation, BlindU integrates two dedicated unlearning modules tailored explicitly for IB-based models and uses a multiple gradient descent algorithm to balance forgetting and utility retaining. While IB compression already provides protection for task-irrelevant information of inputs, to further enhance the privacy protection, we introduce a noise-free differential privacy (DP) masking method to deal with the raw erasing data before compressing. Theoretical analysis and extensive experimental results illustrate the superiority of BlindU in privacy protection and unlearning effectiveness compared with the best existing privacy-preserving unlearning benchmarks.
TAPE: Tailored Posterior Difference for Auditing of Machine Unlearning
Feb 27, 2025With the increasing prevalence of Web-based platforms handling vast amounts of user data, machine unlearning has emerged as a crucial mechanism to uphold users' right to be forgotten, enabling individuals to request the removal of their specified data from trained models. However, the auditing of machine unlearning processes remains significantly underexplored. Although some existing methods offer unlearning auditing by leveraging backdoors, these backdoor-based approaches are inefficient and impractical, as they necessitate involvement in the initial model training process to embed the backdoors. In this paper, we propose a TAilored Posterior diffErence (TAPE) method to provide unlearning auditing independently of original model training. We observe that the process of machine unlearning inherently introduces changes in the model, which contains information related to the erased data. TAPE leverages unlearning model differences to assess how much information has been removed through the unlearning operation. Firstly, TAPE mimics the unlearned posterior differences by quickly building unlearned shadow models based on first-order influence estimation. Secondly, we train a Reconstructor model to extract and evaluate the private information of the unlearned posterior differences to audit unlearning. Existing privacy reconstructing methods based on posterior differences are only feasible for model updates of a single sample. To enable the reconstruction effective for multi-sample unlearning requests, we propose two strategies, unlearned data perturbation and unlearned influence-based division, to augment the posterior difference. Extensive experimental results indicate the significant superiority of TAPE over the state-of-the-art unlearning verification methods, at least 4.5$\times$ efficiency speedup and supporting the auditing for broader unlearning scenarios.
SCU: An Efficient Machine Unlearning Scheme for Deep Learning Enabled Semantic Communications
Feb 27, 2025Deep learning (DL) enabled semantic communications leverage DL to train encoders and decoders (codecs) to extract and recover semantic information. However, most semantic training datasets contain personal private information. Such concerns call for enormous requirements for specified data erasure from semantic codecs when previous users hope to move their data from the semantic system. {Existing machine unlearning solutions remove data contribution from trained models, yet usually in supervised sole model scenarios. These methods are infeasible in semantic communications that often need to jointly train unsupervised encoders and decoders.} In this paper, we investigate the unlearning problem in DL-enabled semantic communications and propose a semantic communication unlearning (SCU) scheme to tackle the problem. {SCU includes two key components. Firstly,} we customize the joint unlearning method for semantic codecs, including the encoder and decoder, by minimizing mutual information between the learned semantic representation and the erased samples. {Secondly,} to compensate for semantic model utility degradation caused by unlearning, we propose a contrastive compensation method, which considers the erased data as the negative samples and the remaining data as the positive samples to retrain the unlearned semantic models contrastively. Theoretical analysis and extensive experimental results on three representative datasets demonstrate the effectiveness and efficiency of our proposed methods.
Can Self Supervision Rejuvenate Similarity-Based Link Prediction?
Oct 24, 2024
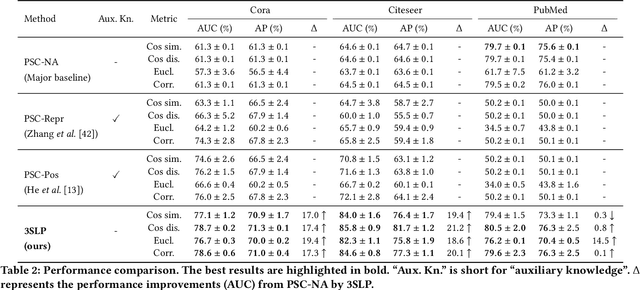
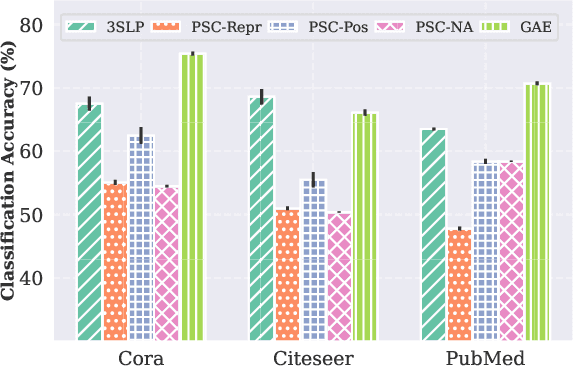
Although recent advancements in end-to-end learning-based link prediction (LP) methods have shown remarkable capabilities, the significance of traditional similarity-based LP methods persists in unsupervised scenarios where there are no known link labels. However, the selection of node features for similarity computation in similarity-based LP can be challenging. Less informative node features can result in suboptimal LP performance. To address these challenges, we integrate self-supervised graph learning techniques into similarity-based LP and propose a novel method: Self-Supervised Similarity-based LP (3SLP). 3SLP is suitable for the unsupervised condition of similarity-based LP without the assistance of known link labels. Specifically, 3SLP introduces a dual-view contrastive node representation learning (DCNRL) with crafted data augmentation and node representation learning. DCNRL is dedicated to developing more informative node representations, replacing the node attributes as inputs in the similarity-based LP backbone. Extensive experiments over benchmark datasets demonstrate the salient improvement of 3SLP, outperforming the baseline of traditional similarity-based LP by up to 21.2% (AUC).
Machine Unlearning: A Comprehensive Survey
May 13, 2024As the right to be forgotten has been legislated worldwide, many studies attempt to design unlearning mechanisms to protect users' privacy when they want to leave machine learning service platforms. Specifically, machine unlearning is to make a trained model to remove the contribution of an erased subset of the training dataset. This survey aims to systematically classify a wide range of machine unlearning and discuss their differences, connections and open problems. We categorize current unlearning methods into four scenarios: centralized unlearning, distributed and irregular data unlearning, unlearning verification, and privacy and security issues in unlearning. Since centralized unlearning is the primary domain, we use two parts to introduce: firstly, we classify centralized unlearning into exact unlearning and approximate unlearning; secondly, we offer a detailed introduction to the techniques of these methods. Besides the centralized unlearning, we notice some studies about distributed and irregular data unlearning and introduce federated unlearning and graph unlearning as the two representative directions. After introducing unlearning methods, we review studies about unlearning verification. Moreover, we consider the privacy and security issues essential in machine unlearning and organize the latest related literature. Finally, we discuss the challenges of various unlearning scenarios and address the potential research directions.