 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePro-ZD: A Transferable Graph Neural Network Approach for Proactive Zero-Day Threats Mitigation
Feb 06, 2026In today's enterprise network landscape, the combination of perimeter and distributed firewall rules governs connectivity. To address challenges arising from increased traffic and diverse network architectures, organizations employ automated tools for firewall rule and access policy generation. Yet, effectively managing risks arising from dynamically generated policies, especially concerning critical asset exposure, remains a major challenge. This challenge is amplified by evolving network structures due to trends like remote users, bring-your-own devices, and cloud integration. This paper introduces a novel graph neural network model for identifying weighted shortest paths. The model aids in detecting network misconfigurations and high-risk connectivity paths that threaten critical assets, potentially exploited in zero-day attacks -- cyber-attacks exploiting undisclosed vulnerabilities. The proposed Pro-ZD framework adopts a proactive approach, automatically fine-tuning firewall rules and access policies to address high-risk connections and prevent unauthorized access. Experimental results highlight the robustness and transferability of Pro-ZD, achieving over 95% average accuracy in detecting high-risk connections. \
Can Self Supervision Rejuvenate Similarity-Based Link Prediction?
Oct 24, 2024
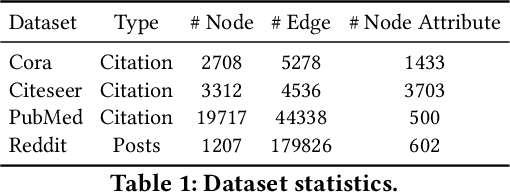
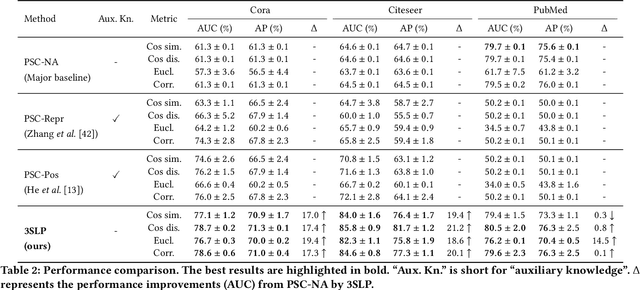
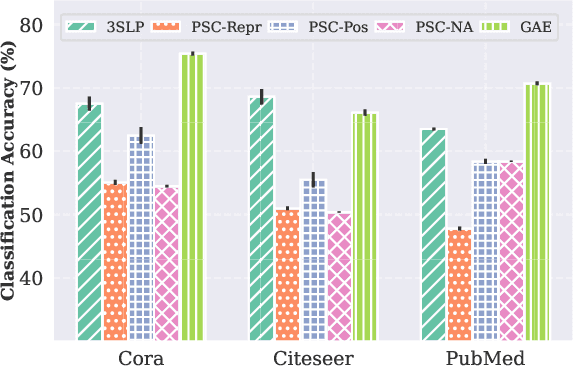
Although recent advancements in end-to-end learning-based link prediction (LP) methods have shown remarkable capabilities, the significance of traditional similarity-based LP methods persists in unsupervised scenarios where there are no known link labels. However, the selection of node features for similarity computation in similarity-based LP can be challenging. Less informative node features can result in suboptimal LP performance. To address these challenges, we integrate self-supervised graph learning techniques into similarity-based LP and propose a novel method: Self-Supervised Similarity-based LP (3SLP). 3SLP is suitable for the unsupervised condition of similarity-based LP without the assistance of known link labels. Specifically, 3SLP introduces a dual-view contrastive node representation learning (DCNRL) with crafted data augmentation and node representation learning. DCNRL is dedicated to developing more informative node representations, replacing the node attributes as inputs in the similarity-based LP backbone. Extensive experiments over benchmark datasets demonstrate the salient improvement of 3SLP, outperforming the baseline of traditional similarity-based LP by up to 21.2% (AUC).
On the Robustness of Malware Detectors to Adversarial Samples
Aug 05, 2024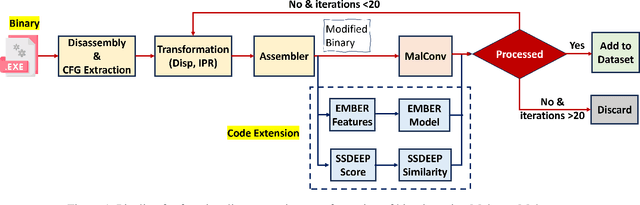
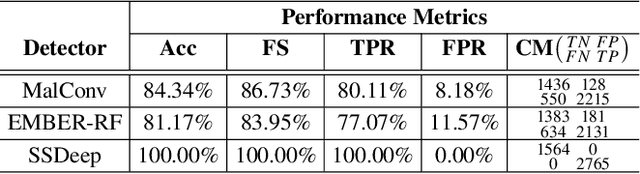
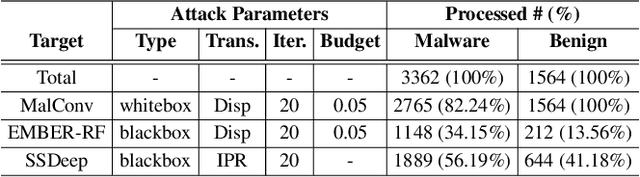
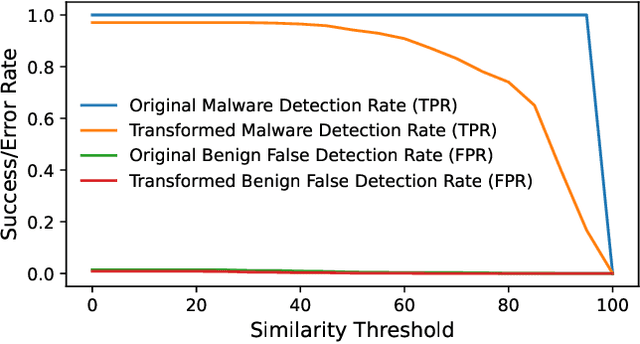
Adversarial examples add imperceptible alterations to inputs with the objective to induce misclassification in machine learning models. They have been demonstrated to pose significant challenges in domains like image classification, with results showing that an adversarially perturbed image to evade detection against one classifier is most likely transferable to other classifiers. Adversarial examples have also been studied in malware analysis. Unlike images, program binaries cannot be arbitrarily perturbed without rendering them non-functional. Due to the difficulty of crafting adversarial program binaries, there is no consensus on the transferability of adversarially perturbed programs to different detectors. In this work, we explore the robustness of malware detectors against adversarially perturbed malware. We investigate the transferability of adversarial attacks developed against one detector, against other machine learning-based malware detectors, and code similarity techniques, specifically, locality sensitive hashing-based detectors. Our analysis reveals that adversarial program binaries crafted for one detector are generally less effective against others. We also evaluate an ensemble of detectors and show that they can potentially mitigate the impact of adversarial program binaries. Finally, we demonstrate that substantial program changes made to evade detection may result in the transformation technique being identified, implying that the adversary must make minimal changes to the program binary.
ConvoCache: Smart Re-Use of Chatbot Responses
Jun 26, 2024



We present ConvoCache, a conversational caching system that solves the problem of slow and expensive generative AI models in spoken chatbots. ConvoCache finds a semantically similar prompt in the past and reuses the response. In this paper we evaluate ConvoCache on the DailyDialog dataset. We find that ConvoCache can apply a UniEval coherence threshold of 90% and respond to 89% of prompts using the cache with an average latency of 214ms, replacing LLM and voice synthesis that can take over 1s. To further reduce latency we test prefetching and find limited usefulness. Prefetching with 80% of a request leads to a 63% hit rate, and a drop in overall coherence. ConvoCache can be used with any chatbot to reduce costs by reducing usage of generative AI by up to 89%.
SPGNN-API: A Transferable Graph Neural Network for Attack Paths Identification and Autonomous Mitigation
May 31, 2023Attack paths are the potential chain of malicious activities an attacker performs to compromise network assets and acquire privileges through exploiting network vulnerabilities. Attack path analysis helps organizations to identify new/unknown chains of attack vectors that reach critical assets within the network, as opposed to individual attack vectors in signature-based attack analysis. Timely identification of attack paths enables proactive mitigation of threats. Nevertheless, manual analysis of complex network configurations, vulnerabilities, and security events to identify attack paths is rarely feasible. This work proposes a novel transferable graph neural network-based model for shortest path identification. The proposed shortest path detection approach, integrated with a novel holistic and comprehensive model for identifying potential network vulnerabilities interactions, is then utilized to detect network attack paths. Our framework automates the risk assessment of attack paths indicating the propensity of the paths to enable the compromise of highly-critical assets (e.g., databases) given the network configuration, assets' criticality, and the severity of the vulnerabilities in-path to the asset. The proposed framework, named SPGNN-API, incorporates automated threat mitigation through a proactive timely tuning of the network firewall rules and zero-trust policies to break critical attack paths and bolster cyber defenses. Our evaluation process is twofold; evaluating the performance of the shortest path identification and assessing the attack path detection accuracy. Our results show that SPGNN-API largely outperforms the baseline model for shortest path identification with an average accuracy >= 95% and successfully detects 100% of the potentially compromised assets, outperforming the attack graph baseline by 47%.
Those Aren't Your Memories, They're Somebody Else's: Seeding Misinformation in Chat Bot Memories
Apr 06, 2023



One of the new developments in chit-chat bots is a long-term memory mechanism that remembers information from past conversations for increasing engagement and consistency of responses. The bot is designed to extract knowledge of personal nature from their conversation partner, e.g., stating preference for a particular color. In this paper, we show that this memory mechanism can result in unintended behavior. In particular, we found that one can combine a personal statement with an informative statement that would lead the bot to remember the informative statement alongside personal knowledge in its long term memory. This means that the bot can be tricked into remembering misinformation which it would regurgitate as statements of fact when recalling information relevant to the topic of conversation. We demonstrate this vulnerability on the BlenderBot 2 framework implemented on the ParlAI platform and provide examples on the more recent and significantly larger BlenderBot 3 model. We generate 150 examples of misinformation, of which 114 (76%) were remembered by BlenderBot 2 when combined with a personal statement. We further assessed the risk of this misinformation being recalled after intervening innocuous conversation and in response to multiple questions relevant to the injected memory. Our evaluation was performed on both the memory-only and the combination of memory and internet search modes of BlenderBot 2. From the combinations of these variables, we generated 12,890 conversations and analyzed recalled misinformation in the responses. We found that when the chat bot is questioned on the misinformation topic, it was 328% more likely to respond with the misinformation as fact when the misinformation was in the long-term memory.
Privacy-Preserving Record Linkage for Cardinality Counting
Jan 09, 2023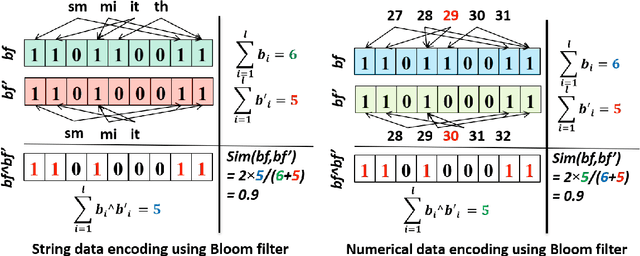
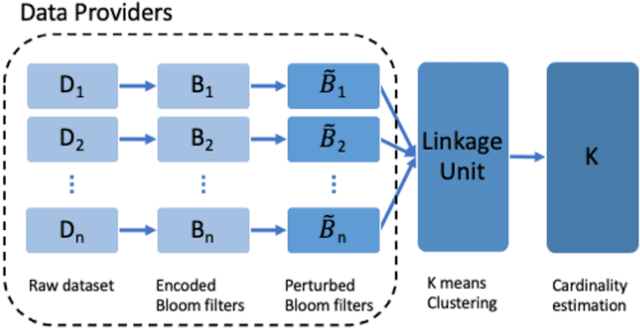
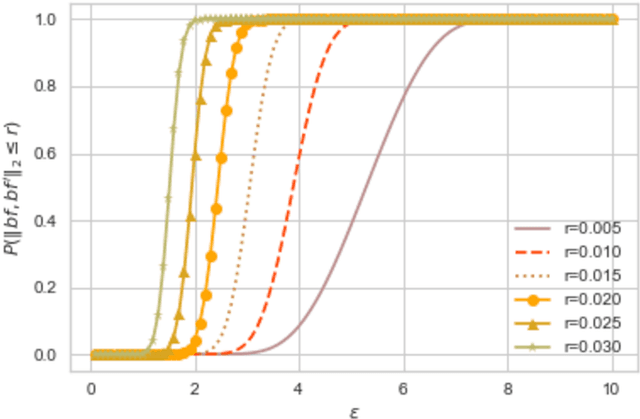
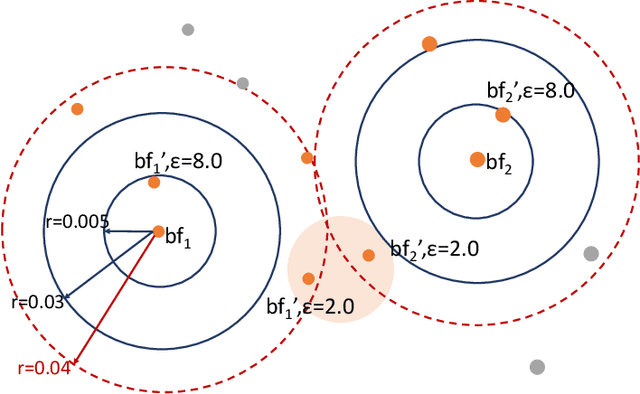
Several applications require counting the number of distinct items in the data, which is known as the cardinality counting problem. Example applications include health applications such as rare disease patients counting for adequate awareness and funding, and counting the number of cases of a new disease for outbreak detection, marketing applications such as counting the visibility reached for a new product, and cybersecurity applications such as tracking the number of unique views of social media posts. The data needed for the counting is however often personal and sensitive, and need to be processed using privacy-preserving techniques. The quality of data in different databases, for example typos, errors and variations, poses additional challenges for accurate cardinality estimation. While privacy-preserving cardinality counting has gained much attention in the recent times and a few privacy-preserving algorithms have been developed for cardinality estimation, no work has so far been done on privacy-preserving cardinality counting using record linkage techniques with fuzzy matching and provable privacy guarantees. We propose a novel privacy-preserving record linkage algorithm using unsupervised clustering techniques to link and count the cardinality of individuals in multiple datasets without compromising their privacy or identity. In addition, existing Elbow methods to find the optimal number of clusters as the cardinality are far from accurate as they do not take into account the purity and completeness of generated clusters. We propose a novel method to find the optimal number of clusters in unsupervised learning. Our experimental results on real and synthetic datasets are highly promising in terms of significantly smaller error rate of less than 0.1 with a privacy budget {\epsilon} = 1.0 compared to the state-of-the-art fuzzy matching and clustering method.
A Differentially Private Framework for Deep Learning with Convexified Loss Functions
Apr 03, 2022

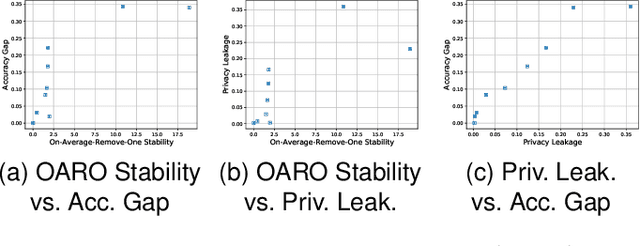
Differential privacy (DP) has been applied in deep learning for preserving privacy of the underlying training sets. Existing DP practice falls into three categories - objective perturbation, gradient perturbation and output perturbation. They suffer from three main problems. First, conditions on objective functions limit objective perturbation in general deep learning tasks. Second, gradient perturbation does not achieve a satisfactory privacy-utility trade-off due to over-injected noise in each epoch. Third, high utility of the output perturbation method is not guaranteed because of the loose upper bound on the global sensitivity of the trained model parameters as the noise scale parameter. To address these problems, we analyse a tighter upper bound on the global sensitivity of the model parameters. Under a black-box setting, based on this global sensitivity, to control the overall noise injection, we propose a novel output perturbation framework by injecting DP noise into a randomly sampled neuron (via the exponential mechanism) at the output layer of a baseline non-private neural network trained with a convexified loss function. We empirically compare the privacy-utility trade-off, measured by accuracy loss to baseline non-private models and the privacy leakage against black-box membership inference (MI) attacks, between our framework and the open-source differentially private stochastic gradient descent (DP-SGD) approaches on six commonly used real-world datasets. The experimental evaluations show that, when the baseline models have observable privacy leakage under MI attacks, our framework achieves a better privacy-utility trade-off than existing DP-SGD implementations, given an overall privacy budget $\epsilon \leq 1$ for a large number of queries.
On the (In)Feasibility of Attribute Inference Attacks on Machine Learning Models
Mar 12, 2021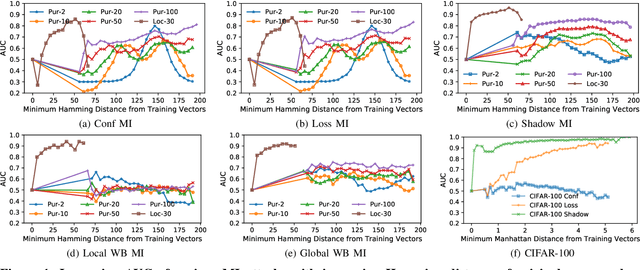
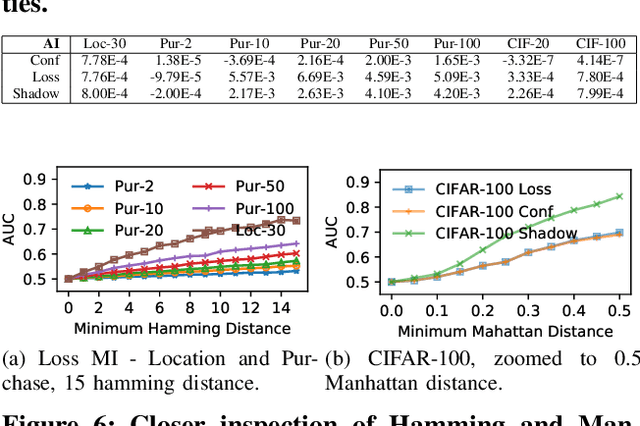
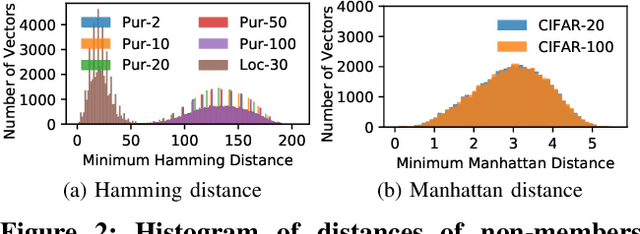
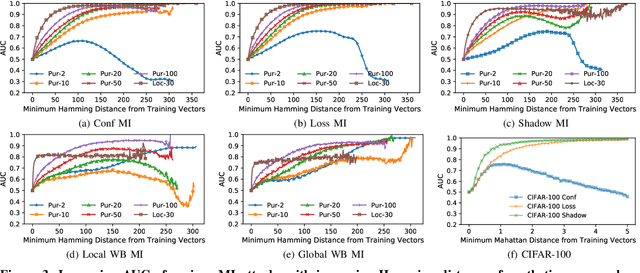
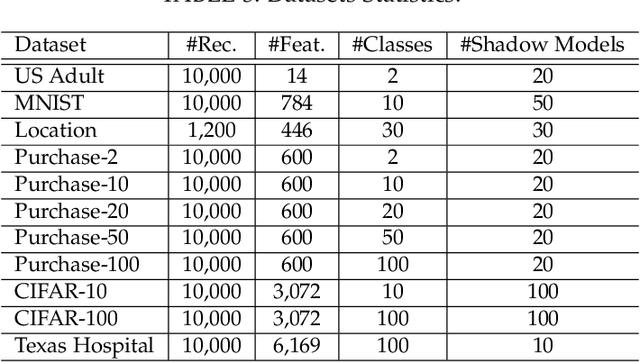
With an increase in low-cost machine learning APIs, advanced machine learning models may be trained on private datasets and monetized by providing them as a service. However, privacy researchers have demonstrated that these models may leak information about records in the training dataset via membership inference attacks. In this paper, we take a closer look at another inference attack reported in literature, called attribute inference, whereby an attacker tries to infer missing attributes of a partially known record used in the training dataset by accessing the machine learning model as an API. We show that even if a classification model succumbs to membership inference attacks, it is unlikely to be susceptible to attribute inference attacks. We demonstrate that this is because membership inference attacks fail to distinguish a member from a nearby non-member. We call the ability of an attacker to distinguish the two (similar) vectors as strong membership inference. We show that membership inference attacks cannot infer membership in this strong setting, and hence inferring attributes is infeasible. However, under a relaxed notion of attribute inference, called approximate attribute inference, we show that it is possible to infer attributes close to the true attributes. We verify our results on three publicly available datasets, five membership, and three attribute inference attacks reported in literature.
Predicting Performance of Asynchronous Differentially-Private Learning
Mar 18, 2020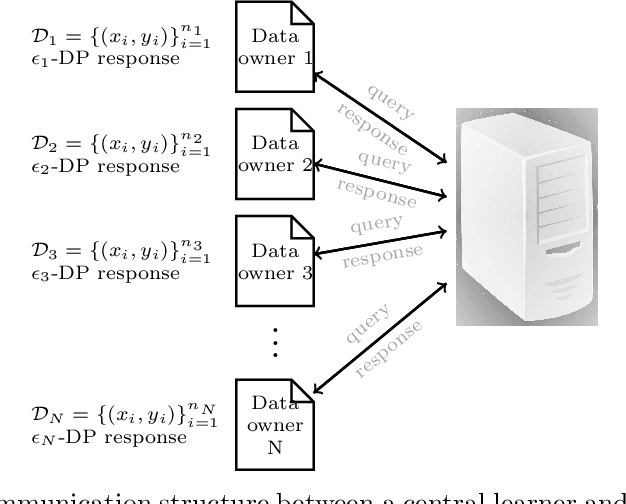
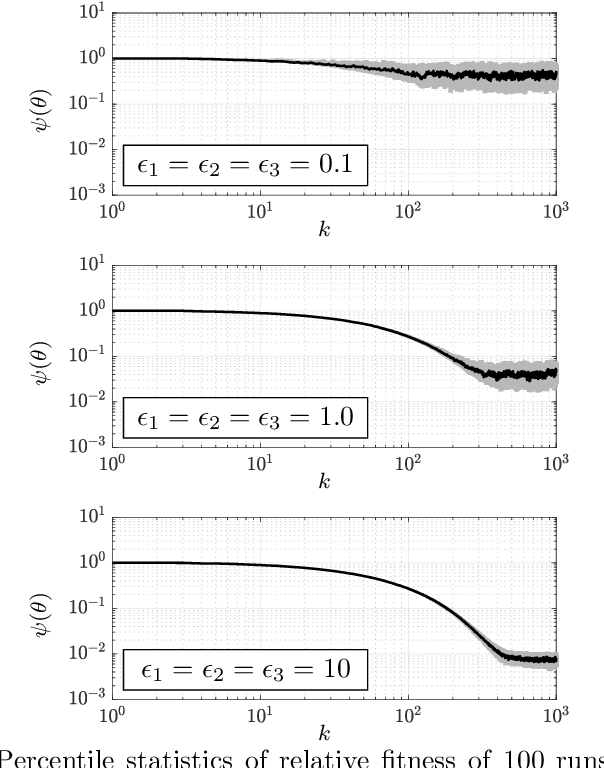

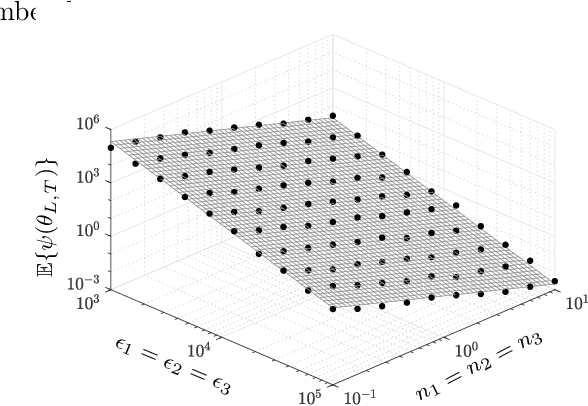
We consider training machine learning models using Training data located on multiple private and geographically-scattered servers with different privacy settings. Due to the distributed nature of the data, communicating with all collaborating private data owners simultaneously may prove challenging or altogether impossible. In this paper, we develop differentially-private asynchronous algorithms for collaboratively training machine-learning models on multiple private datasets. The asynchronous nature of the algorithms implies that a central learner interacts with the private data owners one-on-one whenever they are available for communication without needing to aggregate query responses to construct gradients of the entire fitness function. Therefore, the algorithm efficiently scales to many data owners. We define the cost of privacy as the difference between the fitness of a privacy-preserving machine-learning model and the fitness of trained machine-learning model in the absence of privacy concerns. We prove that we can forecast the performance of the proposed privacy-preserving asynchronous algorithms. We demonstrate that the cost of privacy has an upper bound that is inversely proportional to the combined size of the training datasets squared and the sum of the privacy budgets squared. We validate the theoretical results with experiments on financial and medical datasets. The experiments illustrate that collaboration among more than 10 data owners with at least 10,000 records with privacy budgets greater than or equal to 1 results in a superior machine-learning model in comparison to a model trained in isolation on only one of the datasets, illustrating the value of collaboration and the cost of the privacy. The number of the collaborating datasets can be lowered if the privacy budget is higher.