 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Differentially Private Framework for Deep Learning with Convexified Loss Functions
Apr 03, 2022

Differential privacy (DP) has been applied in deep learning for preserving privacy of the underlying training sets. Existing DP practice falls into three categories - objective perturbation, gradient perturbation and output perturbation. They suffer from three main problems. First, conditions on objective functions limit objective perturbation in general deep learning tasks. Second, gradient perturbation does not achieve a satisfactory privacy-utility trade-off due to over-injected noise in each epoch. Third, high utility of the output perturbation method is not guaranteed because of the loose upper bound on the global sensitivity of the trained model parameters as the noise scale parameter. To address these problems, we analyse a tighter upper bound on the global sensitivity of the model parameters. Under a black-box setting, based on this global sensitivity, to control the overall noise injection, we propose a novel output perturbation framework by injecting DP noise into a randomly sampled neuron (via the exponential mechanism) at the output layer of a baseline non-private neural network trained with a convexified loss function. We empirically compare the privacy-utility trade-off, measured by accuracy loss to baseline non-private models and the privacy leakage against black-box membership inference (MI) attacks, between our framework and the open-source differentially private stochastic gradient descent (DP-SGD) approaches on six commonly used real-world datasets. The experimental evaluations show that, when the baseline models have observable privacy leakage under MI attacks, our framework achieves a better privacy-utility trade-off than existing DP-SGD implementations, given an overall privacy budget $\epsilon \leq 1$ for a large number of queries.
On the (In)Feasibility of Attribute Inference Attacks on Machine Learning Models
Mar 12, 2021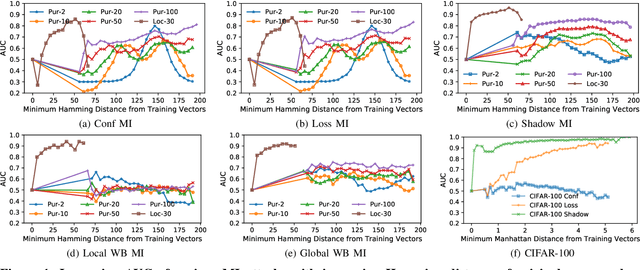
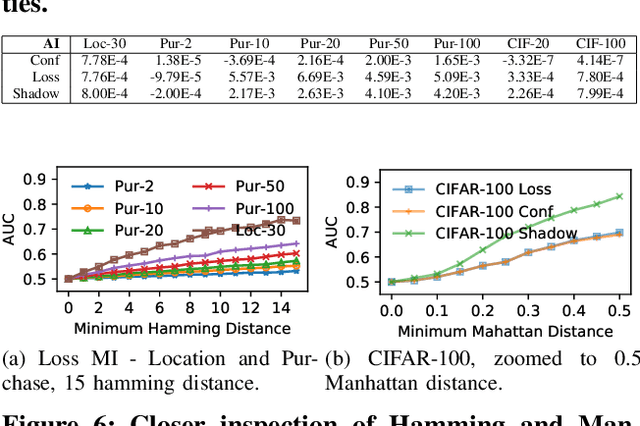
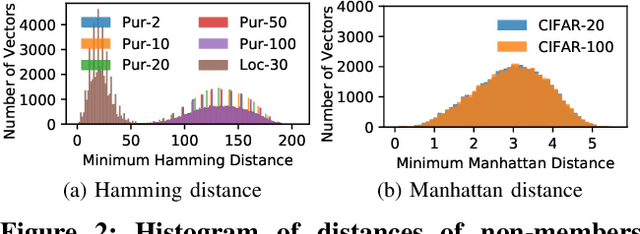
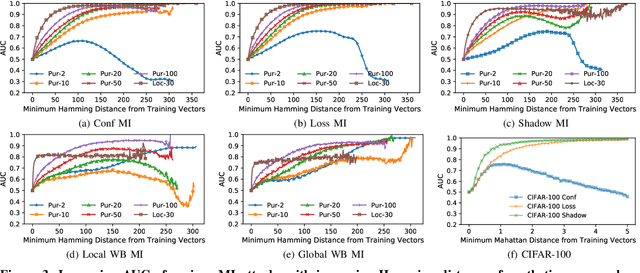
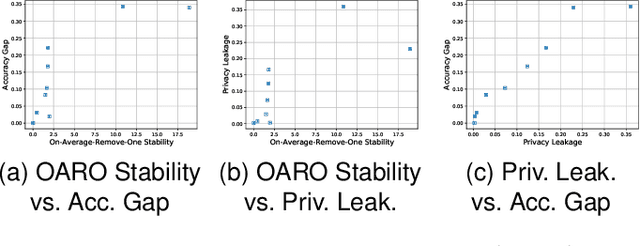
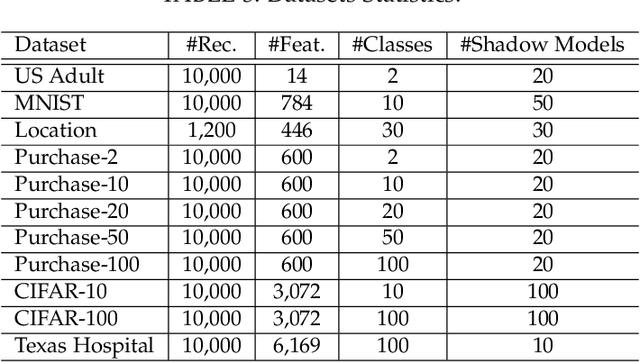
With an increase in low-cost machine learning APIs, advanced machine learning models may be trained on private datasets and monetized by providing them as a service. However, privacy researchers have demonstrated that these models may leak information about records in the training dataset via membership inference attacks. In this paper, we take a closer look at another inference attack reported in literature, called attribute inference, whereby an attacker tries to infer missing attributes of a partially known record used in the training dataset by accessing the machine learning model as an API. We show that even if a classification model succumbs to membership inference attacks, it is unlikely to be susceptible to attribute inference attacks. We demonstrate that this is because membership inference attacks fail to distinguish a member from a nearby non-member. We call the ability of an attacker to distinguish the two (similar) vectors as strong membership inference. We show that membership inference attacks cannot infer membership in this strong setting, and hence inferring attributes is infeasible. However, under a relaxed notion of attribute inference, called approximate attribute inference, we show that it is possible to infer attributes close to the true attributes. We verify our results on three publicly available datasets, five membership, and three attribute inference attacks reported in literature.