 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTIGuardian: A Few-Shot Framework for Mitigating Privacy Leakage in Fine-Tuned LLMs
Dec 15, 2025Large Language Models (LLMs) are often fine-tuned to adapt their general-purpose knowledge to specific tasks and domains such as cyber threat intelligence (CTI). Fine-tuning is mostly done through proprietary datasets that may contain sensitive information. Owners expect their fine-tuned model to not inadvertently leak this information to potentially adversarial end users. Using CTI as a use case, we demonstrate that data-extraction attacks can recover sensitive information from fine-tuned models on CTI reports, underscoring the need for mitigation. Retraining the full model to eliminate this leakage is computationally expensive and impractical. We propose an alternative approach, which we call privacy alignment, inspired by safety alignment in LLMs. Just like safety alignment teaches the model to abide by safety constraints through a few examples, we enforce privacy alignment through few-shot supervision, integrating a privacy classifier and a privacy redactor, both handled by the same underlying LLM. We evaluate our system, called CTIGuardian, using GPT-4o mini and Mistral-7B Instruct models, benchmarking against Presidio, a named entity recognition (NER) baseline. Results show that CTIGuardian provides a better privacy-utility trade-off than NER based models. While we demonstrate its effectiveness on a CTI use case, the framework is generic enough to be applicable to other sensitive domains.
A Large-Scale Empirical Analysis of Custom GPTs' Vulnerabilities in the OpenAI Ecosystem
May 13, 2025Millions of users leverage generative pretrained transformer (GPT)-based language models developed by leading model providers for a wide range of tasks. To support enhanced user interaction and customization, many platforms-such as OpenAI-now enable developers to create and publish tailored model instances, known as custom GPTs, via dedicated repositories or application stores. These custom GPTs empower users to browse and interact with specialized applications designed to meet specific needs. However, as custom GPTs see growing adoption, concerns regarding their security vulnerabilities have intensified. Existing research on these vulnerabilities remains largely theoretical, often lacking empirical, large-scale, and statistically rigorous assessments of associated risks. In this study, we analyze 14,904 custom GPTs to assess their susceptibility to seven exploitable threats, such as roleplay-based attacks, system prompt leakage, phishing content generation, and malicious code synthesis, across various categories and popularity tiers within the OpenAI marketplace. We introduce a multi-metric ranking system to examine the relationship between a custom GPT's popularity and its associated security risks. Our findings reveal that over 95% of custom GPTs lack adequate security protections. The most prevalent vulnerabilities include roleplay-based vulnerabilities (96.51%), system prompt leakage (92.20%), and phishing (91.22%). Furthermore, we demonstrate that OpenAI's foundational models exhibit inherent security weaknesses, which are often inherited or amplified in custom GPTs. These results highlight the urgent need for enhanced security measures and stricter content moderation to ensure the safe deployment of GPT-based applications.
Targeted Therapy in Data Removal: Object Unlearning Based on Scene Graphs
Nov 25, 2024
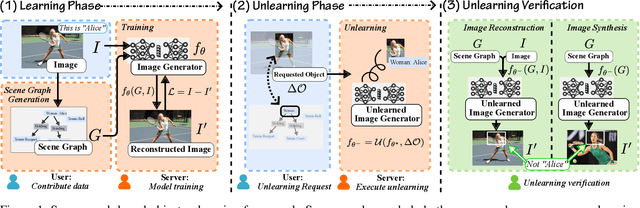


Users may inadvertently upload personally identifiable information (PII) to Machine Learning as a Service (MLaaS) providers. When users no longer want their PII on these services, regulations like GDPR and COPPA mandate a right to forget for these users. As such, these services seek efficient methods to remove the influence of specific data points. Thus the introduction of machine unlearning. Traditionally, unlearning is performed with the removal of entire data samples (sample unlearning) or whole features across the dataset (feature unlearning). However, these approaches are not equipped to handle the more granular and challenging task of unlearning specific objects within a sample. To address this gap, we propose a scene graph-based object unlearning framework. This framework utilizes scene graphs, rich in semantic representation, transparently translate unlearning requests into actionable steps. The result, is the preservation of the overall semantic integrity of the generated image, bar the unlearned object. Further, we manage high computational overheads with influence functions to approximate the unlearning process. For validation, we evaluate the unlearned object's fidelity in outputs under the tasks of image reconstruction and image synthesis. Our proposed framework demonstrates improved object unlearning outcomes, with the preservation of unrequested samples in contrast to sample and feature learning methods. This work addresses critical privacy issues by increasing the granularity of targeted machine unlearning through forgetting specific object-level details without sacrificing the utility of the whole data sample or dataset feature.
Preempting Text Sanitization Utility in Resource-Constrained Privacy-Preserving LLM Interactions
Nov 18, 2024Individuals have been increasingly interacting with online Large Language Models (LLMs), both in their work and personal lives. These interactions raise privacy issues as the LLMs are typically hosted by third-parties who can gather a variety of sensitive information about users and their companies. Text Sanitization techniques have been proposed in the literature and can be used to sanitize user prompts before sending them to the LLM. However, sanitization has an impact on the downstream task performed by the LLM, and often to such an extent that it leads to unacceptable results for the user. This is not just a minor annoyance, with clear monetary consequences as LLM services charge on a per use basis as well as great amount of computing resources wasted. We propose an architecture leveraging a Small Language Model (SLM) at the user-side to help estimate the impact of sanitization on a prompt before it is sent to the LLM, thus preventing resource losses. Our evaluation of this architecture revealed a significant problem with text sanitization based on Differential Privacy, on which we want to draw the attention of the community for further investigation.
On the Robustness of Malware Detectors to Adversarial Samples
Aug 05, 2024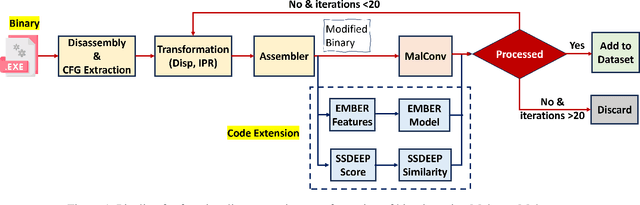
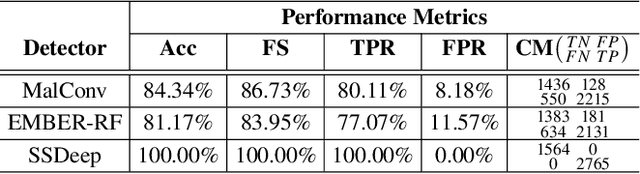
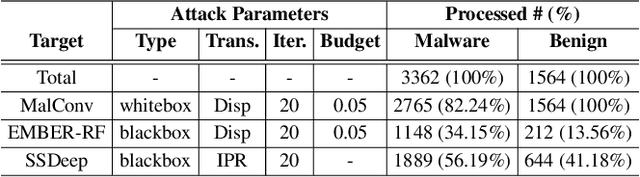
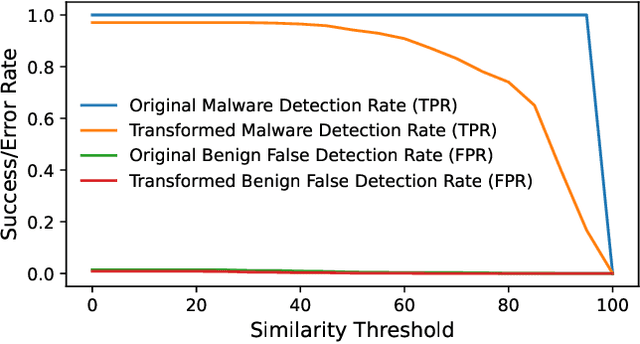
Adversarial examples add imperceptible alterations to inputs with the objective to induce misclassification in machine learning models. They have been demonstrated to pose significant challenges in domains like image classification, with results showing that an adversarially perturbed image to evade detection against one classifier is most likely transferable to other classifiers. Adversarial examples have also been studied in malware analysis. Unlike images, program binaries cannot be arbitrarily perturbed without rendering them non-functional. Due to the difficulty of crafting adversarial program binaries, there is no consensus on the transferability of adversarially perturbed programs to different detectors. In this work, we explore the robustness of malware detectors against adversarially perturbed malware. We investigate the transferability of adversarial attacks developed against one detector, against other machine learning-based malware detectors, and code similarity techniques, specifically, locality sensitive hashing-based detectors. Our analysis reveals that adversarial program binaries crafted for one detector are generally less effective against others. We also evaluate an ensemble of detectors and show that they can potentially mitigate the impact of adversarial program binaries. Finally, we demonstrate that substantial program changes made to evade detection may result in the transformation technique being identified, implying that the adversary must make minimal changes to the program binary.
Privacy-Preserving Aggregation for Decentralized Learning with Byzantine-Robustness
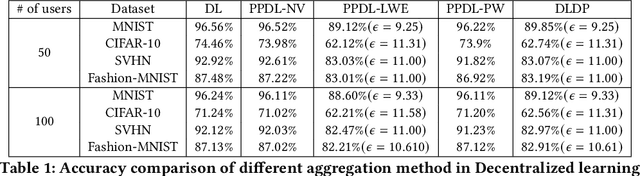
Apr 27, 2024Decentralized machine learning (DL) has been receiving an increasing interest recently due to the elimination of a single point of failure, present in Federated learning setting. Yet, it is threatened by the looming threat of Byzantine clients who intentionally disrupt the learning process by broadcasting arbitrary model updates to other clients, seeking to degrade the performance of the global model. In response, robust aggregation schemes have emerged as promising solutions to defend against such Byzantine clients, thereby enhancing the robustness of Decentralized Learning. Defenses against Byzantine adversaries, however, typically require access to the updates of other clients, a counterproductive privacy trade-off that in turn increases the risk of inference attacks on those same model updates. In this paper, we introduce SecureDL, a novel DL protocol designed to enhance the security and privacy of DL against Byzantine threats. SecureDL~facilitates a collaborative defense, while protecting the privacy of clients' model updates through secure multiparty computation. The protocol employs efficient computation of cosine similarity and normalization of updates to robustly detect and exclude model updates detrimental to model convergence. By using MNIST, Fashion-MNIST, SVHN and CIFAR-10 datasets, we evaluated SecureDL against various Byzantine attacks and compared its effectiveness with four existing defense mechanisms. Our experiments show that SecureDL is effective even in the case of attacks by the malicious majority (e.g., 80% Byzantine clients) while preserving high training accuracy.
Privacy-Preserving, Dropout-Resilient Aggregation in Decentralized Learning
Apr 27, 2024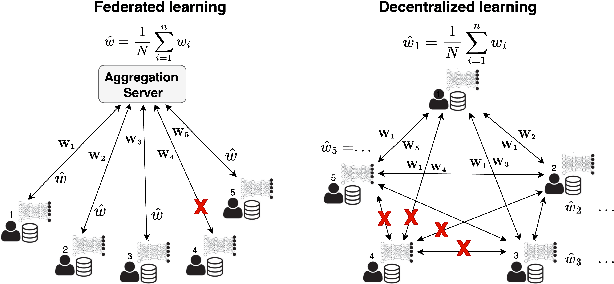


Decentralized learning (DL) offers a novel paradigm in machine learning by distributing training across clients without central aggregation, enhancing scalability and efficiency. However, DL's peer-to-peer model raises challenges in protecting against inference attacks and privacy leaks. By forgoing central bottlenecks, DL demands privacy-preserving aggregation methods to protect data from 'honest but curious' clients and adversaries, maintaining network-wide privacy. Privacy-preserving DL faces the additional hurdle of client dropout, clients not submitting updates due to connectivity problems or unavailability, further complicating aggregation. This work proposes three secret sharing-based dropout resilience approaches for privacy-preserving DL. Our study evaluates the efficiency, performance, and accuracy of these protocols through experiments on datasets such as MNIST, Fashion-MNIST, SVHN, and CIFAR-10. We compare our protocols with traditional secret-sharing solutions across scenarios, including those with up to 1000 clients. Evaluations show that our protocols significantly outperform conventional methods, especially in scenarios with up to 30% of clients dropout and model sizes of up to $10^6$ parameters. Our approaches demonstrate markedly high efficiency with larger models, higher dropout rates, and extensive client networks, highlighting their effectiveness in enhancing decentralized learning systems' privacy and dropout robustness.
Those Aren't Your Memories, They're Somebody Else's: Seeding Misinformation in Chat Bot Memories
Apr 06, 2023



One of the new developments in chit-chat bots is a long-term memory mechanism that remembers information from past conversations for increasing engagement and consistency of responses. The bot is designed to extract knowledge of personal nature from their conversation partner, e.g., stating preference for a particular color. In this paper, we show that this memory mechanism can result in unintended behavior. In particular, we found that one can combine a personal statement with an informative statement that would lead the bot to remember the informative statement alongside personal knowledge in its long term memory. This means that the bot can be tricked into remembering misinformation which it would regurgitate as statements of fact when recalling information relevant to the topic of conversation. We demonstrate this vulnerability on the BlenderBot 2 framework implemented on the ParlAI platform and provide examples on the more recent and significantly larger BlenderBot 3 model. We generate 150 examples of misinformation, of which 114 (76%) were remembered by BlenderBot 2 when combined with a personal statement. We further assessed the risk of this misinformation being recalled after intervening innocuous conversation and in response to multiple questions relevant to the injected memory. Our evaluation was performed on both the memory-only and the combination of memory and internet search modes of BlenderBot 2. From the combinations of these variables, we generated 12,890 conversations and analyzed recalled misinformation in the responses. We found that when the chat bot is questioned on the misinformation topic, it was 328% more likely to respond with the misinformation as fact when the misinformation was in the long-term memory.
DDoD: Dual Denial of Decision Attacks on Human-AI Teams
Dec 07, 2022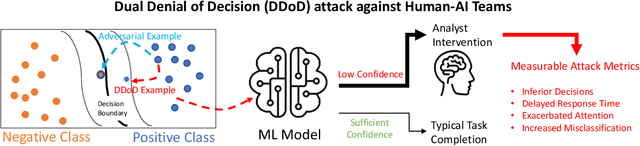
Artificial Intelligence (AI) systems have been increasingly used to make decision-making processes faster, more accurate, and more efficient. However, such systems are also at constant risk of being attacked. While the majority of attacks targeting AI-based applications aim to manipulate classifiers or training data and alter the output of an AI model, recently proposed Sponge Attacks against AI models aim to impede the classifier's execution by consuming substantial resources. In this work, we propose \textit{Dual Denial of Decision (DDoD) attacks against collaborative Human-AI teams}. We discuss how such attacks aim to deplete \textit{both computational and human} resources, and significantly impair decision-making capabilities. We describe DDoD on human and computational resources and present potential risk scenarios in a series of exemplary domains.
Unintended Memorization and Timing Attacks in Named Entity Recognition Models
Nov 04, 2022



Named entity recognition models (NER), are widely used for identifying named entities (e.g., individuals, locations, and other information) in text documents. Machine learning based NER models are increasingly being applied in privacy-sensitive applications that need automatic and scalable identification of sensitive information to redact text for data sharing. In this paper, we study the setting when NER models are available as a black-box service for identifying sensitive information in user documents and show that these models are vulnerable to membership inference on their training datasets. With updated pre-trained NER models from spaCy, we demonstrate two distinct membership attacks on these models. Our first attack capitalizes on unintended memorization in the NER's underlying neural network, a phenomenon NNs are known to be vulnerable to. Our second attack leverages a timing side-channel to target NER models that maintain vocabularies constructed from the training data. We show that different functional paths of words within the training dataset in contrast to words not previously seen have measurable differences in execution time. Revealing membership status of training samples has clear privacy implications, e.g., in text redaction, sensitive words or phrases to be found and removed, are at risk of being detected in the training dataset. Our experimental evaluation includes the redaction of both password and health data, presenting both security risks and privacy/regulatory issues. This is exacerbated by results that show memorization with only a single phrase. We achieved 70% AUC in our first attack on a text redaction use-case. We also show overwhelming success in the timing attack with 99.23% AUC. Finally we discuss potential mitigation approaches to realize the safe use of NER models in light of the privacy and security implications of membership inference attacks.