 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmerging Threats and Countermeasures in Neuromorphic Systems: A Survey
Jan 23, 2026Neuromorphic computing mimics brain-inspired mechanisms through spiking neurons and energy-efficient processing, offering a pathway to efficient in-memory computing (IMC). However, these advancements raise critical security and privacy concerns. As the adoption of bio-inspired architectures and memristive devices increases, so does the urgency to assess the vulnerability of these emerging technologies to hardware and software attacks. Emerging architectures introduce new attack surfaces, particularly due to asynchronous, event-driven processing and stochastic device behavior. The integration of memristors into neuromorphic hardware and software implementations in spiking neural networks offers diverse possibilities for advanced computing architectures, including their role in security-aware applications. This survey systematically analyzes the security landscape of neuromorphic systems, covering attack methodologies, side-channel vulnerabilities, and countermeasures. We focus on both hardware and software concerns relevant to spiking neural networks (SNNs) and hardware primitives, such as Physical Unclonable Functions (PUFs) and True Random Number Generators (TRNGs) for cryptographic and secure computation applications. We approach this analysis from diverse perspectives, from attack methodologies to countermeasure strategies that integrate efficiency and protection in brain-inspired hardware. This review not only maps the current landscape of security threats but provides a foundation for developing secure and trustworthy neuromorphic architectures.
Undesirable Memorization in Large Language Models: A Survey
Oct 03, 2024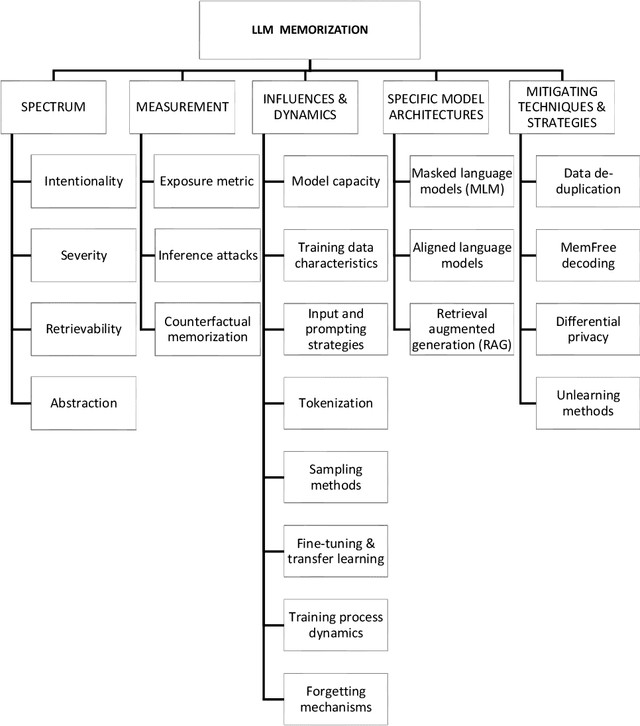


While recent research increasingly showcases the remarkable capabilities of Large Language Models (LLMs), it's vital to confront their hidden pitfalls. Among these challenges, the issue of memorization stands out, posing significant ethical and legal risks. In this paper, we presents a Systematization of Knowledge (SoK) on the topic of memorization in LLMs. Memorization is the effect that a model tends to store and reproduce phrases or passages from the training data and has been shown to be the fundamental issue to various privacy and security attacks against LLMs. We begin by providing an overview of the literature on the memorization, exploring it across five key dimensions: intentionality, degree, retrievability, abstraction, and transparency. Next, we discuss the metrics and methods used to measure memorization, followed by an analysis of the factors that contribute to memorization phenomenon. We then examine how memorization manifests itself in specific model architectures and explore strategies for mitigating these effects. We conclude our overview by identifying potential research topics for the near future: to develop methods for balancing performance and privacy in LLMs, and the analysis of memorization in specific contexts, including conversational agents, retrieval-augmented generation, multilingual language models, and diffusion language models.
Privacy-Preserving Aggregation for Decentralized Learning with Byzantine-Robustness
Apr 27, 2024Decentralized machine learning (DL) has been receiving an increasing interest recently due to the elimination of a single point of failure, present in Federated learning setting. Yet, it is threatened by the looming threat of Byzantine clients who intentionally disrupt the learning process by broadcasting arbitrary model updates to other clients, seeking to degrade the performance of the global model. In response, robust aggregation schemes have emerged as promising solutions to defend against such Byzantine clients, thereby enhancing the robustness of Decentralized Learning. Defenses against Byzantine adversaries, however, typically require access to the updates of other clients, a counterproductive privacy trade-off that in turn increases the risk of inference attacks on those same model updates. In this paper, we introduce SecureDL, a novel DL protocol designed to enhance the security and privacy of DL against Byzantine threats. SecureDL~facilitates a collaborative defense, while protecting the privacy of clients' model updates through secure multiparty computation. The protocol employs efficient computation of cosine similarity and normalization of updates to robustly detect and exclude model updates detrimental to model convergence. By using MNIST, Fashion-MNIST, SVHN and CIFAR-10 datasets, we evaluated SecureDL against various Byzantine attacks and compared its effectiveness with four existing defense mechanisms. Our experiments show that SecureDL is effective even in the case of attacks by the malicious majority (e.g., 80% Byzantine clients) while preserving high training accuracy.
Privacy-Preserving, Dropout-Resilient Aggregation in Decentralized Learning
Apr 27, 2024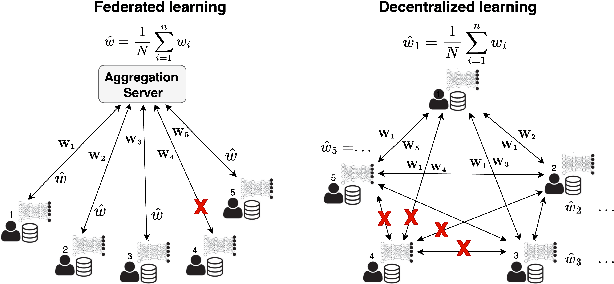
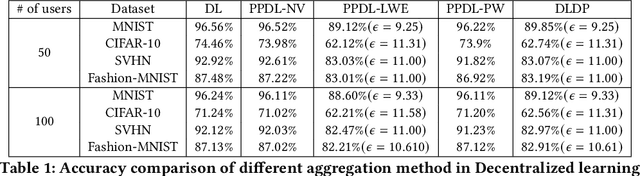


Decentralized learning (DL) offers a novel paradigm in machine learning by distributing training across clients without central aggregation, enhancing scalability and efficiency. However, DL's peer-to-peer model raises challenges in protecting against inference attacks and privacy leaks. By forgoing central bottlenecks, DL demands privacy-preserving aggregation methods to protect data from 'honest but curious' clients and adversaries, maintaining network-wide privacy. Privacy-preserving DL faces the additional hurdle of client dropout, clients not submitting updates due to connectivity problems or unavailability, further complicating aggregation. This work proposes three secret sharing-based dropout resilience approaches for privacy-preserving DL. Our study evaluates the efficiency, performance, and accuracy of these protocols through experiments on datasets such as MNIST, Fashion-MNIST, SVHN, and CIFAR-10. We compare our protocols with traditional secret-sharing solutions across scenarios, including those with up to 1000 clients. Evaluations show that our protocols significantly outperform conventional methods, especially in scenarios with up to 30% of clients dropout and model sizes of up to $10^6$ parameters. Our approaches demonstrate markedly high efficiency with larger models, higher dropout rates, and extensive client networks, highlighting their effectiveness in enhancing decentralized learning systems' privacy and dropout robustness.
Privacy-preserving Logistic Regression with Secret Sharing
May 14, 2021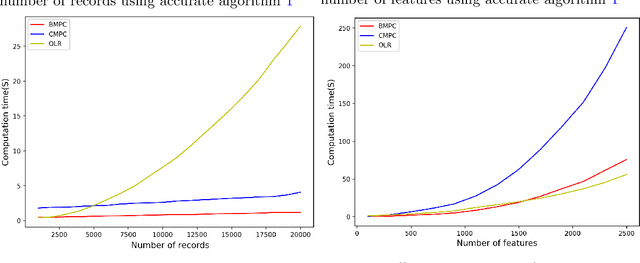
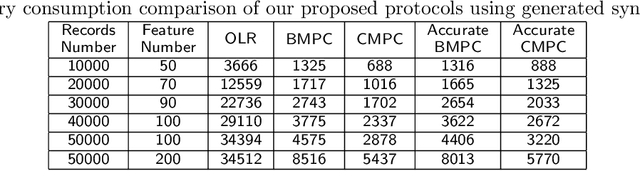
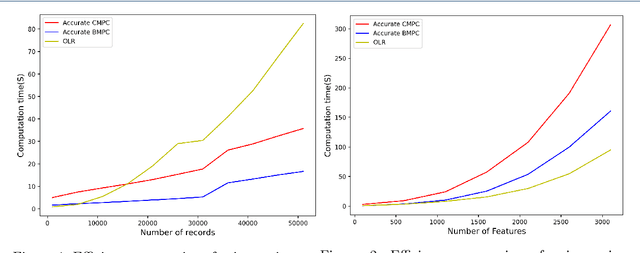
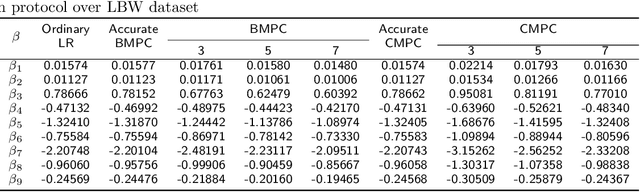
Logistic regression (LR) is a widely used classification method for modeling binary outcomes in many medical data classification tasks. Research that collects and combines datasets from various data custodians and jurisdictions can excessively benefit from the increased statistical power to support their analyzing goals. However, combining data from these various sources creates significant privacy concerns that need to be addressed. In this paper, we proposed secret sharing-based privacy-preserving logistic regression protocols using the Newton-Raphson method. Our proposed approaches are based on secure Multi-Party Computation (MPC) with different security settings to analyze data owned by several data holders. We conducted experiments on both synthetic data and real-world datasets and compared the efficiency and accuracy of them with those of an ordinary logistic regression model. Experimental results demonstrate that the proposed protocols are highly efficient and accurate. This study introduces iterative algorithms to simplify the federated training a logistic regression model in a privacy-preserving manner. Our implementation results show that our improved method can handle large datasets used in securely training a logistic regression from multiple sources.