 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving, Dropout-Resilient Aggregation in Decentralized Learning
Paper and Code
Apr 27, 2024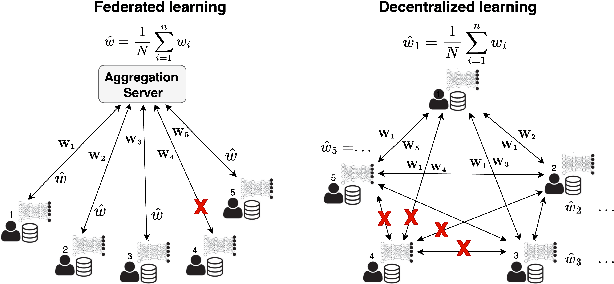
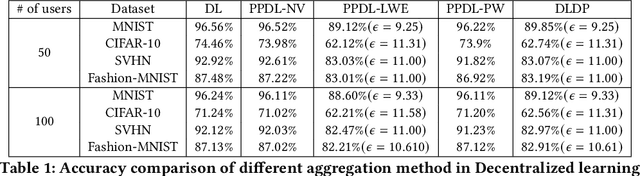


Decentralized learning (DL) offers a novel paradigm in machine learning by distributing training across clients without central aggregation, enhancing scalability and efficiency. However, DL's peer-to-peer model raises challenges in protecting against inference attacks and privacy leaks. By forgoing central bottlenecks, DL demands privacy-preserving aggregation methods to protect data from 'honest but curious' clients and adversaries, maintaining network-wide privacy. Privacy-preserving DL faces the additional hurdle of client dropout, clients not submitting updates due to connectivity problems or unavailability, further complicating aggregation. This work proposes three secret sharing-based dropout resilience approaches for privacy-preserving DL. Our study evaluates the efficiency, performance, and accuracy of these protocols through experiments on datasets such as MNIST, Fashion-MNIST, SVHN, and CIFAR-10. We compare our protocols with traditional secret-sharing solutions across scenarios, including those with up to 1000 clients. Evaluations show that our protocols significantly outperform conventional methods, especially in scenarios with up to 30% of clients dropout and model sizes of up to $10^6$ parameters. Our approaches demonstrate markedly high efficiency with larger models, higher dropout rates, and extensive client networks, highlighting their effectiveness in enhancing decentralized learning systems' privacy and dropout robustness.