 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerde: Verification via Refereed Delegation for Machine Learning Programs
Feb 26, 2025Machine learning programs, such as those performing inference, fine-tuning, and training of LLMs, are commonly delegated to untrusted compute providers. To provide correctness guarantees for the client, we propose adapting the cryptographic notion of refereed delegation to the machine learning setting. This approach enables a computationally limited client to delegate a program to multiple untrusted compute providers, with a guarantee of obtaining the correct result if at least one of them is honest. Refereed delegation of ML programs poses two technical hurdles: (1) an arbitration protocol to resolve disputes when compute providers disagree on the output, and (2) the ability to bitwise reproduce ML programs across different hardware setups, For (1), we design Verde, a dispute arbitration protocol that efficiently handles the large scale and graph-based computational model of modern ML programs. For (2), we build RepOps (Reproducible Operators), a library that eliminates hardware "non-determinism" by controlling the order of floating point operations performed on all hardware. Our implementation shows that refereed delegation achieves both strong guarantees for clients and practical overheads for compute providers.
Privacy-Preserving Aggregation for Decentralized Learning with Byzantine-Robustness
Apr 27, 2024Decentralized machine learning (DL) has been receiving an increasing interest recently due to the elimination of a single point of failure, present in Federated learning setting. Yet, it is threatened by the looming threat of Byzantine clients who intentionally disrupt the learning process by broadcasting arbitrary model updates to other clients, seeking to degrade the performance of the global model. In response, robust aggregation schemes have emerged as promising solutions to defend against such Byzantine clients, thereby enhancing the robustness of Decentralized Learning. Defenses against Byzantine adversaries, however, typically require access to the updates of other clients, a counterproductive privacy trade-off that in turn increases the risk of inference attacks on those same model updates. In this paper, we introduce SecureDL, a novel DL protocol designed to enhance the security and privacy of DL against Byzantine threats. SecureDL~facilitates a collaborative defense, while protecting the privacy of clients' model updates through secure multiparty computation. The protocol employs efficient computation of cosine similarity and normalization of updates to robustly detect and exclude model updates detrimental to model convergence. By using MNIST, Fashion-MNIST, SVHN and CIFAR-10 datasets, we evaluated SecureDL against various Byzantine attacks and compared its effectiveness with four existing defense mechanisms. Our experiments show that SecureDL is effective even in the case of attacks by the malicious majority (e.g., 80% Byzantine clients) while preserving high training accuracy.
On Feasibility of Server-side Backdoor Attacks on Split Learning
Feb 19, 2023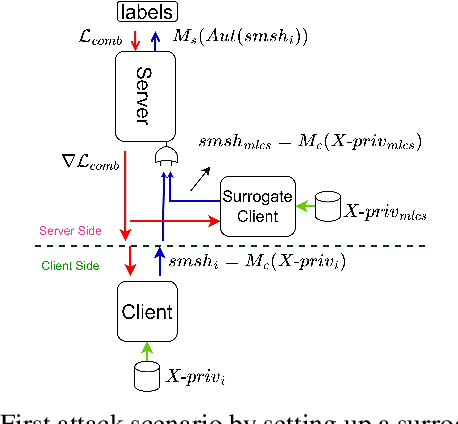
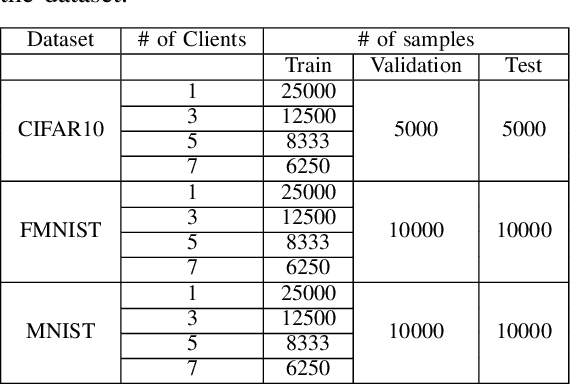
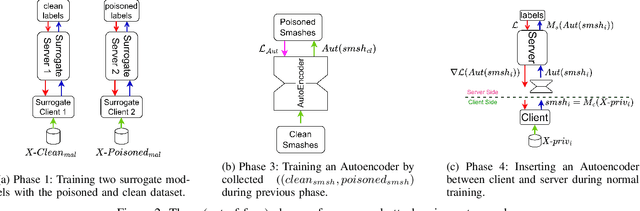
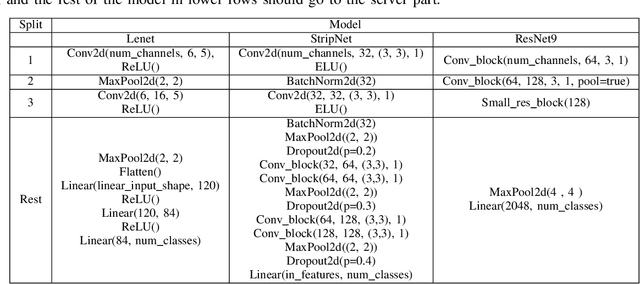
Split learning is a collaborative learning design that allows several participants (clients) to train a shared model while keeping their datasets private. Recent studies demonstrate that collaborative learning models, specifically federated learning, are vulnerable to security and privacy attacks such as model inference and backdoor attacks. Backdoor attacks are a group of poisoning attacks in which the attacker tries to control the model output by manipulating the model's training process. While there have been studies regarding inference attacks on split learning, it has not yet been tested for backdoor attacks. This paper performs a novel backdoor attack on split learning and studies its effectiveness. Despite traditional backdoor attacks done on the client side, we inject the backdoor trigger from the server side. For this purpose, we provide two attack methods: one using a surrogate client and another using an autoencoder to poison the model via incoming smashed data and its outgoing gradient toward the innocent participants. We did our experiments using three model architectures and three publicly available datasets in the image domain and ran a total of 761 experiments to evaluate our attack methods. The results show that despite using strong patterns and injection methods, split learning is highly robust and resistant to such poisoning attacks. While we get the attack success rate of 100% as our best result for the MNIST dataset, in most of the other cases, our attack shows little success when increasing the cut layer.
Sneaky Spikes: Uncovering Stealthy Backdoor Attacks in Spiking Neural Networks with Neuromorphic Data
Feb 13, 2023



Deep neural networks (DNNs) have achieved excellent results in various tasks, including image and speech recognition. However, optimizing the performance of DNNs requires careful tuning of multiple hyperparameters and network parameters via training. High-performance DNNs utilize a large number of parameters, corresponding to high energy consumption during training. To address these limitations, researchers have developed spiking neural networks (SNNs), which are more energy-efficient and can process data in a biologically plausible manner, making them well-suited for tasks involving sensory data processing, i.e., neuromorphic data. Like DNNs, SNNs are vulnerable to various threats, such as adversarial examples and backdoor attacks. Yet, the attacks and countermeasures for SNNs have been almost fully unexplored. This paper investigates the application of backdoor attacks in SNNs using neuromorphic datasets and different triggers. More precisely, backdoor triggers in neuromorphic data can change their position and color, allowing a larger range of possibilities than common triggers in, e.g., the image domain. We propose different attacks achieving up to 100\% attack success rate without noticeable clean accuracy degradation. We also evaluate the stealthiness of the attacks via the structural similarity metric, showing our most powerful attacks being also stealthy. Finally, we adapt the state-of-the-art defenses from the image domain, demonstrating they are not necessarily effective for neuromorphic data resulting in inaccurate performance.
Universal Soldier: Using Universal Adversarial Perturbations for Detecting Backdoor Attacks
Feb 07, 2023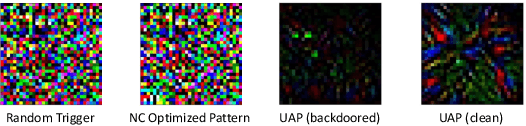
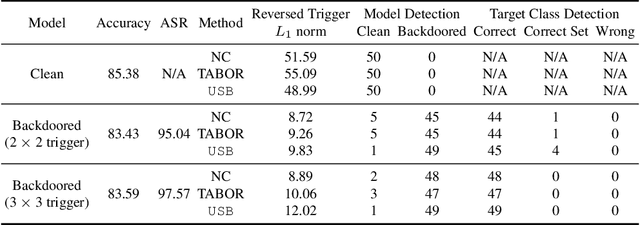

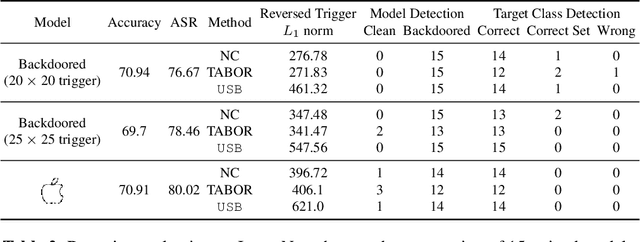
Deep learning models achieve excellent performance in numerous machine learning tasks. Yet, they suffer from security-related issues such as adversarial examples and poisoning (backdoor) attacks. A deep learning model may be poisoned by training with backdoored data or by modifying inner network parameters. Then, a backdoored model performs as expected when receiving a clean input, but it misclassifies when receiving a backdoored input stamped with a pre-designed pattern called "trigger". Unfortunately, it is difficult to distinguish between clean and backdoored models without prior knowledge of the trigger. This paper proposes a backdoor detection method by utilizing a special type of adversarial attack, universal adversarial perturbation (UAP), and its similarities with a backdoor trigger. We observe an intuitive phenomenon: UAPs generated from backdoored models need fewer perturbations to mislead the model than UAPs from clean models. UAPs of backdoored models tend to exploit the shortcut from all classes to the target class, built by the backdoor trigger. We propose a novel method called Universal Soldier for Backdoor detection (USB) and reverse engineering potential backdoor triggers via UAPs. Experiments on 345 models trained on several datasets show that USB effectively detects the injected backdoor and provides comparable or better results than state-of-the-art methods.