 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Feasibility of Server-side Backdoor Attacks on Split Learning
Paper and Code
Feb 19, 2023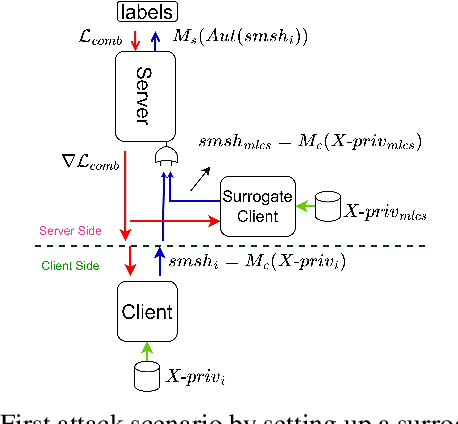
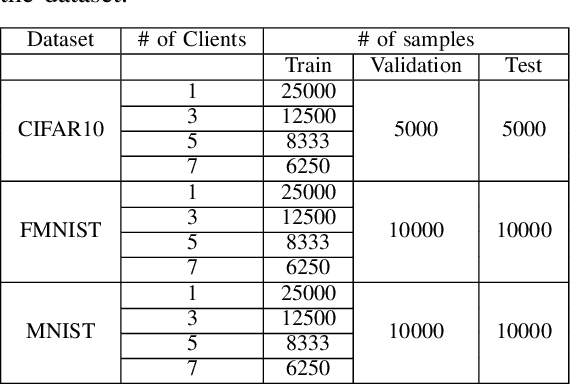
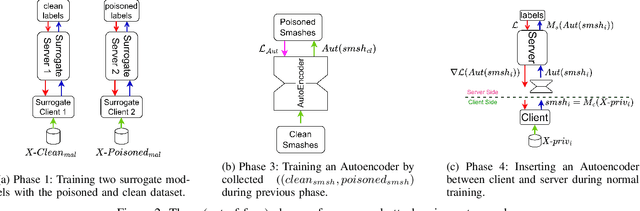
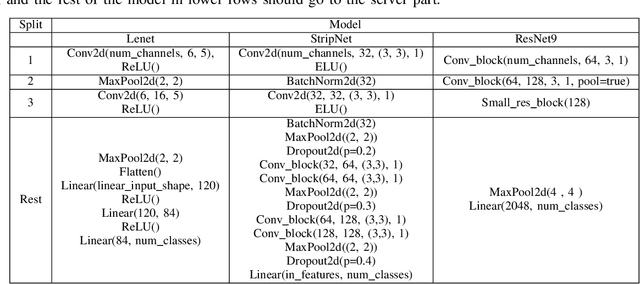
Split learning is a collaborative learning design that allows several participants (clients) to train a shared model while keeping their datasets private. Recent studies demonstrate that collaborative learning models, specifically federated learning, are vulnerable to security and privacy attacks such as model inference and backdoor attacks. Backdoor attacks are a group of poisoning attacks in which the attacker tries to control the model output by manipulating the model's training process. While there have been studies regarding inference attacks on split learning, it has not yet been tested for backdoor attacks. This paper performs a novel backdoor attack on split learning and studies its effectiveness. Despite traditional backdoor attacks done on the client side, we inject the backdoor trigger from the server side. For this purpose, we provide two attack methods: one using a surrogate client and another using an autoencoder to poison the model via incoming smashed data and its outgoing gradient toward the innocent participants. We did our experiments using three model architectures and three publicly available datasets in the image domain and ran a total of 761 experiments to evaluate our attack methods. The results show that despite using strong patterns and injection methods, split learning is highly robust and resistant to such poisoning attacks. While we get the attack success rate of 100% as our best result for the MNIST dataset, in most of the other cases, our attack shows little success when increasing the cut layer.