 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: The Last Line of Defense: On Backdoor Defense Evaluation
Nov 17, 2025Backdoor attacks pose a significant threat to deep learning models by implanting hidden vulnerabilities that can be activated by malicious inputs. While numerous defenses have been proposed to mitigate these attacks, the heterogeneous landscape of evaluation methodologies hinders fair comparison between defenses. This work presents a systematic (meta-)analysis of backdoor defenses through a comprehensive literature review and empirical evaluation. We analyzed 183 backdoor defense papers published between 2018 and 2025 across major AI and security venues, examining the properties and evaluation methodologies of these defenses. Our analysis reveals significant inconsistencies in experimental setups, evaluation metrics, and threat model assumptions in the literature. Through extensive experiments involving three datasets (MNIST, CIFAR-100, ImageNet-1K), four model architectures (ResNet-18, VGG-19, ViT-B/16, DenseNet-121), 16 representative defenses, and five commonly used attacks, totaling over 3\,000 experiments, we demonstrate that defense effectiveness varies substantially across different evaluation setups. We identify critical gaps in current evaluation practices, including insufficient reporting of computational overhead and behavior under benign conditions, bias in hyperparameter selection, and incomplete experimentation. Based on our findings, we provide concrete challenges and well-motivated recommendations to standardize and improve future defense evaluations. Our work aims to equip researchers and industry practitioners with actionable insights for developing, assessing, and deploying defenses to different systems.
CatBack: Universal Backdoor Attacks on Tabular Data via Categorical Encoding
Nov 08, 2025Backdoor attacks in machine learning have drawn significant attention for their potential to compromise models stealthily, yet most research has focused on homogeneous data such as images. In this work, we propose a novel backdoor attack on tabular data, which is particularly challenging due to the presence of both numerical and categorical features. Our key idea is a novel technique to convert categorical values into floating-point representations. This approach preserves enough information to maintain clean-model accuracy compared to traditional methods like one-hot or ordinal encoding. By doing this, we create a gradient-based universal perturbation that applies to all features, including categorical ones. We evaluate our method on five datasets and four popular models. Our results show up to a 100% attack success rate in both white-box and black-box settings (including real-world applications like Vertex AI), revealing a severe vulnerability for tabular data. Our method is shown to surpass the previous works like Tabdoor in terms of performance, while remaining stealthy against state-of-the-art defense mechanisms. We evaluate our attack against Spectral Signatures, Neural Cleanse, Beatrix, and Fine-Pruning, all of which fail to defend successfully against it. We also verify that our attack successfully bypasses popular outlier detection mechanisms.
Tabdoor: Backdoor Vulnerabilities in Transformer-based Neural Networks for Tabular Data
Nov 13, 2023Deep neural networks (DNNs) have shown great promise in various domains. Alongside these developments, vulnerabilities associated with DNN training, such as backdoor attacks, are a significant concern. These attacks involve the subtle insertion of triggers during model training, allowing for manipulated predictions. More recently, DNNs for tabular data have gained increasing attention due to the rise of transformer models. Our research presents a comprehensive analysis of backdoor attacks on tabular data using DNNs, particularly focusing on transformer-based networks. Given the inherent complexities of tabular data, we explore the challenges of embedding backdoors. Through systematic experimentation across benchmark datasets, we uncover that transformer-based DNNs for tabular data are highly susceptible to backdoor attacks, even with minimal feature value alterations. Our results indicate nearly perfect attack success rates (approx100%) by introducing novel backdoor attack strategies to tabular data. Furthermore, we evaluate several defenses against these attacks, identifying Spectral Signatures as the most effective one. Our findings highlight the urgency to address such vulnerabilities and provide insights into potential countermeasures for securing DNN models against backdoors on tabular data.
On Feasibility of Server-side Backdoor Attacks on Split Learning
Feb 19, 2023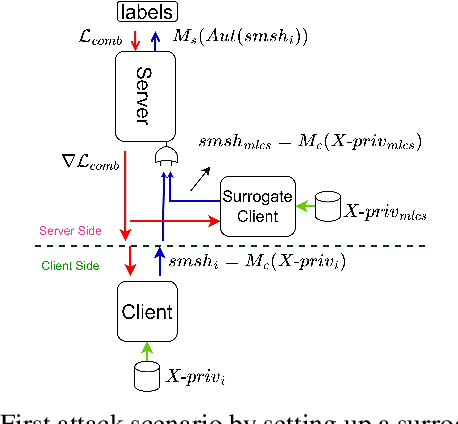
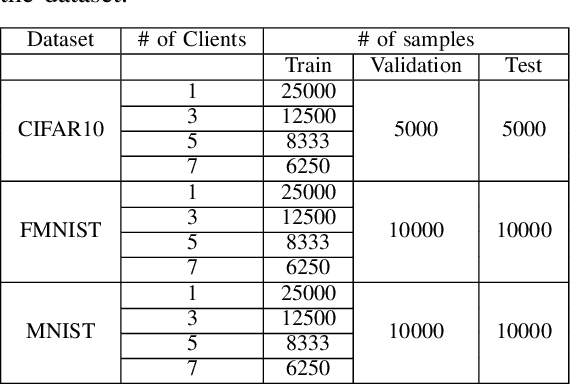
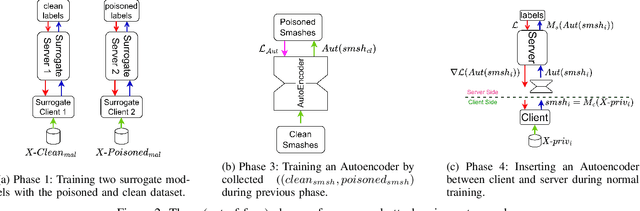
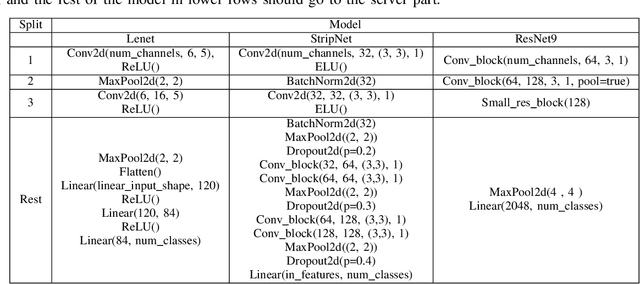
Split learning is a collaborative learning design that allows several participants (clients) to train a shared model while keeping their datasets private. Recent studies demonstrate that collaborative learning models, specifically federated learning, are vulnerable to security and privacy attacks such as model inference and backdoor attacks. Backdoor attacks are a group of poisoning attacks in which the attacker tries to control the model output by manipulating the model's training process. While there have been studies regarding inference attacks on split learning, it has not yet been tested for backdoor attacks. This paper performs a novel backdoor attack on split learning and studies its effectiveness. Despite traditional backdoor attacks done on the client side, we inject the backdoor trigger from the server side. For this purpose, we provide two attack methods: one using a surrogate client and another using an autoencoder to poison the model via incoming smashed data and its outgoing gradient toward the innocent participants. We did our experiments using three model architectures and three publicly available datasets in the image domain and ran a total of 761 experiments to evaluate our attack methods. The results show that despite using strong patterns and injection methods, split learning is highly robust and resistant to such poisoning attacks. While we get the attack success rate of 100% as our best result for the MNIST dataset, in most of the other cases, our attack shows little success when increasing the cut layer.
A Systematic Evaluation of Backdoor Trigger Characteristics in Image Classification
Feb 03, 2023



Deep learning achieves outstanding results in many machine learning tasks. Nevertheless, it is vulnerable to backdoor attacks that modify the training set to embed a secret functionality in the trained model. The modified training samples have a secret property, i.e., a trigger. At inference time, the secret functionality is activated when the input contains the trigger, while the model functions correctly in other cases. While there are many known backdoor attacks (and defenses), deploying a stealthy attack is still far from trivial. Successfully creating backdoor triggers heavily depends on numerous parameters. Unfortunately, research has not yet determined which parameters contribute most to the attack performance. This paper systematically analyzes the most relevant parameters for the backdoor attacks, i.e., trigger size, position, color, and poisoning rate. Using transfer learning, which is very common in computer vision, we evaluate the attack on numerous state-of-the-art models (ResNet, VGG, AlexNet, and GoogLeNet) and datasets (MNIST, CIFAR10, and TinyImageNet). Our attacks cover the majority of backdoor settings in research, providing concrete directions for future works. Our code is publicly available to facilitate the reproducibility of our results.