 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalking to Extraordinary Objects: Folktales Offer Analogies for Interacting with Technology
Jan 10, 2026Speech and language are valuable for interacting with technology. It would be ideal to be able to decouple their use from anthropomorphization, which has recently met an important moment of reckoning. In the world of folktales, language is everywhere and talking to extraordinary objects is not unusual. This overview presents examples of the analogies that folktales offer. Extraordinary objects in folktales are diverse and also memorable. Language capacity and intelligence are not always connected to humanness. Consideration of folktales can offer inspiration and insight for using speech and language for interacting with technology.
Evaluating the Usefulness of Non-Diagnostic Speech Data for Developing Parkinson's Disease Classifiers
May 24, 2025



Speech-based Parkinson's disease (PD) detection has gained attention for its automated, cost-effective, and non-intrusive nature. As research studies usually rely on data from diagnostic-oriented speech tasks, this work explores the feasibility of diagnosing PD on the basis of speech data not originally intended for diagnostic purposes, using the Turn-Taking (TT) dataset. Our findings indicate that TT can be as useful as diagnostic-oriented PD datasets like PC-GITA. We also investigate which specific dataset characteristics impact PD classification performance. The results show that concatenating audio recordings and balancing participants' gender and status distributions can be beneficial. Cross-dataset evaluation reveals that models trained on PC-GITA generalize poorly to TT, whereas models trained on TT perform better on PC-GITA. Furthermore, we provide insights into the high variability across folds, which is mainly due to large differences in individual speaker performance.
On Fact and Frequency: LLM Responses to Misinformation Expressed with Uncertainty
Mar 06, 2025We study LLM judgments of misinformation expressed with uncertainty. Our experiments study the response of three widely used LLMs (GPT-4o, LlaMA3, DeepSeek-v2) to misinformation propositions that have been verified false and then are transformed into uncertain statements according to an uncertainty typology. Our results show that after transformation, LLMs change their factchecking classification from false to not-false in 25% of the cases. Analysis reveals that the change cannot be explained by predictors to which humans are expected to be sensitive, i.e., modality, linguistic cues, or argumentation strategy. The exception is doxastic transformations, which use linguistic cue phrases such as "It is believed ...".To gain further insight, we prompt the LLM to make another judgment about the transformed misinformation statements that is not related to truth value. Specifically, we study LLM estimates of the frequency with which people make the uncertain statement. We find a small but significant correlation between judgment of fact and estimation of frequency.
Frequency Is What You Need: Word-frequency Masking Benefits Vision-Language Model Pre-training
Dec 20, 2024Vision Language Models (VLMs) can be trained more efficiently if training sets can be reduced in size. Recent work has shown the benefits of masking text during VLM training using a variety of approaches: truncation, random masking, block masking and syntax masking. In this paper, we show that the best masking strategy changes over training epochs and that, given sufficient training epochs, word frequency information is what you need to achieve the best performance. Experiments on a large range of data sets demonstrate the advantages of our approach, called Contrastive Language-Image Pre-training with word Frequency Masking (CLIPF). The benefits are particularly evident as the number of input tokens decreases. We analyze the impact of CLIPF vs. other masking approaches on word frequency balance and discuss the apparently critical contribution of CLIPF in maintaining word frequency balance across POS categories.
Enhancing Vision-Language Model Pre-training with Image-text Pair Pruning Based on Word Frequency
Oct 09, 2024We propose Word-Frequency-based Image-Text Pair Pruning (WFPP), a novel data pruning method that improves the efficiency of VLMs. Unlike MetaCLIP, our method does not need metadata for pruning, but selects text-image pairs to prune based on the content of the text. Specifically, WFPP prunes text-image pairs containing high-frequency words across the entire training dataset. The effect of WFPP is to reduce the dominance of frequent words. The result a better balanced word-frequency distribution in the dataset, which is known to improve the training of word embedding models. After pre-training on the pruned subset, we fine-tuned the model on the entire dataset for one additional epoch to achieve better performance. Our experiments demonstrate that applying WFPP when training a CLIP model improves performance on a wide range of downstream tasks. WFPP also provides the advantage of speeding up pre-training by using fewer samples. Additionally, we analyze the training data before and after pruning to visualize how WFPP changes the balance of word frequencies. We hope our work encourages researchers to consider the distribution of words in the training data when pre-training VLMs, not limited to CLIP.
Scenario of Use Scheme: Threat Model Specification for Speaker Privacy Protection in the Medical Domain
Sep 26, 2024



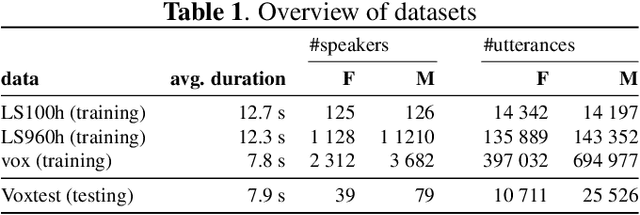
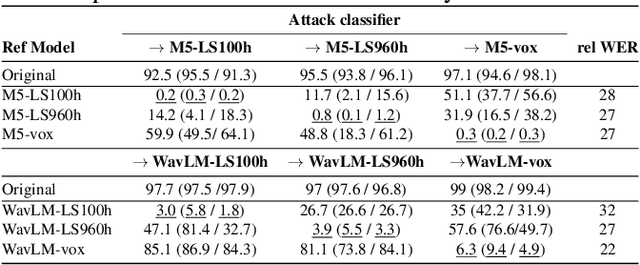
Speech recordings are being more frequently used to detect and monitor disease, leading to privacy concerns. Beyond cryptography, protection of speech can be addressed by approaches, such as perturbation, disentanglement, and re-synthesis, that eliminate sensitive information of the speaker, leaving the information necessary for medical analysis purposes. In order for such privacy protective approaches to be developed, clear and systematic specifications of assumptions concerning medical settings and the needs of medical professionals are necessary. In this paper, we propose a Scenario of Use Scheme that incorporates an Attacker Model, which characterizes the adversary against whom the speaker's privacy must be defended, and a Protector Model, which specifies the defense. We discuss the connection of the scheme with previous work on speech privacy. Finally, we present a concrete example of a specified Scenario of Use and a set of experiments about protecting speaker data against gender inference attacks while maintaining utility for Parkinson's detection.
Centered Masking for Language-Image Pre-Training
Mar 27, 2024We introduce Gaussian masking for Language-Image Pre-Training (GLIP) a novel, straightforward, and effective technique for masking image patches during pre-training of a vision-language model. GLIP builds on Fast Language-Image Pre-Training (FLIP), which randomly masks image patches while training a CLIP model. GLIP replaces random masking with centered masking, that uses a Gaussian distribution and is inspired by the importance of image patches at the center of the image. GLIP retains the same computational savings as FLIP, while improving performance across a range of downstream datasets and tasks, as demonstrated by our experimental results. We show the benefits of GLIP to be easy to obtain, requiring no delicate tuning of the Gaussian, and also applicable to data sets containing images without an obvious center focus.
Tabdoor: Backdoor Vulnerabilities in Transformer-based Neural Networks for Tabular Data
Nov 13, 2023Deep neural networks (DNNs) have shown great promise in various domains. Alongside these developments, vulnerabilities associated with DNN training, such as backdoor attacks, are a significant concern. These attacks involve the subtle insertion of triggers during model training, allowing for manipulated predictions. More recently, DNNs for tabular data have gained increasing attention due to the rise of transformer models. Our research presents a comprehensive analysis of backdoor attacks on tabular data using DNNs, particularly focusing on transformer-based networks. Given the inherent complexities of tabular data, we explore the challenges of embedding backdoors. Through systematic experimentation across benchmark datasets, we uncover that transformer-based DNNs for tabular data are highly susceptible to backdoor attacks, even with minimal feature value alterations. Our results indicate nearly perfect attack success rates (approx100%) by introducing novel backdoor attack strategies to tabular data. Furthermore, we evaluate several defenses against these attacks, identifying Spectral Signatures as the most effective one. Our findings highlight the urgency to address such vulnerabilities and provide insights into potential countermeasures for securing DNN models against backdoors on tabular data.
When Machine Learning Models Leak: An Exploration of Synthetic Training Data
Oct 12, 2023We investigate an attack on a machine learning model that predicts whether a person or household will relocate in the next two years, i.e., a propensity-to-move classifier. The attack assumes that the attacker can query the model to obtain predictions and that the marginal distribution of the data on which the model was trained is publicly available. The attack also assumes that the attacker has obtained the values of non-sensitive attributes for a certain number of target individuals. The objective of the attack is to infer the values of sensitive attributes for these target individuals. We explore how replacing the original data with synthetic data when training the model impacts how successfully the attacker can infer sensitive attributes.\footnote{Original paper published at PSD 2022. The paper was subsequently updated.}
Beyond Neural-on-Neural Approaches to Speaker Gender Protection
Jun 30, 2023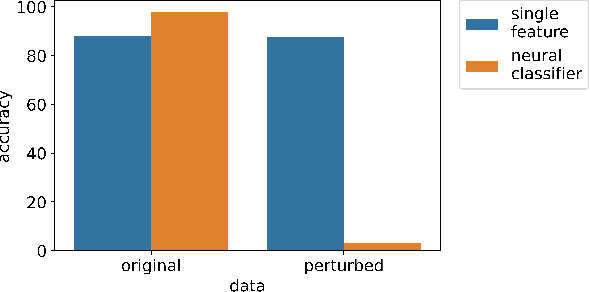

Recent research has proposed approaches that modify speech to defend against gender inference attacks. The goal of these protection algorithms is to control the availability of information about a speaker's gender, a privacy-sensitive attribute. Currently, the common practice for developing and testing gender protection algorithms is "neural-on-neural", i.e., perturbations are generated and tested with a neural network. In this paper, we propose to go beyond this practice to strengthen the study of gender protection. First, we demonstrate the importance of testing gender inference attacks that are based on speech features historically developed by speech scientists, alongside the conventionally used neural classifiers. Next, we argue that researchers should use speech features to gain insight into how protective modifications change the speech signal. Finally, we point out that gender-protection algorithms should be compared with novel "vocal adversaries", human-executed voice adaptations, in order to improve interpretability and enable before-the-mic protection.