 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Batch Size on Contrastive Self-Supervised Speech Representation Learning
Feb 21, 2024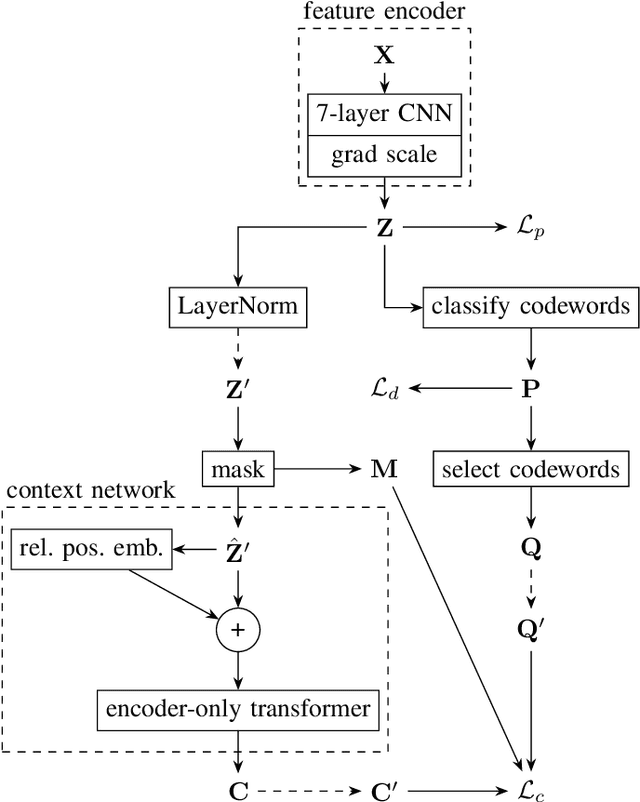
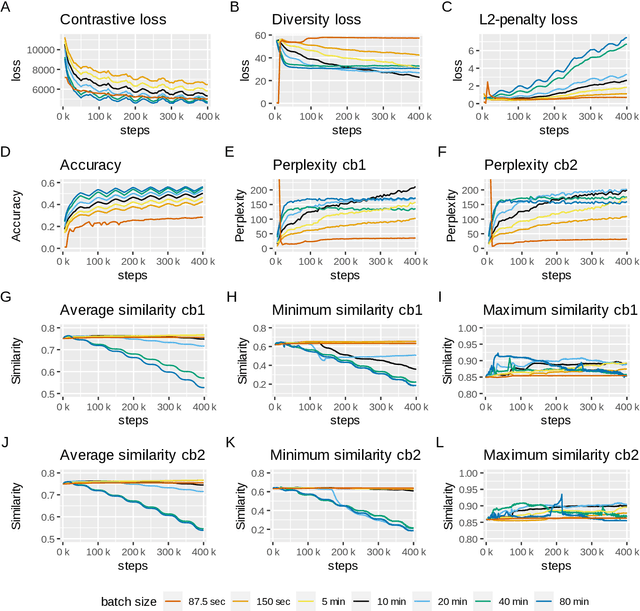
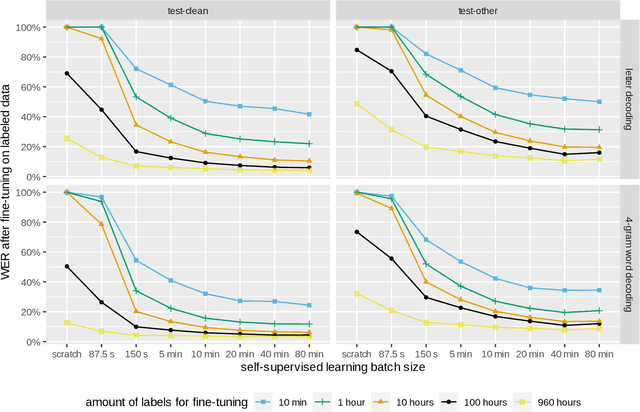
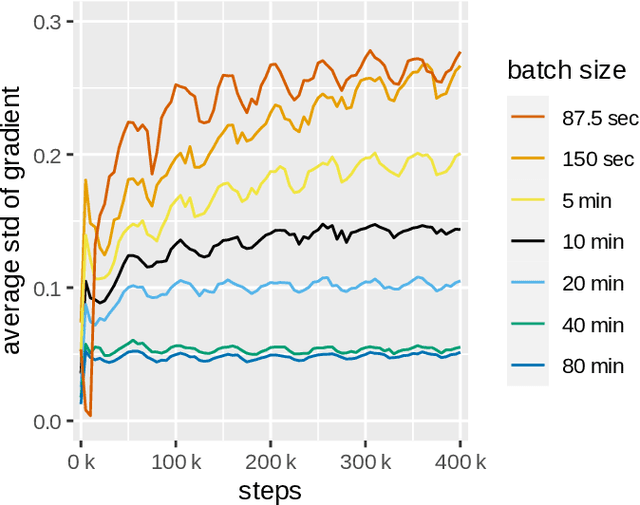
Foundation models in speech are often trained using many GPUs, which implicitly leads to large effective batch sizes. In this paper we study the effect of batch size on pre-training, both in terms of statistics that can be monitored during training, and in the effect on the performance of a downstream fine-tuning task. By using batch sizes varying from 87.5 seconds to 80 minutes of speech we show that, for a fixed amount of iterations, larger batch sizes result in better pre-trained models. However, there is lower limit for stability, and an upper limit for effectiveness. We then show that the quality of the pre-trained model depends mainly on the amount of speech data seen during training, i.e., on the product of batch size and number of iterations. All results are produced with an independent implementation of the wav2vec 2.0 architecture, which to a large extent reproduces the results of the original work (arXiv:2006.11477). Our extensions can help researchers choose effective operating conditions when studying self-supervised learning in speech, and hints towards benchmarking self-supervision with a fixed amount of seen data. Code and model checkpoints are available at https://github.com/nikvaessen/w2v2-batch-size.
Beyond Neural-on-Neural Approaches to Speaker Gender Protection
Jun 30, 2023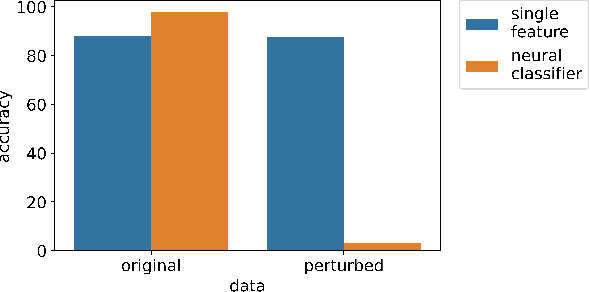

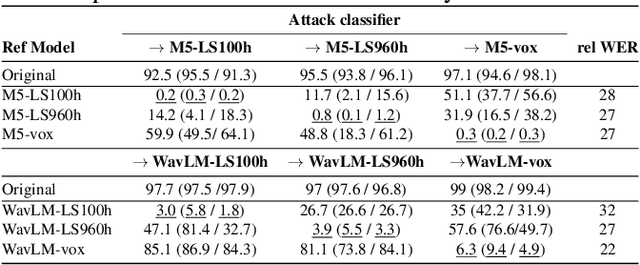
Recent research has proposed approaches that modify speech to defend against gender inference attacks. The goal of these protection algorithms is to control the availability of information about a speaker's gender, a privacy-sensitive attribute. Currently, the common practice for developing and testing gender protection algorithms is "neural-on-neural", i.e., perturbations are generated and tested with a neural network. In this paper, we propose to go beyond this practice to strengthen the study of gender protection. First, we demonstrate the importance of testing gender inference attacks that are based on speech features historically developed by speech scientists, alongside the conventionally used neural classifiers. Next, we argue that researchers should use speech features to gain insight into how protective modifications change the speech signal. Finally, we point out that gender-protection algorithms should be compared with novel "vocal adversaries", human-executed voice adaptations, in order to improve interpretability and enable before-the-mic protection.
Multi-task learning of speech and speaker recognition
Feb 24, 2023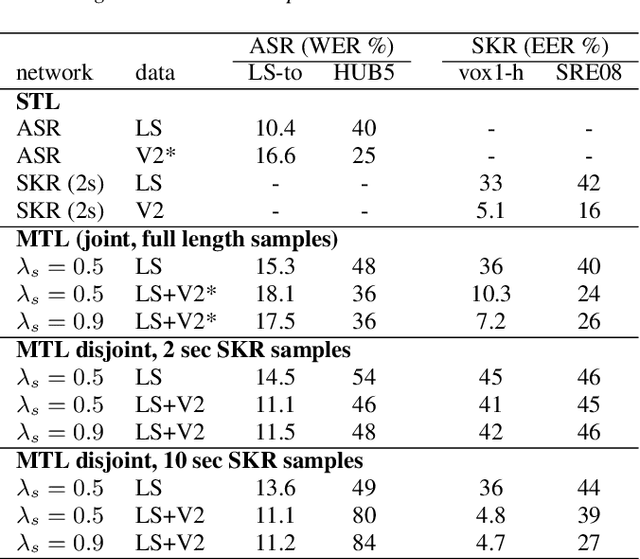
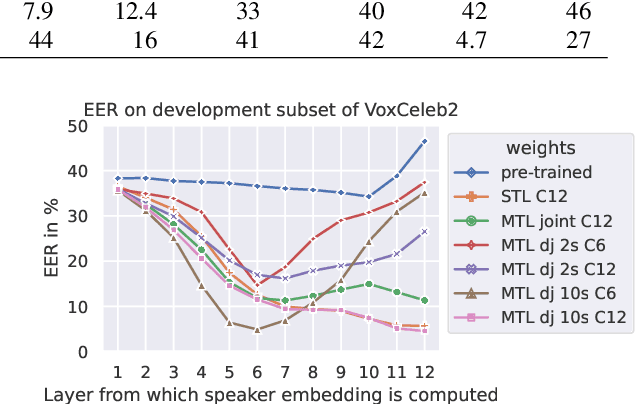
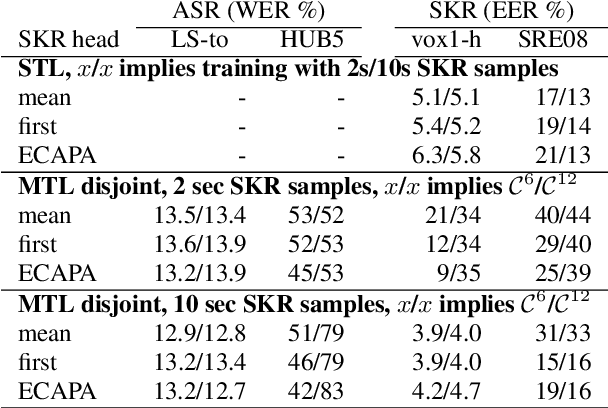

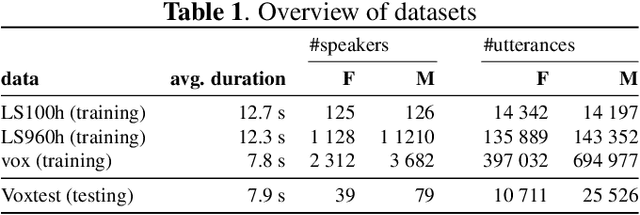
We study multi-task learning for two orthogonal speech technology tasks: speech and speaker recognition. We use wav2vec2 as a base architecture with two task-specific output heads. We experiment with different methods to mix speaker and speech information in the output embedding sequence, and propose a simple dynamic approach to balance the speech and speaker recognition loss functions. Our multi-task learning networks can produce a shared speaker and speech embedding, which are evaluated on the LibriSpeech and VoxCeleb test sets, and achieve a performance comparable to separate single-task models. Code is available at https://github.com/nikvaessen/2022-repo-mt-w2v2.
Speaker and Language Change Detection using Wav2vec2 and Whisper
Feb 18, 2023We investigate recent transformer networks pre-trained for automatic speech recognition for their ability to detect speaker and language changes in speech. We do this by simply adding speaker (change) or language targets to the labels. For Wav2vec2 pre-trained networks, we also investigate if the representation for the speaker change symbol can be conditioned to capture speaker identity characteristics. Using a number of constructed data sets we show that these capabilities are definitely there, with speaker recognition equal error rates of the order of 10% and language detection error rates of a few percent. We will publish the code for reproducibility.
Training speaker recognition systems with limited data
Mar 28, 2022
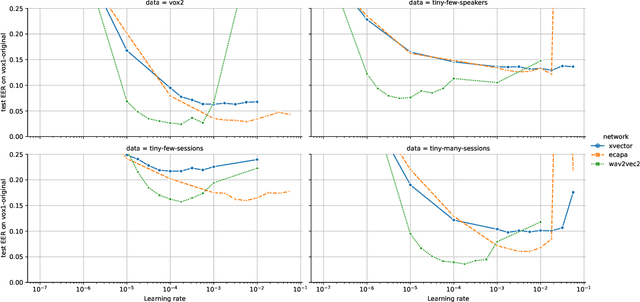
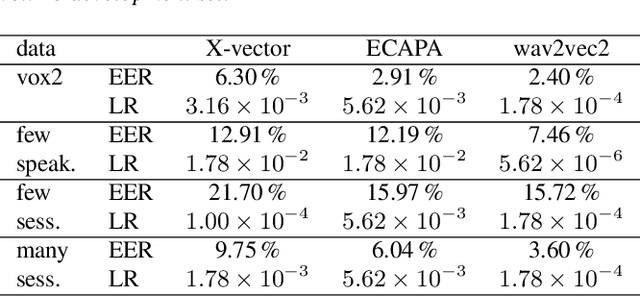
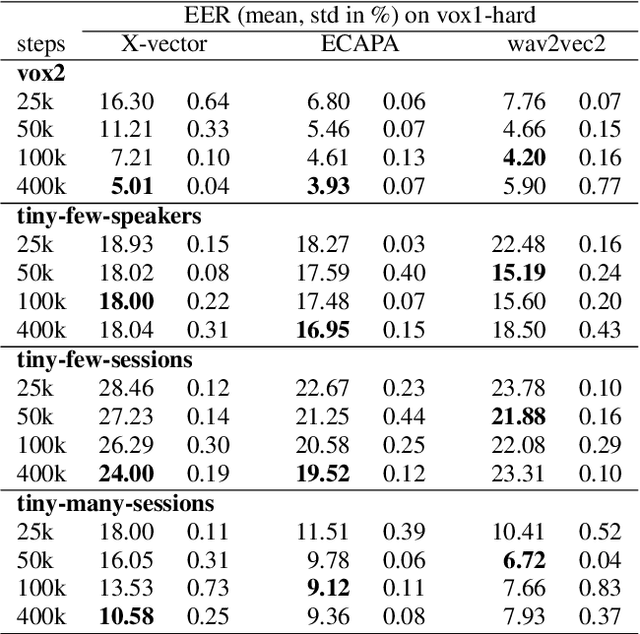
This work considers training neural networks for speaker recognition with a much smaller dataset size compared to contemporary work. We artificially restrict the amount of data by proposing three subsets of the popular VoxCeleb2 dataset. These subsets are restricted to 50 k audio files (versus over 1 M files available), and vary on the axis of number of speakers and session variability. We train three speaker recognition systems on these subsets; the X-vector, ECAPA-TDNN, and wav2vec2 network architectures. We show that the self-supervised, pre-trained weights of wav2vec2 substantially improve performance when training data is limited. Code and data subsets are available at \url{https://github.com/nikvaessen/w2v2-speaker-few-samples}.
Fine-tuning wav2vec2 for speaker recognition
Sep 30, 2021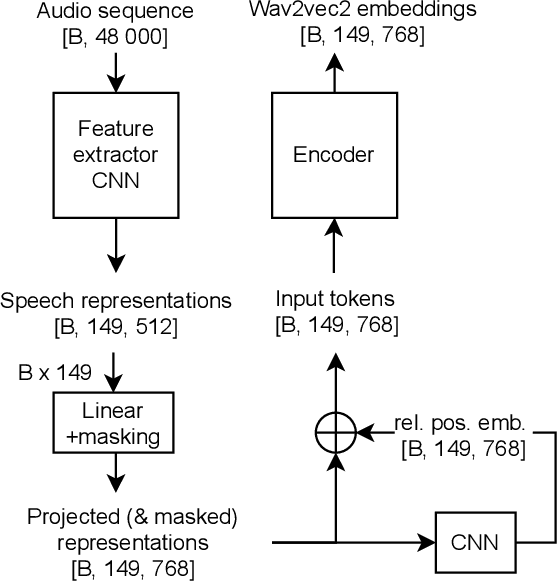
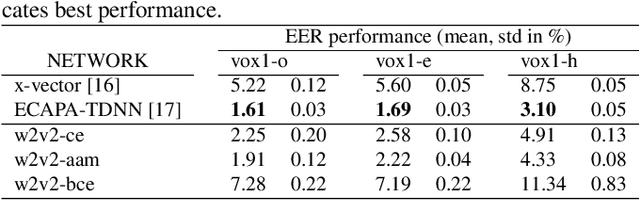
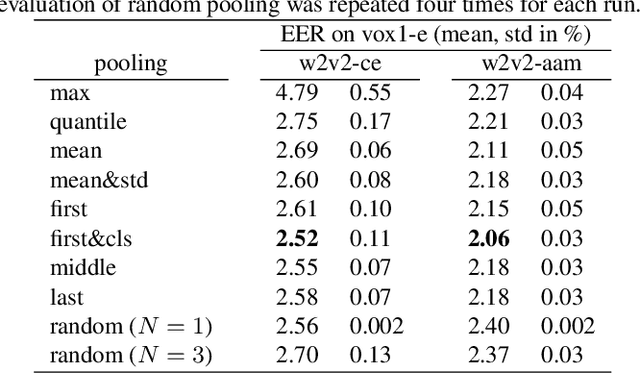
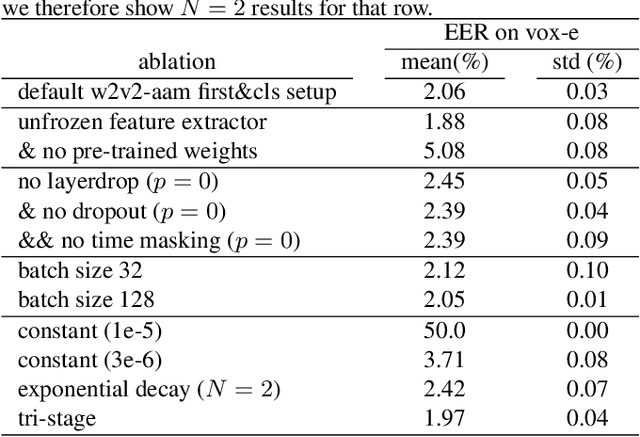
This paper explores applying the wav2vec2 framework to speaker recognition instead of speech recognition. We study the effectiveness of the pre-trained weights on the speaker recognition task, and how to pool the wav2vec2 output sequence into a fixed-length speaker embedding. To adapt the framework to speaker recognition, we propose a single-utterance classification variant with CE or AAM softmax loss, and an utterance-pair classification variant with BCE loss. Our best performing variant, w2v2-aam, achieves a 1.88% EER on the extended voxceleb1 test set compared to 1.69% EER with an ECAPA-TDNN baseline. Code is available at https://github.com/nikvaessen/w2v2-speaker.