Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining speaker recognition systems with limited data
Paper and Code

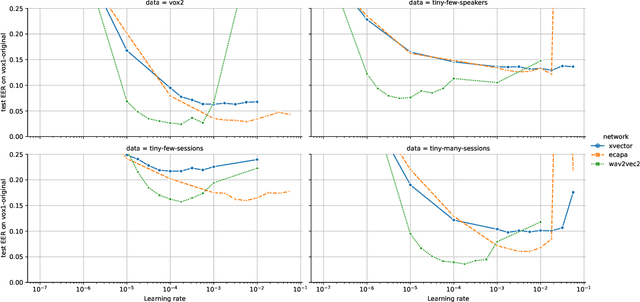
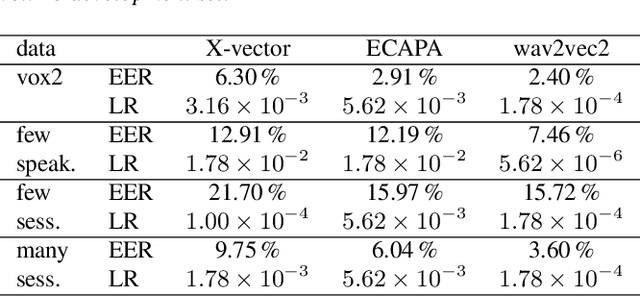
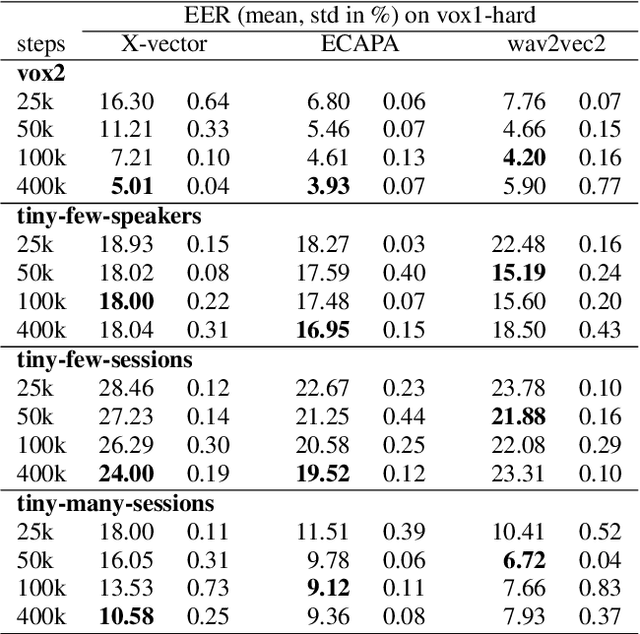
This work considers training neural networks for speaker recognition with a much smaller dataset size compared to contemporary work. We artificially restrict the amount of data by proposing three subsets of the popular VoxCeleb2 dataset. These subsets are restricted to 50 k audio files (versus over 1 M files available), and vary on the axis of number of speakers and session variability. We train three speaker recognition systems on these subsets; the X-vector, ECAPA-TDNN, and wav2vec2 network architectures. We show that the self-supervised, pre-trained weights of wav2vec2 substantially improve performance when training data is limited. Code and data subsets are available at \url{https://github.com/nikvaessen/w2v2-speaker-few-samples}.
* submitted to Interspeech 2022
View paper on