 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Batch Size on Contrastive Self-Supervised Speech Representation Learning
Feb 21, 2024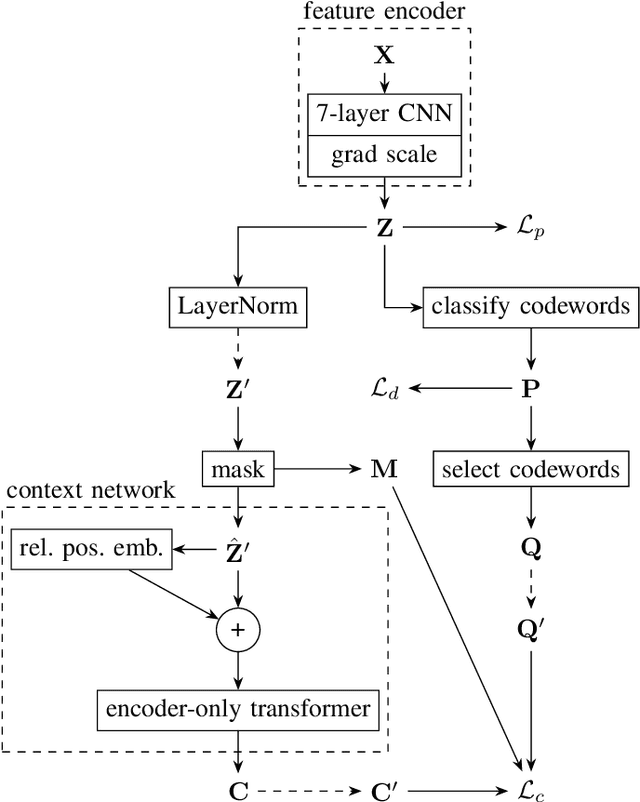
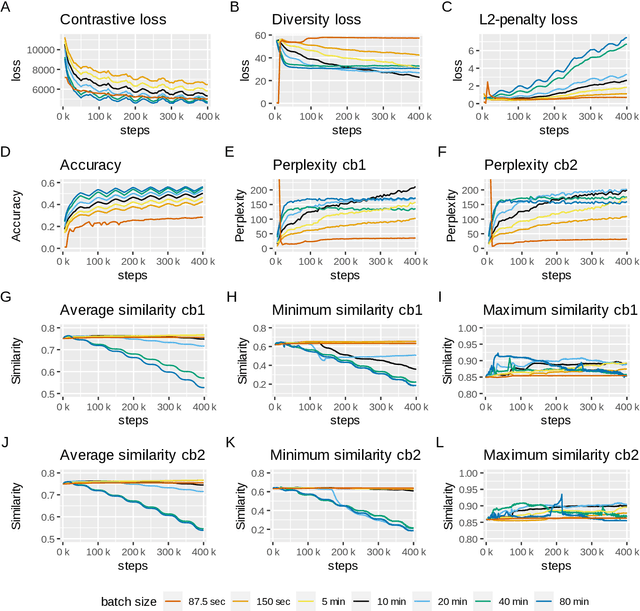
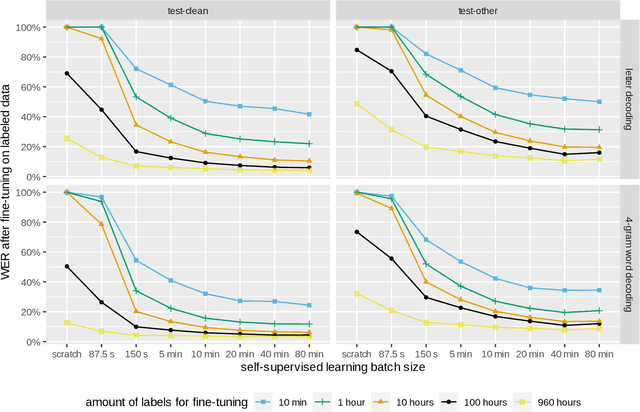
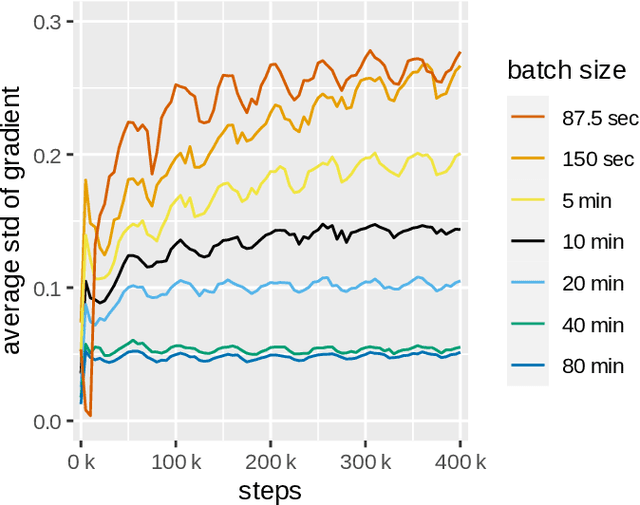
Foundation models in speech are often trained using many GPUs, which implicitly leads to large effective batch sizes. In this paper we study the effect of batch size on pre-training, both in terms of statistics that can be monitored during training, and in the effect on the performance of a downstream fine-tuning task. By using batch sizes varying from 87.5 seconds to 80 minutes of speech we show that, for a fixed amount of iterations, larger batch sizes result in better pre-trained models. However, there is lower limit for stability, and an upper limit for effectiveness. We then show that the quality of the pre-trained model depends mainly on the amount of speech data seen during training, i.e., on the product of batch size and number of iterations. All results are produced with an independent implementation of the wav2vec 2.0 architecture, which to a large extent reproduces the results of the original work (arXiv:2006.11477). Our extensions can help researchers choose effective operating conditions when studying self-supervised learning in speech, and hints towards benchmarking self-supervision with a fixed amount of seen data. Code and model checkpoints are available at https://github.com/nikvaessen/w2v2-batch-size.
Multi-task learning of speech and speaker recognition
Feb 24, 2023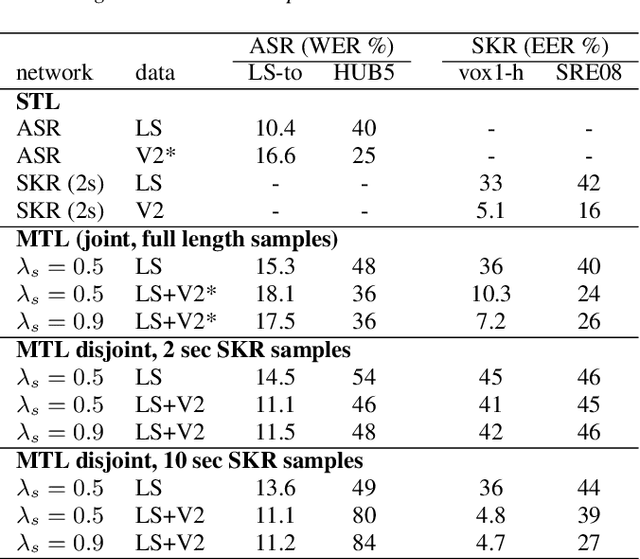
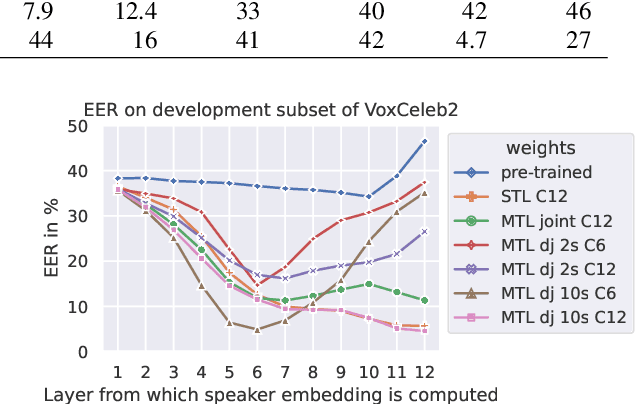
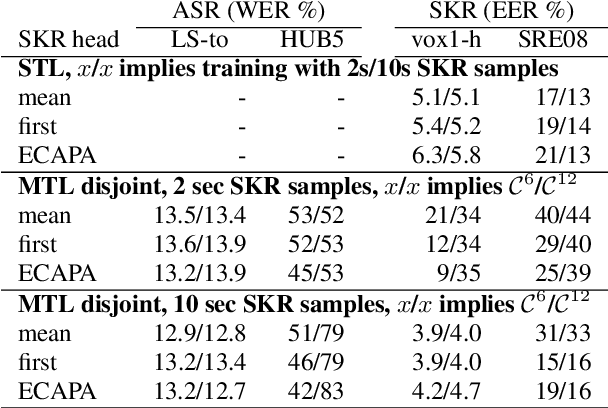

We study multi-task learning for two orthogonal speech technology tasks: speech and speaker recognition. We use wav2vec2 as a base architecture with two task-specific output heads. We experiment with different methods to mix speaker and speech information in the output embedding sequence, and propose a simple dynamic approach to balance the speech and speaker recognition loss functions. Our multi-task learning networks can produce a shared speaker and speech embedding, which are evaluated on the LibriSpeech and VoxCeleb test sets, and achieve a performance comparable to separate single-task models. Code is available at https://github.com/nikvaessen/2022-repo-mt-w2v2.
Speaker and Language Change Detection using Wav2vec2 and Whisper
Feb 18, 2023We investigate recent transformer networks pre-trained for automatic speech recognition for their ability to detect speaker and language changes in speech. We do this by simply adding speaker (change) or language targets to the labels. For Wav2vec2 pre-trained networks, we also investigate if the representation for the speaker change symbol can be conditioned to capture speaker identity characteristics. Using a number of constructed data sets we show that these capabilities are definitely there, with speaker recognition equal error rates of the order of 10% and language detection error rates of a few percent. We will publish the code for reproducibility.
Training speaker recognition systems with limited data
Mar 28, 2022
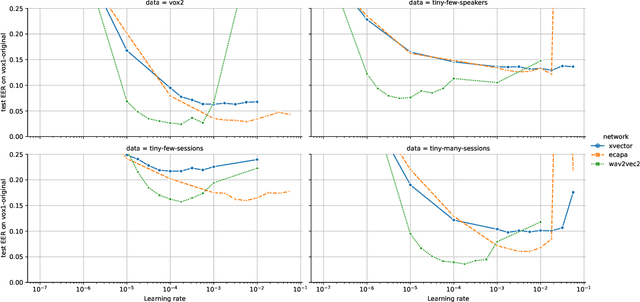
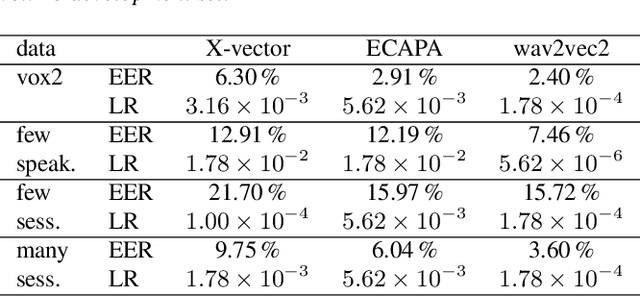
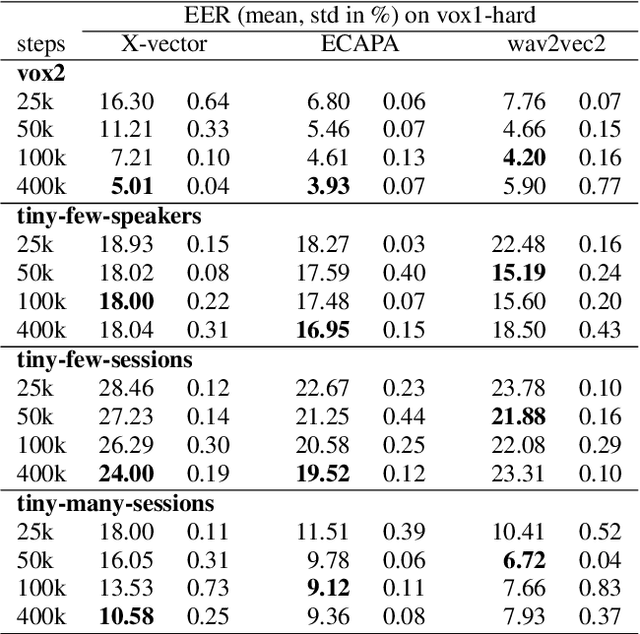
This work considers training neural networks for speaker recognition with a much smaller dataset size compared to contemporary work. We artificially restrict the amount of data by proposing three subsets of the popular VoxCeleb2 dataset. These subsets are restricted to 50 k audio files (versus over 1 M files available), and vary on the axis of number of speakers and session variability. We train three speaker recognition systems on these subsets; the X-vector, ECAPA-TDNN, and wav2vec2 network architectures. We show that the self-supervised, pre-trained weights of wav2vec2 substantially improve performance when training data is limited. Code and data subsets are available at \url{https://github.com/nikvaessen/w2v2-speaker-few-samples}.
Fine-tuning wav2vec2 for speaker recognition
Sep 30, 2021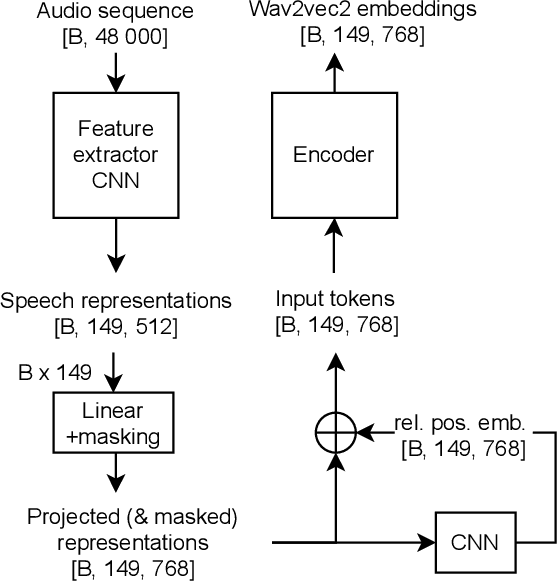
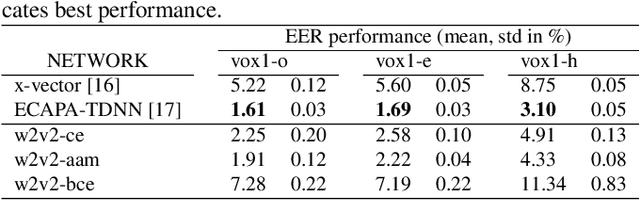
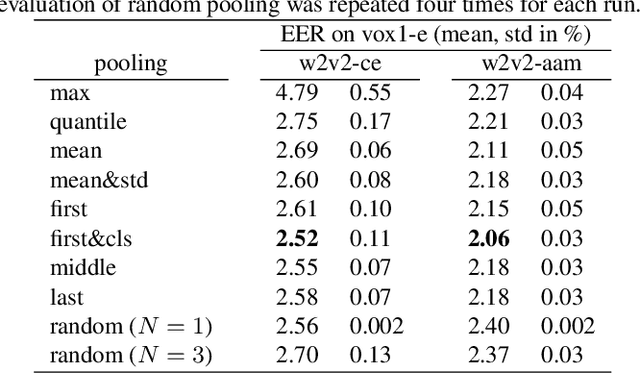
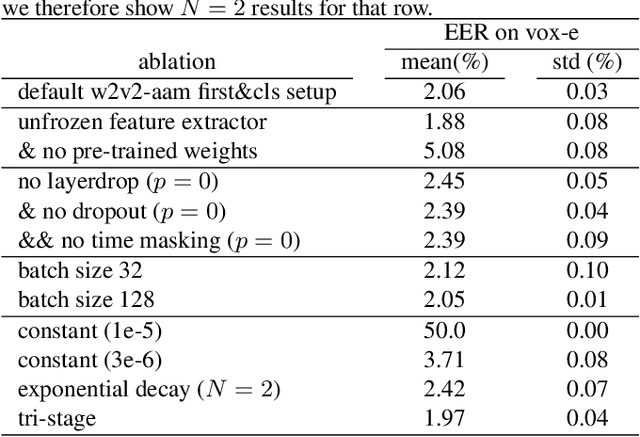
This paper explores applying the wav2vec2 framework to speaker recognition instead of speech recognition. We study the effectiveness of the pre-trained weights on the speaker recognition task, and how to pool the wav2vec2 output sequence into a fixed-length speaker embedding. To adapt the framework to speaker recognition, we propose a single-utterance classification variant with CE or AAM softmax loss, and an utterance-pair classification variant with BCE loss. Our best performing variant, w2v2-aam, achieves a 1.88% EER on the extended voxceleb1 test set compared to 1.69% EER with an ECAPA-TDNN baseline. Code is available at https://github.com/nikvaessen/w2v2-speaker.
Large-Scale Speaker Diarization of Radio Broadcast Archives
Jun 28, 2019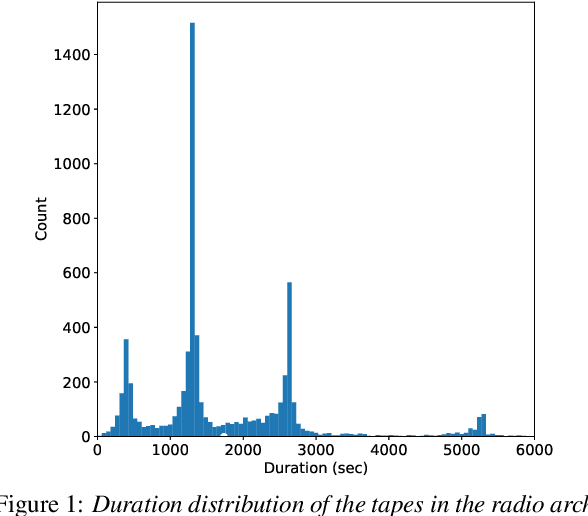
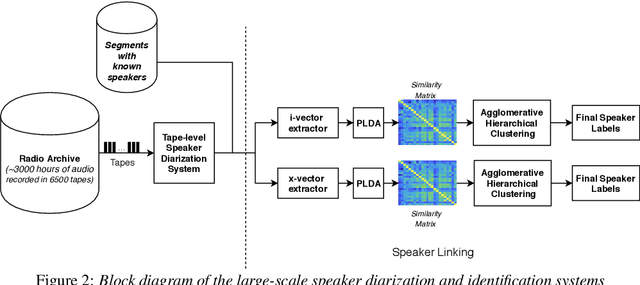

This paper describes our initial efforts to build a large-scale speaker diarization (SD) and identification system on a recently digitized radio broadcast archive from the Netherlands which has more than 6500 audio tapes with 3000 hours of Frisian-Dutch speech recorded between 1950-2016. The employed large-scale diarization scheme involves two stages: (1) tape-level speaker diarization providing pseudo-speaker identities and (2) speaker linking to relate pseudo-speakers appearing in multiple tapes. Having access to the speaker models of several frequently appearing speakers from the previously collected FAME! speech corpus, we further perform speaker identification by linking these known speakers to the pseudo-speakers identified at the first stage. In this work, we present a recently created longitudinal and multilingual SD corpus designed for large-scale SD research and evaluate the performance of a new speaker linking system using x-vectors with PLDA to quantify cross-tape speaker similarity on this corpus. The performance of this speaker linking system is evaluated on a small subset of the archive which is manually annotated with speaker information. The speaker linking performance reported on this subset (53 hours) and the whole archive (3000 hours) is compared to quantify the impact of scaling up in the amount of speech data.
Semi-supervised acoustic model training for speech with code-switching
Oct 23, 2018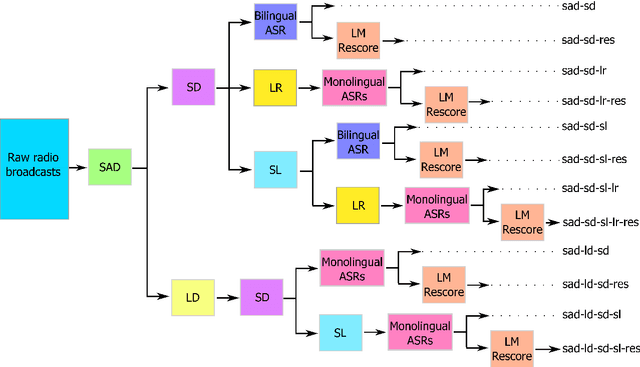
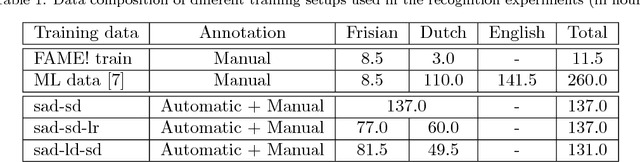

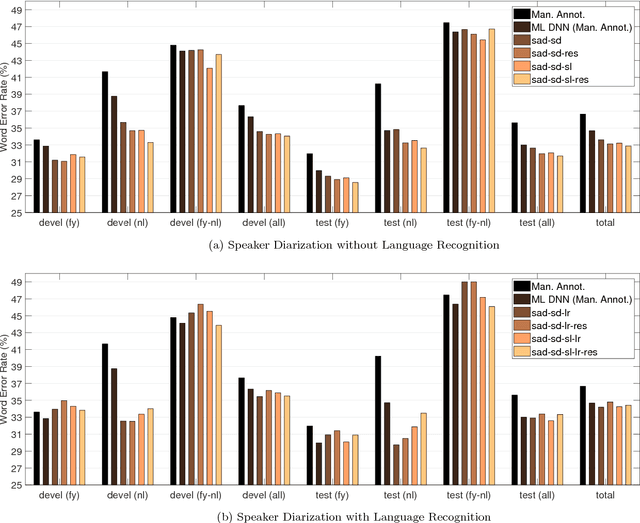
In the FAME! project, we aim to develop an automatic speech recognition (ASR) system for Frisian-Dutch code-switching (CS) speech extracted from the archives of a local broadcaster with the ultimate goal of building a spoken document retrieval system. Unlike Dutch, Frisian is a low-resourced language with a very limited amount of manually annotated speech data. In this paper, we describe several automatic annotation approaches to enable using of a large amount of raw bilingual broadcast data for acoustic model training in a semi-supervised setting. Previously, it has been shown that the best-performing ASR system is obtained by two-stage multilingual deep neural network (DNN) training using 11 hours of manually annotated CS speech (reference) data together with speech data from other high-resourced languages. We compare the quality of transcriptions provided by this bilingual ASR system with several other approaches that use a language recognition system for assigning language labels to raw speech segments at the front-end and using monolingual ASR resources for transcription. We further investigate automatic annotation of the speakers appearing in the raw broadcast data by first labeling with (pseudo) speaker tags using a speaker diarization system and then linking to the known speakers appearing in the reference data using a speaker recognition system. These speaker labels are essential for speaker-adaptive training in the proposed setting. We train acoustic models using the manually and automatically annotated data and run recognition experiments on the development and test data of the FAME! speech corpus to quantify the quality of the automatic annotations. The ASR and CS detection results demonstrate the potential of using automatic language and speaker tagging in semi-supervised bilingual acoustic model training.
Code-Switching Detection with Data-Augmented Acoustic and Language Models
Jul 28, 2018
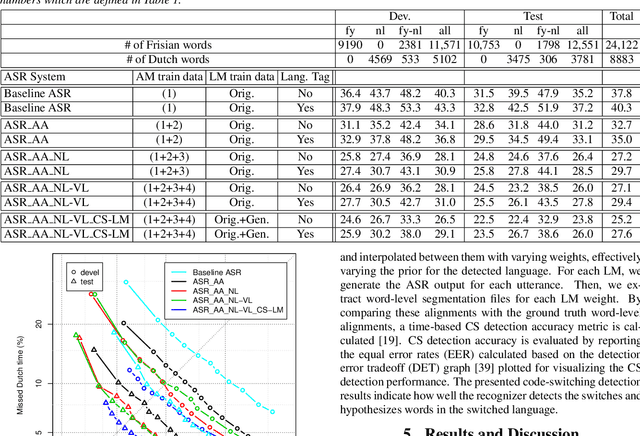
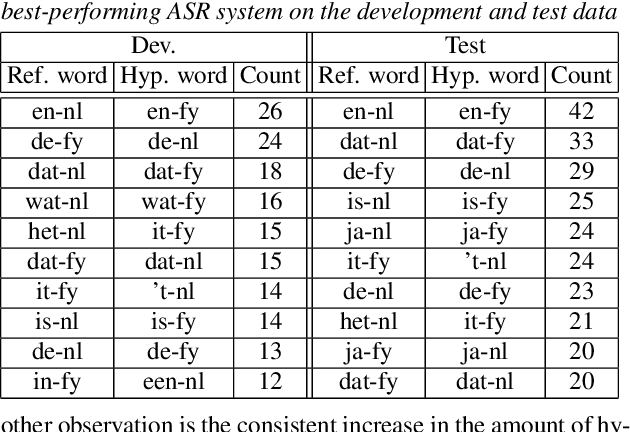

In this paper, we investigate the code-switching detection performance of a code-switching (CS) automatic speech recognition (ASR) system with data-augmented acoustic and language models. We focus on the recognition of Frisian-Dutch radio broadcasts where one of the mixed languages, namely Frisian, is under-resourced. Recently, we have explored how the acoustic modeling (AM) can benefit from monolingual speech data belonging to the high-resourced mixed language. For this purpose, we have trained state-of-the-art AMs on a significantly increased amount of CS speech by applying automatic transcription and monolingual Dutch speech. Moreover, we have improved the language model (LM) by creating CS text in various ways including text generation using recurrent LMs trained on existing CS text. Motivated by the significantly improved CS ASR performance, we delve into the CS detection performance of the same ASR system in this work by reporting CS detection accuracies together with a detailed detection error analysis.
Acoustic and Textual Data Augmentation for Improved ASR of Code-Switching Speech
Jul 28, 2018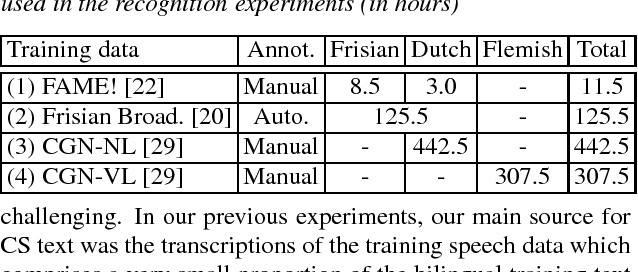
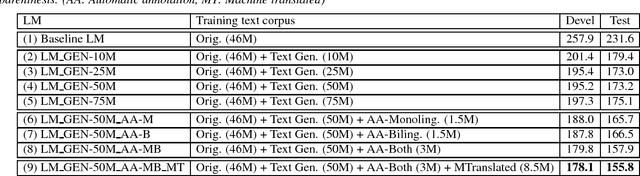
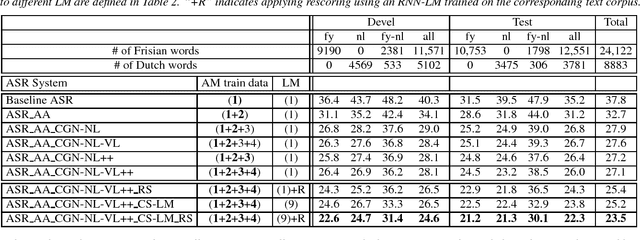
In this paper, we describe several techniques for improving the acoustic and language model of an automatic speech recognition (ASR) system operating on code-switching (CS) speech. We focus on the recognition of Frisian-Dutch radio broadcasts where one of the mixed languages, namely Frisian, is an under-resourced language. In previous work, we have proposed several automatic transcription strategies for CS speech to increase the amount of available training speech data. In this work, we explore how the acoustic modeling (AM) can benefit from monolingual speech data belonging to the high-resourced mixed language. For this purpose, we train state-of-the-art AMs, which were ineffective due to lack of training data, on a significantly increased amount of CS speech and monolingual Dutch speech. Moreover, we improve the language model (LM) by creating code-switching text, which is in practice almost non-existent, by (1) generating text using recurrent LMs trained on the transcriptions of the training CS speech data, (2) adding the transcriptions of the automatically transcribed CS speech data and (3) translating Dutch text extracted from the transcriptions of a large Dutch speech corpora. We report significantly improved CS ASR performance due to the increase in the acoustic and textual training data.
Calibration of Phone Likelihoods in Automatic Speech Recognition
Jun 14, 2016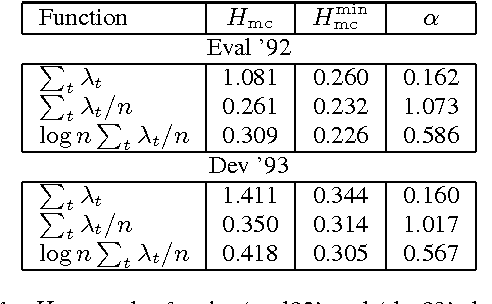
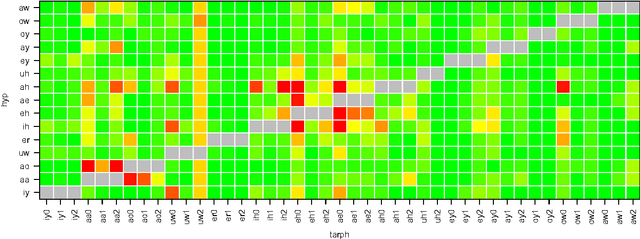
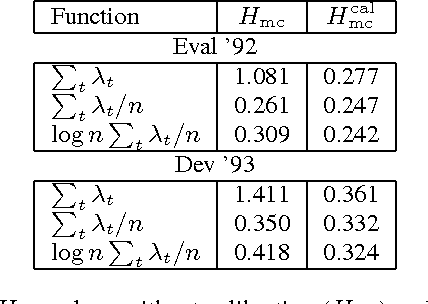
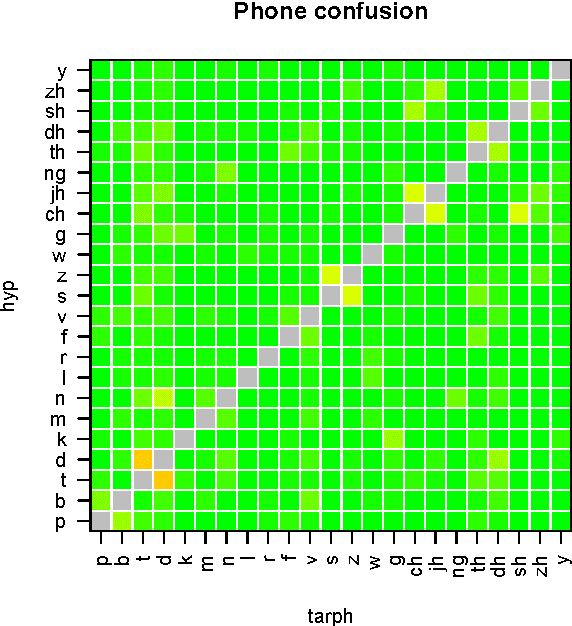
In this paper we study the probabilistic properties of the posteriors in a speech recognition system that uses a deep neural network (DNN) for acoustic modeling. We do this by reducing Kaldi's DNN shared pdf-id posteriors to phone likelihoods, and using test set forced alignments to evaluate these using a calibration sensitive metric. Individual frame posteriors are in principle well-calibrated, because the DNN is trained using cross entropy as the objective function, which is a proper scoring rule. When entire phones are assessed, we observe that it is best to average the log likelihoods over the duration of the phone. Further scaling of the average log likelihoods by the logarithm of the duration slightly improves the calibration, and this improvement is retained when tested on independent test data.