 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcoustic and Textual Data Augmentation for Improved ASR of Code-Switching Speech
Paper and Code
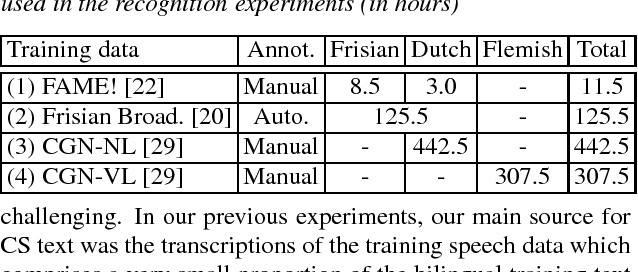
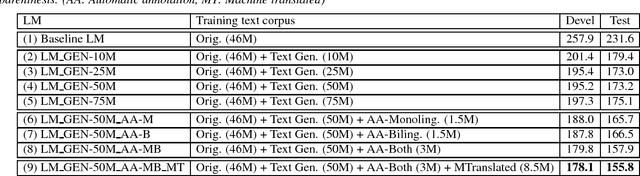
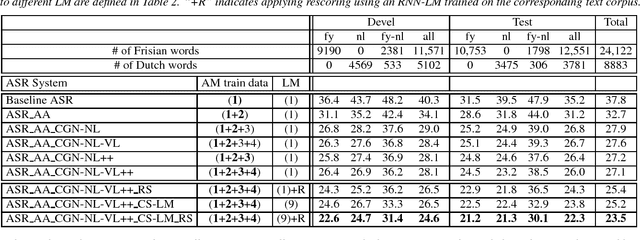
In this paper, we describe several techniques for improving the acoustic and language model of an automatic speech recognition (ASR) system operating on code-switching (CS) speech. We focus on the recognition of Frisian-Dutch radio broadcasts where one of the mixed languages, namely Frisian, is an under-resourced language. In previous work, we have proposed several automatic transcription strategies for CS speech to increase the amount of available training speech data. In this work, we explore how the acoustic modeling (AM) can benefit from monolingual speech data belonging to the high-resourced mixed language. For this purpose, we train state-of-the-art AMs, which were ineffective due to lack of training data, on a significantly increased amount of CS speech and monolingual Dutch speech. Moreover, we improve the language model (LM) by creating code-switching text, which is in practice almost non-existent, by (1) generating text using recurrent LMs trained on the transcriptions of the training CS speech data, (2) adding the transcriptions of the automatically transcribed CS speech data and (3) translating Dutch text extracted from the transcriptions of a large Dutch speech corpora. We report significantly improved CS ASR performance due to the increase in the acoustic and textual training data.