 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-Delayed Transformers for Data-Driven Modeling of Low-Dimensional Dynamics
Feb 09, 2026We propose the time-delayed transformer (TD-TF), a simplified transformer architecture for data-driven modeling of unsteady spatio-temporal dynamics. TD-TF bridges linear operator-based methods and deep sequence models by showing that a single-layer, single-head transformer can be interpreted as a nonlinear generalization of time-delayed dynamic mode decomposition (TD-DMD). The architecture is deliberately minimal, consisting of one self-attention layer with a single query per prediction and one feedforward layer, resulting in linear computational complexity in sequence length and a small parameter count. Numerical experiments demonstrate that TD-TF matches the performance of strong linear baselines on near-linear systems, while significantly outperforming them in nonlinear and chaotic regimes, where it accurately captures long-term dynamics. Validation studies on synthetic signals, unsteady aerodynamics, the Lorenz '63 system, and a reaction-diffusion model show that TD-TF preserves the interpretability and efficiency of linear models while providing substantially enhanced expressive power for complex dynamics.
Semi-supervised Development of ASR Systems for Multilingual Code-switched Speech in Under-resourced Languages
Mar 06, 2020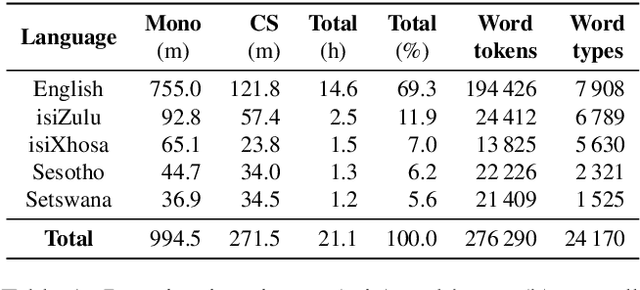
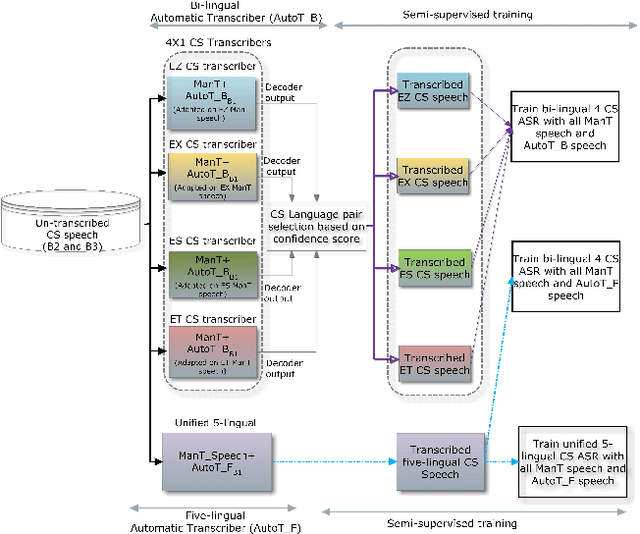
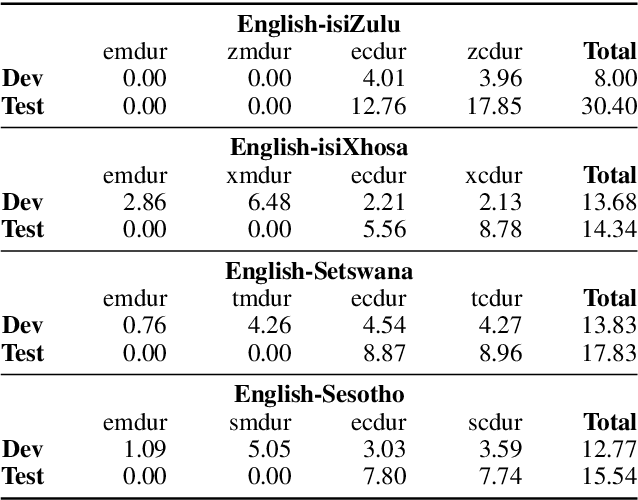
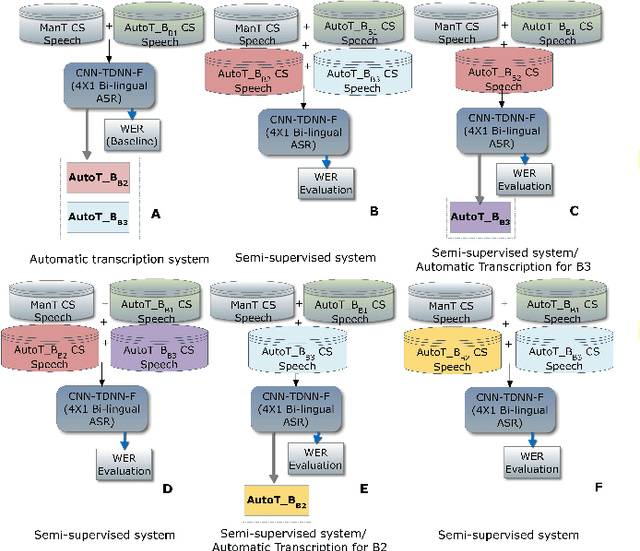
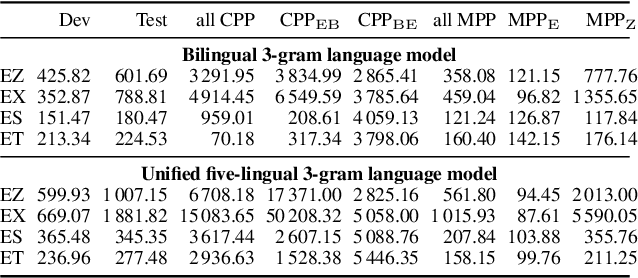
This paper reports on the semi-supervised development of acoustic and language models for under-resourced, code-switched speech in five South African languages. Two approaches are considered. The first constructs four separate bilingual automatic speech recognisers (ASRs) corresponding to four different language pairs between which speakers switch frequently. The second uses a single, unified, five-lingual ASR system that represents all the languages (English, isiZulu, isiXhosa, Setswana and Sesotho). We evaluate the effectiveness of these two approaches when used to add additional data to our extremely sparse training sets. Results indicate that batch-wise semi-supervised training yields better results than a non-batch-wise approach. Furthermore, while the separate bilingual systems achieved better recognition performance than the unified system, they benefited more from pseudo-labels generated by the five-lingual system than from those generated by the bilingual systems.
End-to-End Code-Switching ASR for Low-Resourced Language Pairs
Sep 30, 2019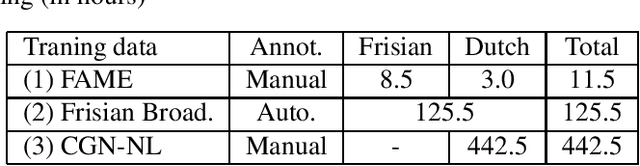
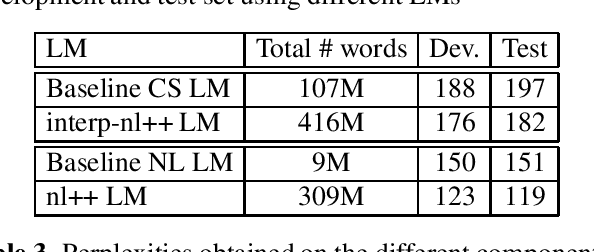
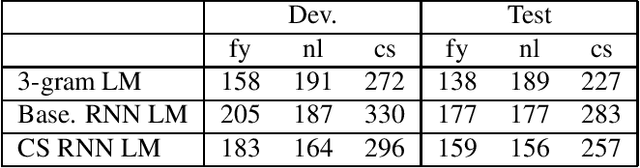
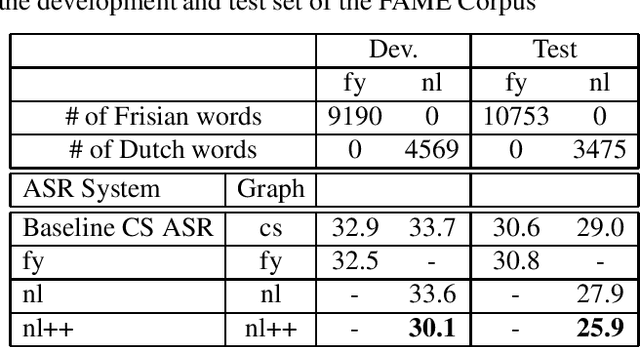
Despite the significant progress in end-to-end (E2E) automatic speech recognition (ASR), E2E ASR for low resourced code-switching (CS) speech has not been well studied. In this work, we describe an E2E ASR pipeline for the recognition of CS speech in which a low-resourced language is mixed with a high resourced language. Low-resourcedness in acoustic data hinders the performance of E2E ASR systems more severely than the conventional ASR systems.~To mitigate this problem in the transcription of archives with code-switching Frisian-Dutch speech, we integrate a designated decoding scheme and perform rescoring with neural network-based language models to enable better utilization of the available textual resources. We first incorporate a multi-graph decoding approach which creates parallel search spaces for each monolingual and mixed recognition tasks to maximize the utilization of the textual resources from each language. Further, language model rescoring is performed using a recurrent neural network pre-trained with cross-lingual embedding and further adapted with the limited amount of in-domain CS text. The ASR experiments demonstrate the effectiveness of the described techniques in improving the recognition performance of an E2E CS ASR system in a low-resourced scenario.
Large-Scale Speaker Diarization of Radio Broadcast Archives
Jun 28, 2019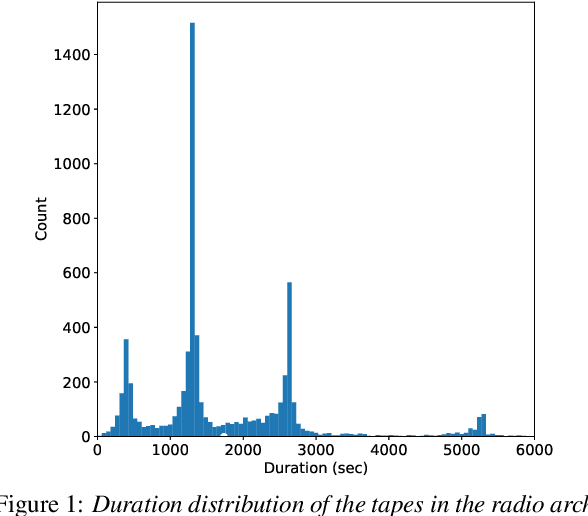
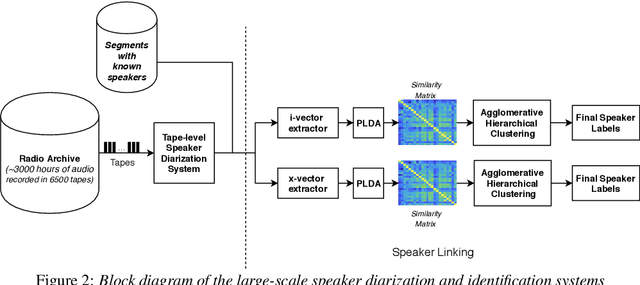

This paper describes our initial efforts to build a large-scale speaker diarization (SD) and identification system on a recently digitized radio broadcast archive from the Netherlands which has more than 6500 audio tapes with 3000 hours of Frisian-Dutch speech recorded between 1950-2016. The employed large-scale diarization scheme involves two stages: (1) tape-level speaker diarization providing pseudo-speaker identities and (2) speaker linking to relate pseudo-speakers appearing in multiple tapes. Having access to the speaker models of several frequently appearing speakers from the previously collected FAME! speech corpus, we further perform speaker identification by linking these known speakers to the pseudo-speakers identified at the first stage. In this work, we present a recently created longitudinal and multilingual SD corpus designed for large-scale SD research and evaluate the performance of a new speaker linking system using x-vectors with PLDA to quantify cross-tape speaker similarity on this corpus. The performance of this speaker linking system is evaluated on a small subset of the archive which is manually annotated with speaker information. The speaker linking performance reported on this subset (53 hours) and the whole archive (3000 hours) is compared to quantify the impact of scaling up in the amount of speech data.
Multi-Graph Decoding for Code-Switching ASR
Jun 28, 2019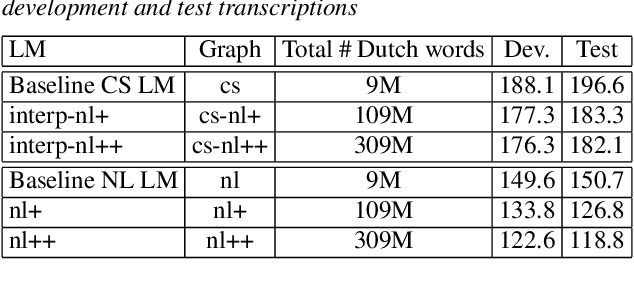

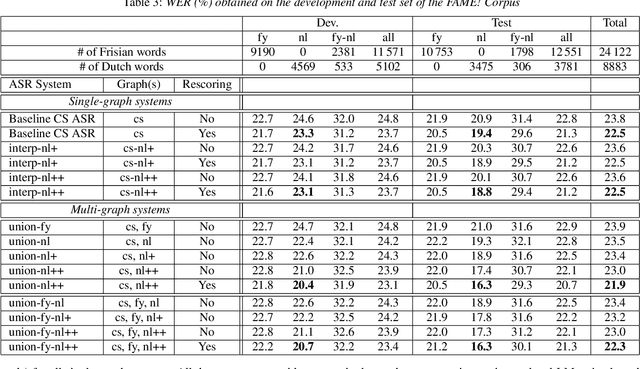
In the FAME! Project, a code-switching (CS) automatic speech recognition (ASR) system for Frisian-Dutch speech is developed that can accurately transcribe the local broadcaster's bilingual archives with CS speech. This archive contains recordings with monolingual Frisian and Dutch speech segments as well as Frisian-Dutch CS speech, hence the recognition performance on monolingual segments is also vital for accurate transcriptions. In this work, we propose a multi-graph decoding and rescoring strategy using bilingual and monolingual graphs together with a unified acoustic model for CS ASR. The proposed decoding scheme gives the freedom to design and employ alternative search spaces for each (monolingual or bilingual) recognition task and enables the effective use of monolingual resources of the high-resourced mixed language in low-resourced CS scenarios. In our scenario, Dutch is the high-resourced and Frisian is the low-resourced language. We therefore use additional monolingual Dutch text resources to improve the Dutch language model (LM) and compare the performance of single- and multi-graph CS ASR systems on Dutch segments using larger Dutch LMs. The ASR results show that the proposed approach outperforms baseline single-graph CS ASR systems, providing better performance on the monolingual Dutch segments without any accuracy loss on monolingual Frisian and code-mixed segments.
Acoustic Modeling for Automatic Lyrics-to-Audio Alignment
Jun 25, 2019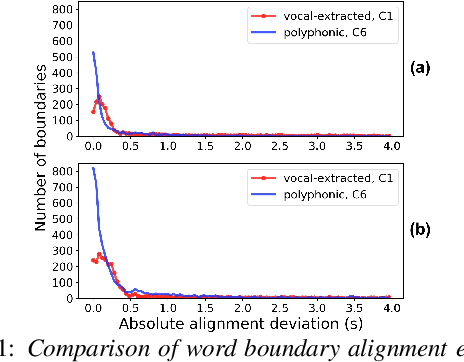



Automatic lyrics to polyphonic audio alignment is a challenging task not only because the vocals are corrupted by background music, but also there is a lack of annotated polyphonic corpus for effective acoustic modeling. In this work, we propose (1) using additional speech and music-informed features and (2) adapting the acoustic models trained on a large amount of solo singing vocals towards polyphonic music using a small amount of in-domain data. Incorporating additional information such as voicing and auditory features together with conventional acoustic features aims to bring robustness against the increased spectro-temporal variations in singing vocals. By adapting the acoustic model using a small amount of polyphonic audio data, we reduce the domain mismatch between training and testing data. We perform several alignment experiments and present an in-depth alignment error analysis on acoustic features, and model adaptation techniques. The results demonstrate that the proposed strategy provides a significant error reduction of word boundary alignment over comparable existing systems, especially on more challenging polyphonic data with long-duration musical interludes.
Semi-supervised acoustic model training for five-lingual code-switched ASR
Jun 20, 2019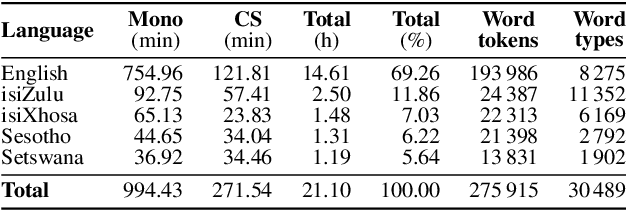
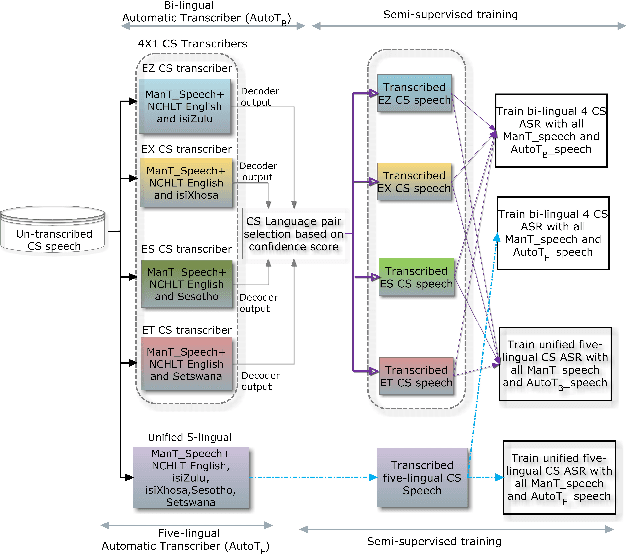
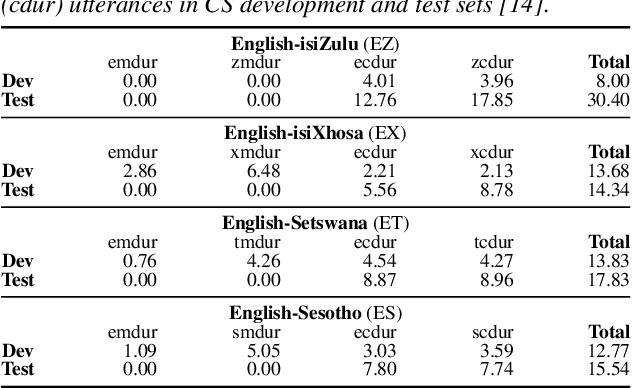
This paper presents recent progress in the acoustic modelling of under-resourced code-switched (CS) speech in multiple South African languages. We consider two approaches. The first constructs separate bilingual acoustic models corresponding to language pairs (English-isiZulu, English-isiXhosa, English-Setswana and English-Sesotho). The second constructs a single unified five-lingual acoustic model representing all the languages (English, isiZulu, isiXhosa, Setswana and Sesotho). For these two approaches we consider the effectiveness of semi-supervised training to increase the size of the very sparse acoustic training sets. Using approximately 11 hours of untranscribed speech, we show that both approaches benefit from semi-supervised training. The bilingual TDNN-F acoustic models also benefit from the addition of CNN layers (CNN-TDNN-F), while the five-lingual system does not show any significant improvement. Furthermore, because English is common to all language pairs in our data, it dominates when training a unified language model, leading to improved English ASR performance at the expense of the other languages. Nevertheless, the five-lingual model offers flexibility because it can process more than two languages simultaneously, and is therefore an attractive option as an automatic transcription system in a semi-supervised training pipeline.
Code-Switching Detection Using ASR-Generated Language Posteriors
Jun 19, 2019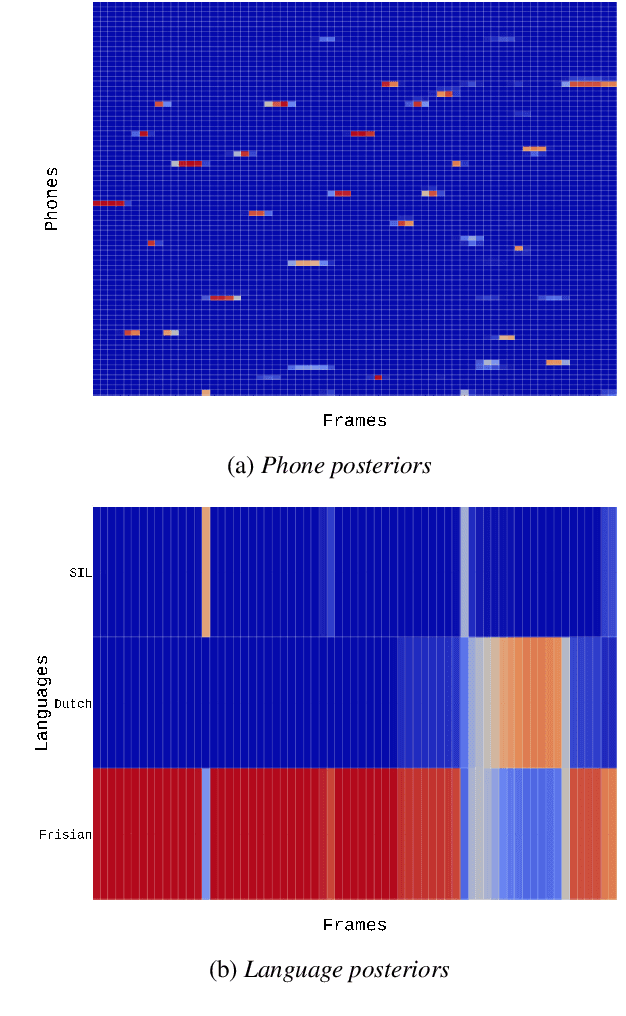
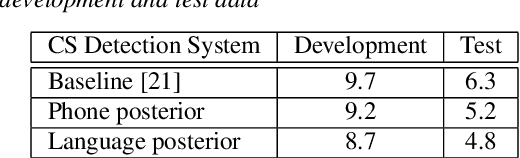
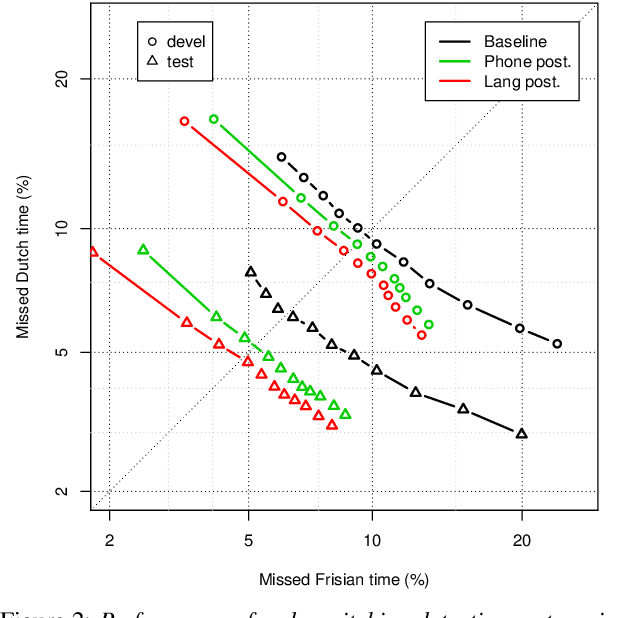
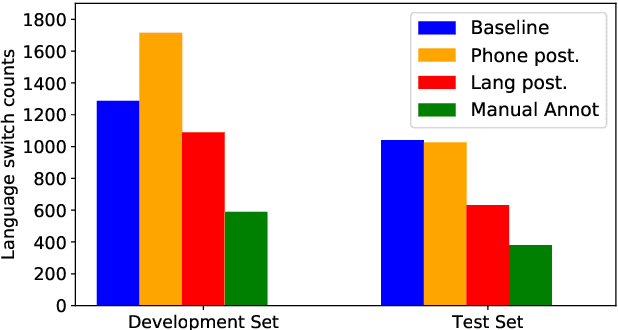
Code-switching (CS) detection refers to the automatic detection of language switches in code-mixed utterances. This task can be achieved by using a CS automatic speech recognition (ASR) system that can handle such language switches. In our previous work, we have investigated the code-switching detection performance of the Frisian-Dutch CS ASR system by using the time alignment of the most likely hypothesis and found that this technique suffers from over-switching due to numerous very short spurious language switches. In this paper, we propose a novel method for CS detection aiming to remedy this shortcoming by using the language posteriors which are the sum of the frame-level posteriors of phones belonging to the same language. The CS ASR-generated language posteriors contain more complete language-specific information on frame level compared to the time alignment of the ASR output. Hence, it is expected to yield more accurate and robust CS detection. The CS detection experiments demonstrate that the proposed language posterior-based approach provides higher detection accuracy than the baseline system in terms of equal error rate. Moreover, a detailed CS detection error analysis reveals that using language posteriors reduces the false alarms and results in more robust CS detection.
Articulatory and bottleneck features for speaker-independent ASR of dysarthric speech
May 21, 2019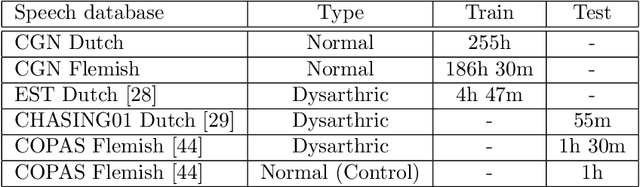
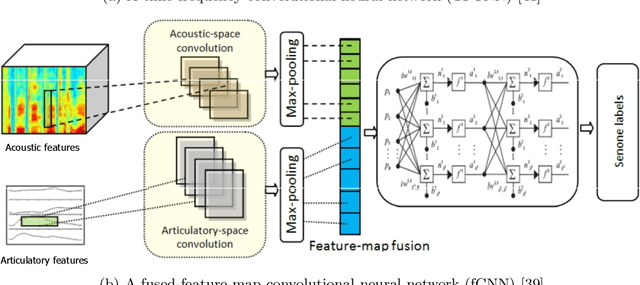
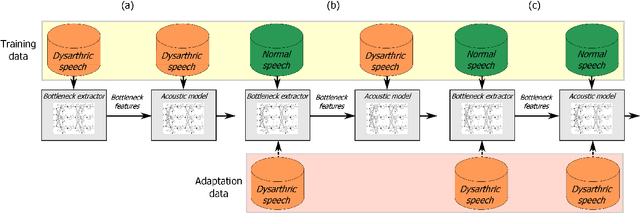
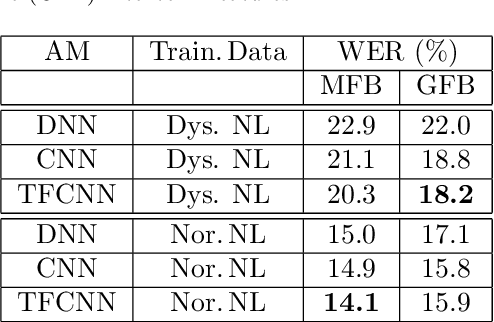
The rapid population aging has stimulated the development of assistive devices that provide personalized medical support to the needies suffering from various etiologies. One prominent clinical application is a computer-assisted speech training system which enables personalized speech therapy to patients impaired by communicative disorders in the patient's home environment. Such a system relies on the robust automatic speech recognition (ASR) technology to be able to provide accurate articulation feedback. With the long-term aim of developing off-the-shelf ASR systems that can be incorporated in clinical context without prior speaker information, we compare the ASR performance of speaker-independent bottleneck and articulatory features on dysarthric speech used in conjunction with dedicated neural network-based acoustic models that have been shown to be robust against spectrotemporal deviations. We report ASR performance of these systems on two dysarthric speech datasets of different characteristics to quantify the achieved performance gains. Despite the remaining performance gap between the dysarthric and normal speech, significant improvements have been reported on both datasets using speaker-independent ASR architectures.
Semi-supervised acoustic model training for speech with code-switching
Oct 23, 2018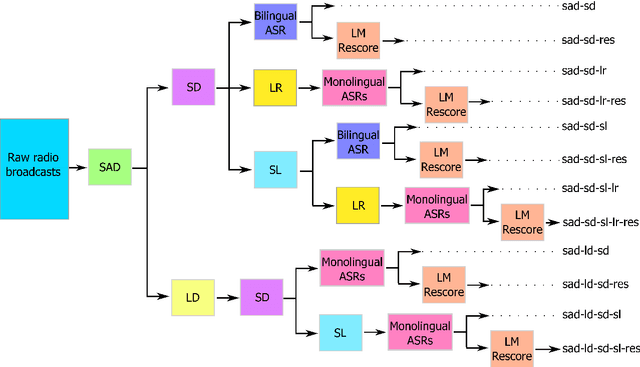
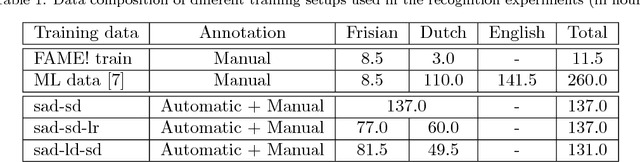

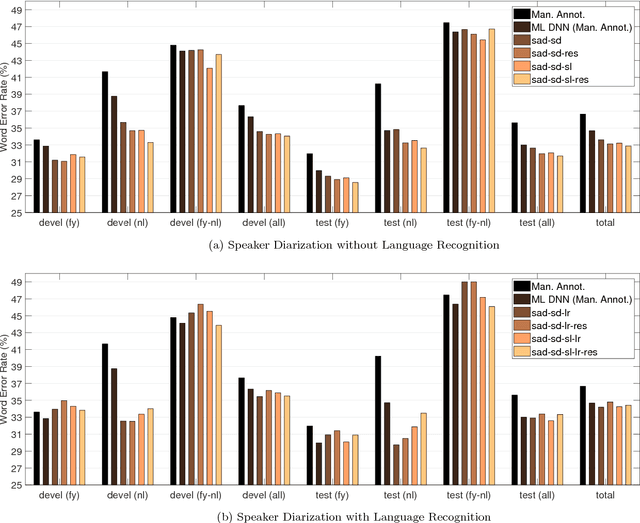
In the FAME! project, we aim to develop an automatic speech recognition (ASR) system for Frisian-Dutch code-switching (CS) speech extracted from the archives of a local broadcaster with the ultimate goal of building a spoken document retrieval system. Unlike Dutch, Frisian is a low-resourced language with a very limited amount of manually annotated speech data. In this paper, we describe several automatic annotation approaches to enable using of a large amount of raw bilingual broadcast data for acoustic model training in a semi-supervised setting. Previously, it has been shown that the best-performing ASR system is obtained by two-stage multilingual deep neural network (DNN) training using 11 hours of manually annotated CS speech (reference) data together with speech data from other high-resourced languages. We compare the quality of transcriptions provided by this bilingual ASR system with several other approaches that use a language recognition system for assigning language labels to raw speech segments at the front-end and using monolingual ASR resources for transcription. We further investigate automatic annotation of the speakers appearing in the raw broadcast data by first labeling with (pseudo) speaker tags using a speaker diarization system and then linking to the known speakers appearing in the reference data using a speaker recognition system. These speaker labels are essential for speaker-adaptive training in the proposed setting. We train acoustic models using the manually and automatically annotated data and run recognition experiments on the development and test data of the FAME! speech corpus to quantify the quality of the automatic annotations. The ASR and CS detection results demonstrate the potential of using automatic language and speaker tagging in semi-supervised bilingual acoustic model training.