 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigation and Analysis of Hyper and Hypo neuron pruning to selectively update neurons during Unsupervised Adaptation
Jan 06, 2020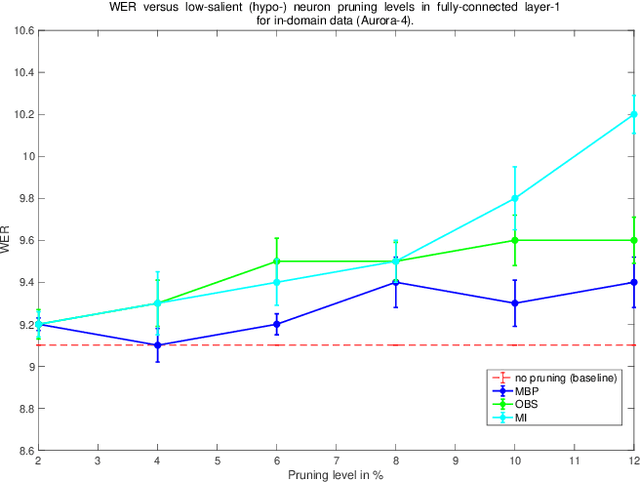
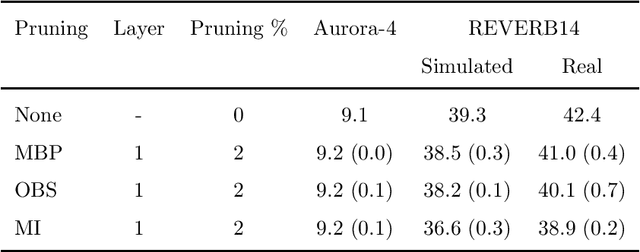
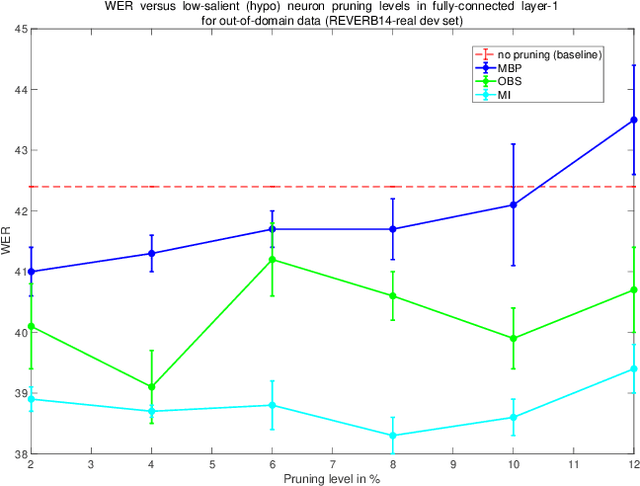
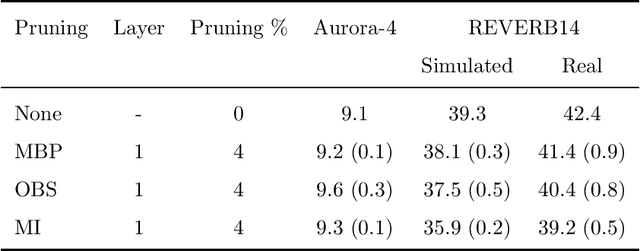
Unseen or out-of-domain data can seriously degrade the performance of a neural network model, indicating the model's failure to generalize to unseen data. Neural net pruning can not only help to reduce a model's size but can improve the model's generalization capacity as well. Pruning approaches look for low-salient neurons that are less contributive to a model's decision and hence can be removed from the model. This work investigates if pruning approaches are successful in detecting neurons that are either high-salient (mostly active or hyper) or low-salient (barely active or hypo), and whether removal of such neurons can help to improve the model's generalization capacity. Traditional blind adaptation techniques update either the whole or a subset of layers, but have never explored selectively updating individual neurons across one or more layers. Focusing on the fully connected layers of a convolutional neural network (CNN), this work shows that it may be possible to selectively adapt certain neurons (consisting of the hyper and the hypo neurons) first, followed by a full-network fine tuning. Using the task of automatic speech recognition, this work demonstrates how the removal of hyper and hypo neurons from a model can improve the model's performance on out-of-domain speech data and how selective neuron adaptation can ensure improved performance when compared to traditional blind model adaptation.
Articulatory and bottleneck features for speaker-independent ASR of dysarthric speech
May 21, 2019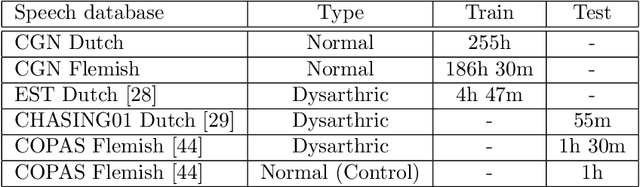
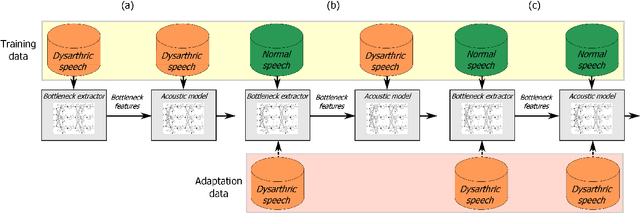
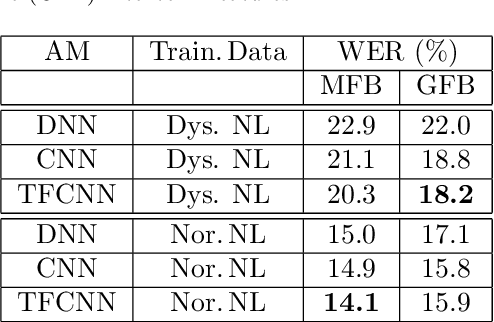
The rapid population aging has stimulated the development of assistive devices that provide personalized medical support to the needies suffering from various etiologies. One prominent clinical application is a computer-assisted speech training system which enables personalized speech therapy to patients impaired by communicative disorders in the patient's home environment. Such a system relies on the robust automatic speech recognition (ASR) technology to be able to provide accurate articulation feedback. With the long-term aim of developing off-the-shelf ASR systems that can be incorporated in clinical context without prior speaker information, we compare the ASR performance of speaker-independent bottleneck and articulatory features on dysarthric speech used in conjunction with dedicated neural network-based acoustic models that have been shown to be robust against spectrotemporal deviations. We report ASR performance of these systems on two dysarthric speech datasets of different characteristics to quantify the achieved performance gains. Despite the remaining performance gap between the dysarthric and normal speech, significant improvements have been reported on both datasets using speaker-independent ASR architectures.
Articulatory Features for ASR of Pathological Speech
Jul 28, 2018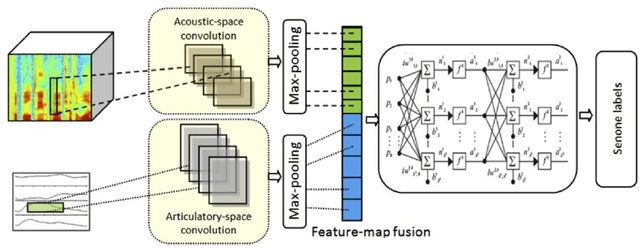
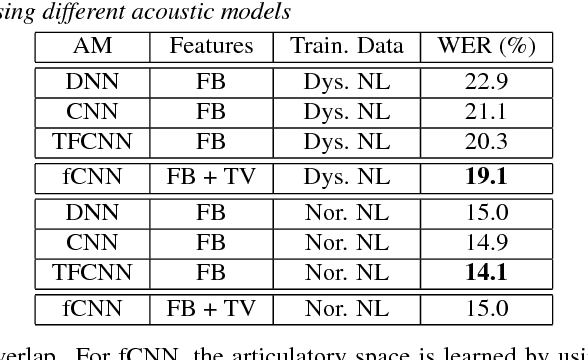
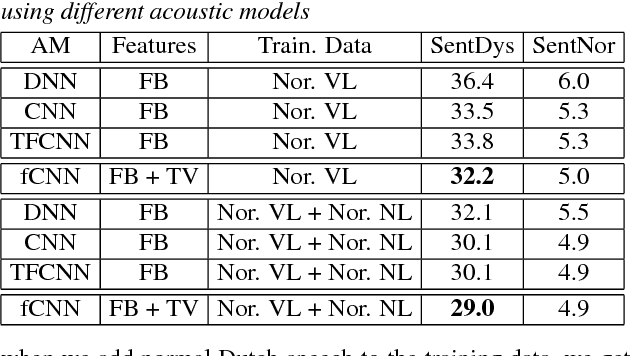
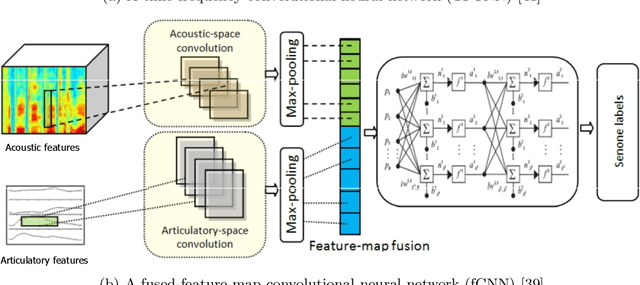
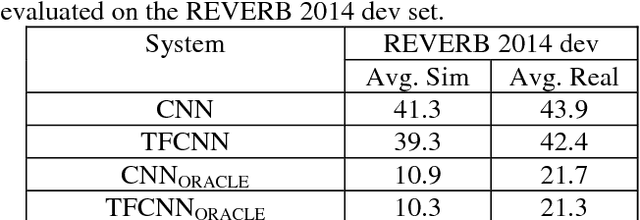
In this work, we investigate the joint use of articulatory and acoustic features for automatic speech recognition (ASR) of pathological speech. Despite long-lasting efforts to build speaker- and text-independent ASR systems for people with dysarthria, the performance of state-of-the-art systems is still considerably lower on this type of speech than on normal speech. The most prominent reason for the inferior performance is the high variability in pathological speech that is characterized by the spectrotemporal deviations caused by articulatory impairments due to various etiologies. To cope with this high variation, we propose to use speech representations which utilize articulatory information together with the acoustic properties. A designated acoustic model, namely a fused-feature-map convolutional neural network (fCNN), which performs frequency convolution on acoustic features and time convolution on articulatory features is trained and tested on a Dutch and a Flemish pathological speech corpus. The ASR performance of fCNN-based ASR system using joint features is compared to other neural network architectures such conventional CNNs and time-frequency convolutional networks (TFCNNs) in several training scenarios.
Articulatory information and Multiview Features for Large Vocabulary Continuous Speech Recognition
Feb 16, 2018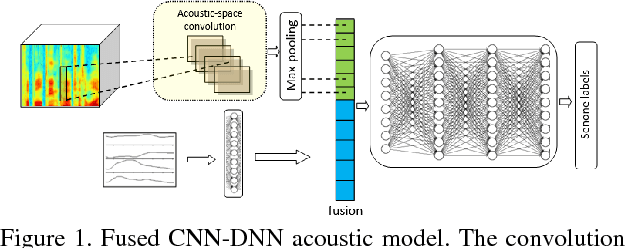
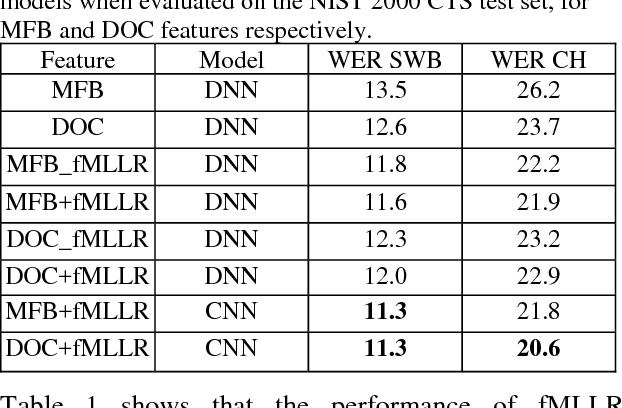
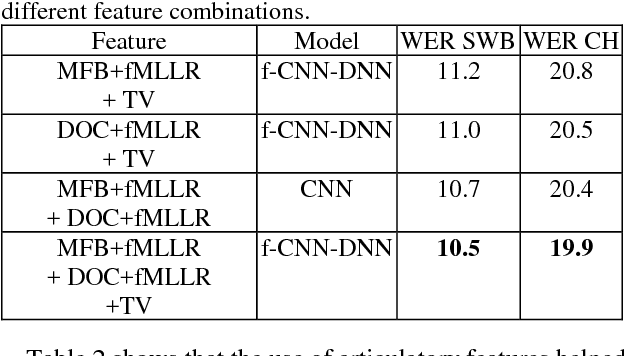
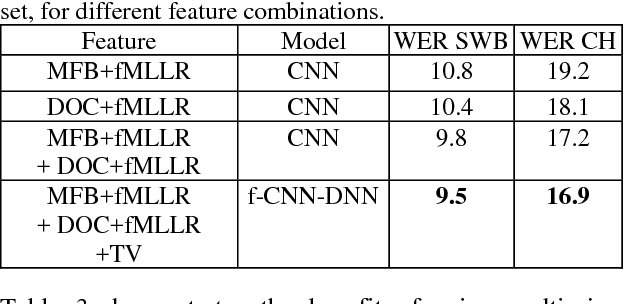
This paper explores the use of multi-view features and their discriminative transforms in a convolutional deep neural network (CNN) architecture for a continuous large vocabulary speech recognition task. Mel-filterbank energies and perceptually motivated forced damped oscillator coefficient (DOC) features are used after feature-space maximum-likelihood linear regression (fMLLR) transforms, which are combined and fed as a multi-view feature to a single CNN acoustic model. Use of multi-view feature representation demonstrated significant reduction in word error rates (WERs) compared to the use of individual features by themselves. In addition, when articulatory information was used as an additional input to a fused deep neural network (DNN) and CNN acoustic model, it was found to demonstrate further reduction in WER for the Switchboard subset and the CallHome subset (containing partly non-native accented speech) of the NIST 2000 conversational telephone speech test set, reducing the error rate by 12% relative to the baseline in both cases. This work shows that multi-view features in association with articulatory information can improve speech recognition robustness to spontaneous and non-native speech.
Interpreting DNN output layer activations: A strategy to cope with unseen data in speech recognition
Feb 16, 2018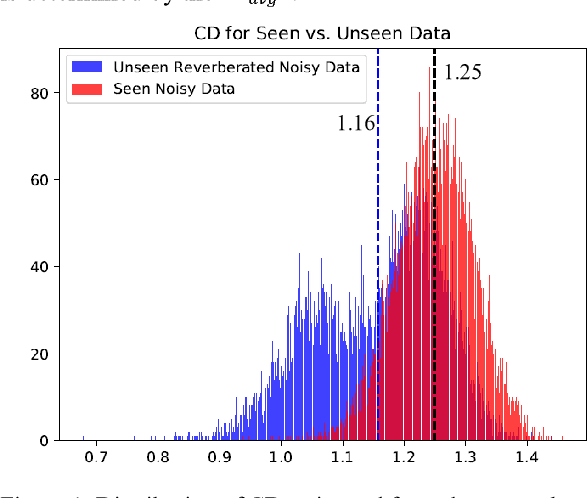
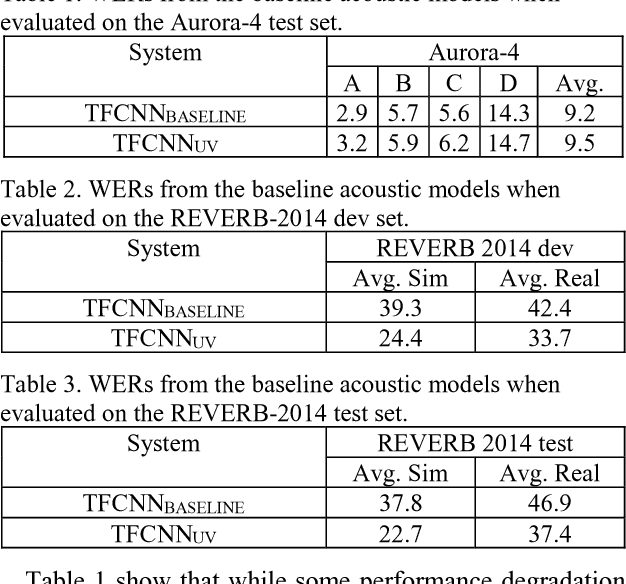
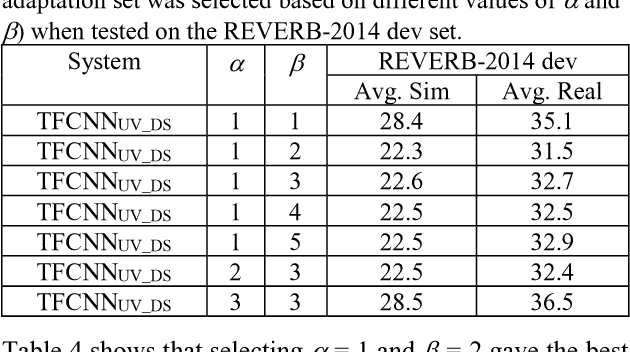

Unseen data can degrade performance of deep neural net acoustic models. To cope with unseen data, adaptation techniques are deployed. For unlabeled unseen data, one must generate some hypothesis given an existing model, which is used as the label for model adaptation. However, assessing the goodness of the hypothesis can be difficult, and an erroneous hypothesis can lead to poorly trained models. In such cases, a strategy to select data having reliable hypothesis can ensure better model adaptation. This work proposes a data-selection strategy for DNN model adaptation, where DNN output layer activations are used to ascertain the goodness of a generated hypothesis. In a DNN acoustic model, the output layer activations are used to generate target class probabilities. Under unseen data conditions, the difference between the most probable target and the next most probable target is decreased compared to the same for seen data, indicating that the model may be uncertain while generating its hypothesis. This work proposes a strategy to assess a model's performance by analyzing the output layer activations by using a distance measure between the most likely target and the next most likely target, which is used for data selection for performing unsupervised adaptation.
Leveraging Deep Neural Network Activation Entropy to cope with Unseen Data in Speech Recognition
Aug 31, 2017
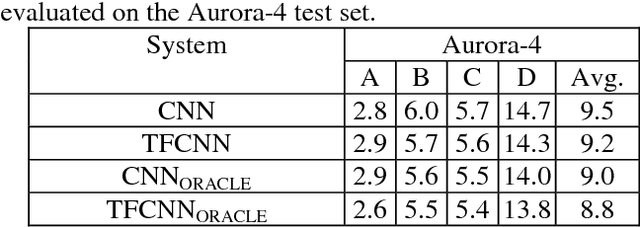
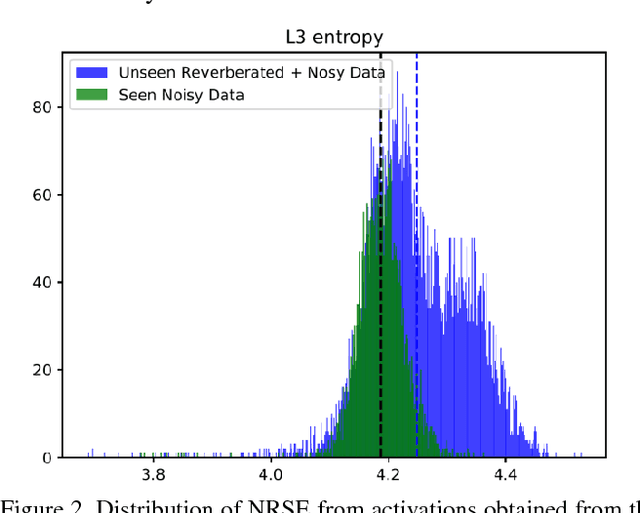
Unseen data conditions can inflict serious performance degradation on systems relying on supervised machine learning algorithms. Because data can often be unseen, and because traditional machine learning algorithms are trained in a supervised manner, unsupervised adaptation techniques must be used to adapt the model to the unseen data conditions. However, unsupervised adaptation is often challenging, as one must generate some hypothesis given a model and then use that hypothesis to bootstrap the model to the unseen data conditions. Unfortunately, reliability of such hypotheses is often poor, given the mismatch between the training and testing datasets. In such cases, a model hypothesis confidence measure enables performing data selection for the model adaptation. Underlying this approach is the fact that for unseen data conditions, data variability is introduced to the model, which the model propagates to its output decision, impacting decision reliability. In a fully connected network, this data variability is propagated as distortions from one layer to the next. This work aims to estimate the propagation of such distortion in the form of network activation entropy, which is measured over a short- time running window on the activation from each neuron of a given hidden layer, and these measurements are then used to compute summary entropy. This work demonstrates that such an entropy measure can help to select data for unsupervised model adaptation, resulting in performance gains in speech recognition tasks. Results from standard benchmark speech recognition tasks show that the proposed approach can alleviate the performance degradation experienced under unseen data conditions by iteratively adapting the model to the unseen datas acoustic condition.