 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePindrop it! Audio and Visual Deepfake Countermeasures for Robust Detection and Fine Grained-Localization
Aug 11, 2025The field of visual and audio generation is burgeoning with new state-of-the-art methods. This rapid proliferation of new techniques underscores the need for robust solutions for detecting synthetic content in videos. In particular, when fine-grained alterations via localized manipulations are performed in visual, audio, or both domains, these subtle modifications add challenges to the detection algorithms. This paper presents solutions for the problems of deepfake video classification and localization. The methods were submitted to the ACM 1M Deepfakes Detection Challenge, achieving the best performance in the temporal localization task and a top four ranking in the classification task for the TestA split of the evaluation dataset.
Phonetic Richness for Improved Automatic Speaker Verification
Jul 10, 2024When it comes to authentication in speaker verification systems, not all utterances are created equal. It is essential to estimate the quality of test utterances in order to account for varying acoustic conditions. In addition to the net-speech duration of an utterance, it is observed in this paper that phonetic richness is also a key indicator of utterance quality, playing a significant role in accurate speaker verification. Several phonetic histogram based formulations of phonetic richness are explored using transcripts obtained from an automatic speaker recognition system. The proposed phonetic richness measure is found to be positively correlated with voice authentication scores across evaluation benchmarks. Additionally, the proposed measure in combination with net speech helps in calibrating the speaker verification scores, obtaining a relative EER improvement of 5.8% on the Voxceleb1 evaluation protocol. The proposed phonetic richness based calibration provides higher benefit for short utterances with repeated words.
Deciphering diffuse scattering with machine learning and the equivariant foundation model: The case of molten FeO
Mar 01, 2024Bridging the gap between diffuse x-ray or neutron scattering measurements and predicted structures derived from atom-atom pair potentials in disordered materials, has been a longstanding challenge in condensed matter physics. This perspective gives a brief overview of the traditional approaches employed over the past several decades. Namely, the use of approximate interatomic pair potentials that relate 3-dimensional structural models to the measured structure factor and its associated pair distribution function. The use of machine learned interatomic potentials has grown in the past few years, and has been particularly successful in the cases of ionic and oxide systems. Recent advances in large scale sampling, along with a direct integration of scattering measurements into the model development, has provided improved agreement between experiments and large-scale models calculated with quantum mechanical accuracy. However, details of local polyhedral bonding and connectivity in meta-stable disordered systems still require improvement. Here we leverage MACE-MP-0; a newly introduced equivariant foundation model and validate the results against high-quality experimental scattering data for the case of molten iron(II) oxide (FeO). These preliminary results suggest that the emerging foundation model has the potential to surpass the traditional limitations of classical interatomic potentials.
Cloud Services Enable Efficient AI-Guided Simulation Workflows across Heterogeneous Resources
Mar 15, 2023Applications that fuse machine learning and simulation can benefit from the use of multiple computing resources, with, for example, simulation codes running on highly parallel supercomputers and AI training and inference tasks on specialized accelerators. Here, we present our experiences deploying two AI-guided simulation workflows across such heterogeneous systems. A unique aspect of our approach is our use of cloud-hosted management services to manage challenging aspects of cross-resource authentication and authorization, function-as-a-service (FaaS) function invocation, and data transfer. We show that these methods can achieve performance parity with systems that rely on direct connection between resources. We achieve parity by integrating the FaaS system and data transfer capabilities with a system that passes data by reference among managers and workers, and a user-configurable steering algorithm to hide data transfer latencies. We anticipate that this ease of use can enable routine use of heterogeneous resources in computational science.
Acoustic-to-articulatory Speech Inversion with Multi-task Learning
May 27, 2022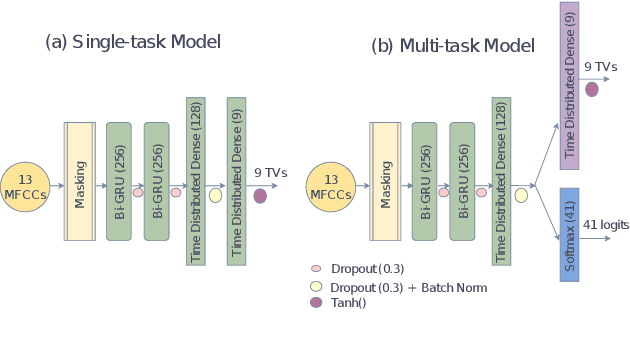


Multi-task learning (MTL) frameworks have proven to be effective in diverse speech related tasks like automatic speech recognition (ASR) and speech emotion recognition. This paper proposes a MTL framework to perform acoustic-to-articulatory speech inversion by simultaneously learning an acoustic to phoneme mapping as a shared task. We use the Haskins Production Rate Comparison (HPRC) database which has both the electromagnetic articulography (EMA) data and the corresponding phonetic transcriptions. Performance of the system was measured by computing the correlation between estimated and actual tract variables (TVs) from the acoustic to articulatory speech inversion task. The proposed MTL based Bidirectional Gated Recurrent Neural Network (RNN) model learns to map the input acoustic features to nine TVs while outperforming the baseline model trained to perform only acoustic to articulatory inversion.
Audio Data Augmentation for Acoustic-to-articulatory Speech Inversion using Bidirectional Gated RNNs
May 25, 2022
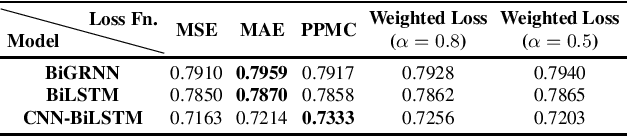
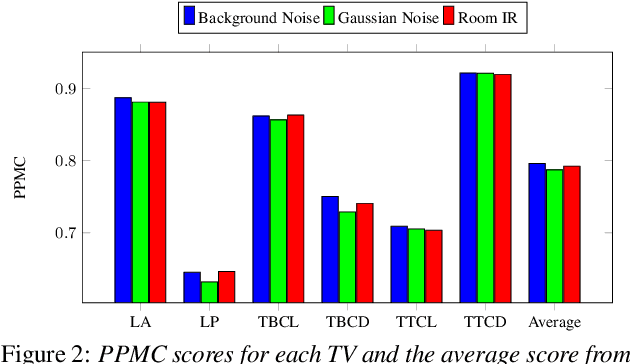
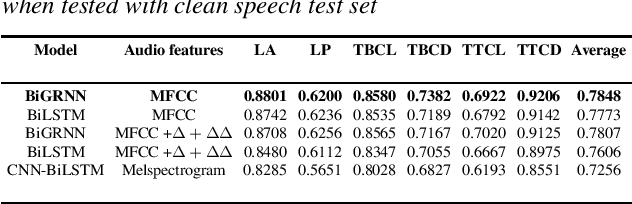
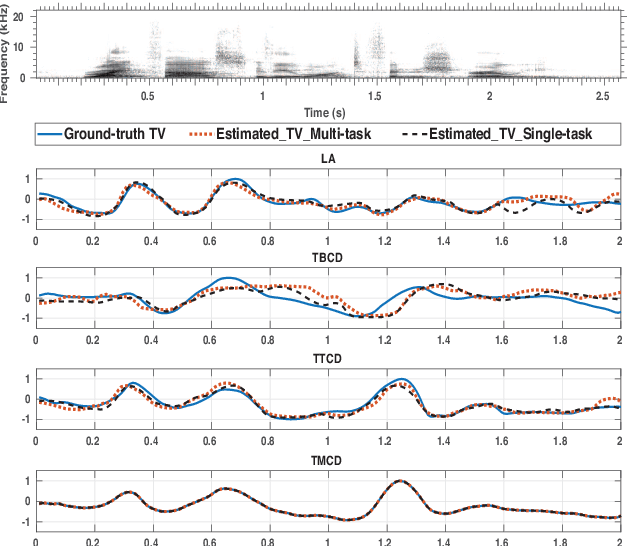
Data augmentation has proven to be a promising prospect in improving the performance of deep learning models by adding variability to training data. In previous work with developing a noise robust acoustic-to-articulatory speech inversion system, we have shown the importance of noise augmentation to improve the performance of speech inversion in noisy speech. In this work, we compare and contrast different ways of doing data augmentation and show how this technique improves the performance of articulatory speech inversion not only on noisy speech, but also on clean speech data. We also propose a Bidirectional Gated Recurrent Neural Network as the speech inversion system instead of the previously used feed forward neural network. The inversion system uses mel-frequency cepstral coefficients (MFCCs) as the input acoustic features and six vocal tract-variables (TVs) as the output articulatory features. The Performance of the system was measured by computing the correlation between estimated and actual TVs on the U. Wisc. X-ray Microbeam database. The proposed speech inversion system shows a 5% relative improvement in correlation over the baseline noise robust system for clean speech data. The pre-trained model, when adapted to each unseen speaker in the test set, improves the average correlation by another 6%.
Acoustic To Articulatory Speech Inversion Using Multi-Resolution Spectro-Temporal Representations Of Speech Signals
Mar 11, 2022

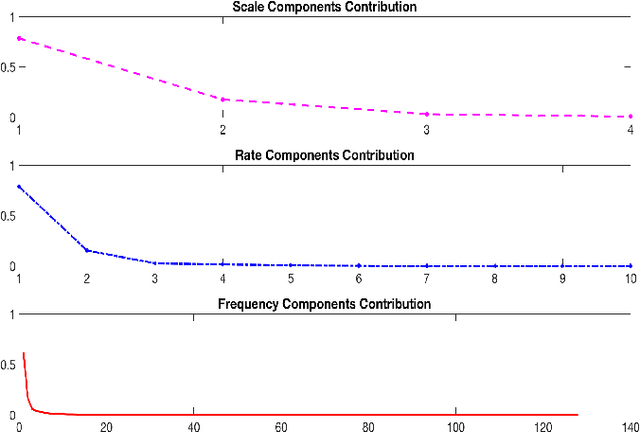

Multi-resolution spectro-temporal features of a speech signal represent how the brain perceives sounds by tuning cortical cells to different spectral and temporal modulations. These features produce a higher dimensional representation of the speech signals. The purpose of this paper is to evaluate how well the auditory cortex representation of speech signals contribute to estimate articulatory features of those corresponding signals. Since obtaining articulatory features from acoustic features of speech signals has been a challenging topic of interest for different speech communities, we investigate the possibility of using this multi-resolution representation of speech signals as acoustic features. We used U. of Wisconsin X-ray Microbeam (XRMB) database of clean speech signals to train a feed-forward deep neural network (DNN) to estimate articulatory trajectories of six tract variables. The optimal set of multi-resolution spectro-temporal features to train the model were chosen using appropriate scale and rate vector parameters to obtain the best performing model. Experiments achieved a correlation of 0.675 with ground-truth tract variables. We compared the performance of this speech inversion system with prior experiments conducted using Mel Frequency Cepstral Coefficients (MFCCs).
Colmena: Scalable Machine-Learning-Based Steering of Ensemble Simulations for High Performance Computing
Oct 06, 2021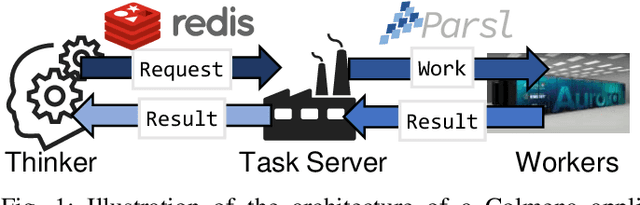
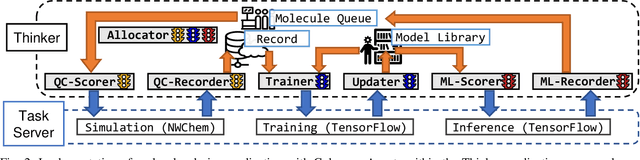
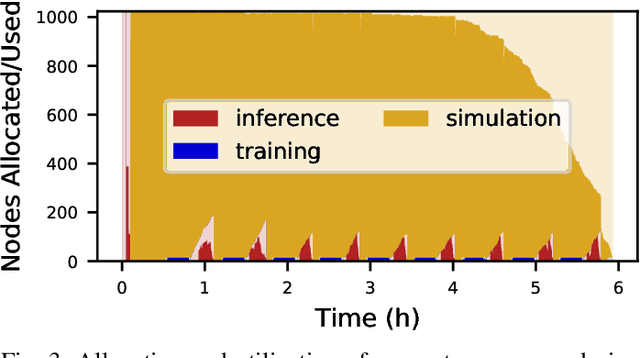
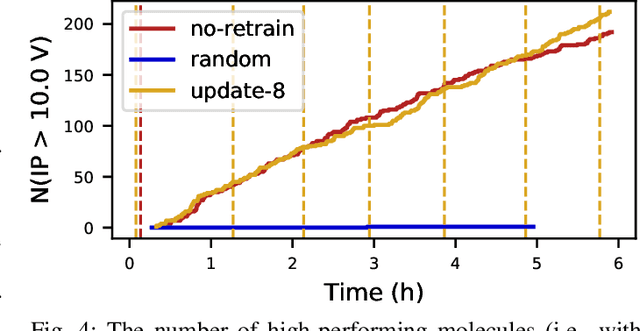
Scientific applications that involve simulation ensembles can be accelerated greatly by using experiment design methods to select the best simulations to perform. Methods that use machine learning (ML) to create proxy models of simulations show particular promise for guiding ensembles but are challenging to deploy because of the need to coordinate dynamic mixes of simulation and learning tasks. We present Colmena, an open-source Python framework that allows users to steer campaigns by providing just the implementations of individual tasks plus the logic used to choose which tasks to execute when. Colmena handles task dispatch, results collation, ML model invocation, and ML model (re)training, using Parsl to execute tasks on HPC systems. We describe the design of Colmena and illustrate its capabilities by applying it to electrolyte design, where it both scales to 65536 CPUs and accelerates the discovery rate for high-performance molecules by a factor of 100 over unguided searches.
Evening the Score: Targeting SARS-CoV-2 Protease Inhibition in Graph Generative Models for Therapeutic Candidates
May 07, 2021
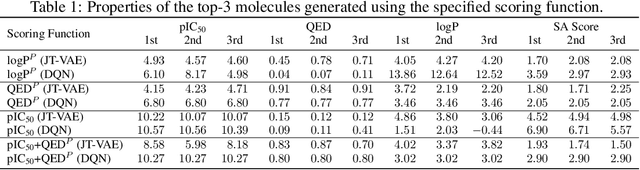

We examine a pair of graph generative models for the therapeutic design of novel drug candidates targeting SARS-CoV-2 viral proteins. Due to a sense of urgency, we chose well-validated models with unique strengths: an autoencoder that generates molecules with similar structures to a dataset of drugs with anti-SARS activity and a reinforcement learning algorithm that generates highly novel molecules. During generation, we explore optimization toward several design targets to balance druglikeness, synthetic accessability, and anti-SARS activity based on \icfifty. This generative framework\footnote{https://github.com/exalearn/covid-drug-design} will accelerate drug discovery in future pandemics through the high-throughput generation of targeted therapeutic candidates.
* arXiv admin note: substantial text overlap with arXiv:2102.04977
Benchmarking Deep Graph Generative Models for Optimizing New Drug Molecules for COVID-19
Feb 09, 2021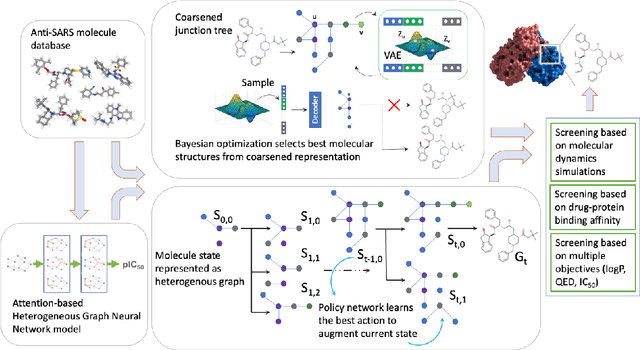
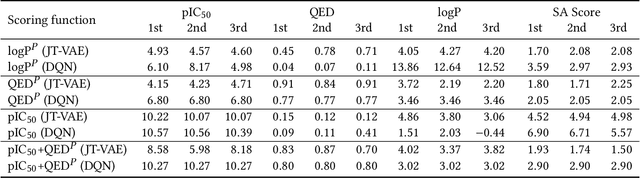
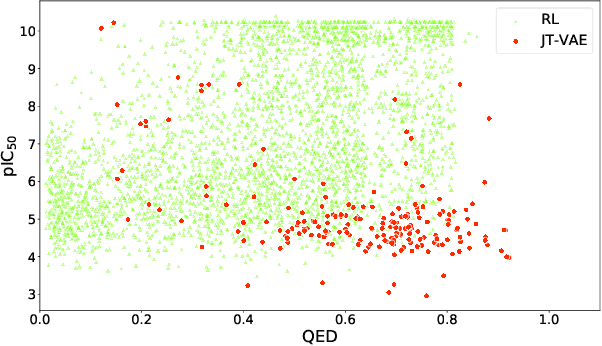
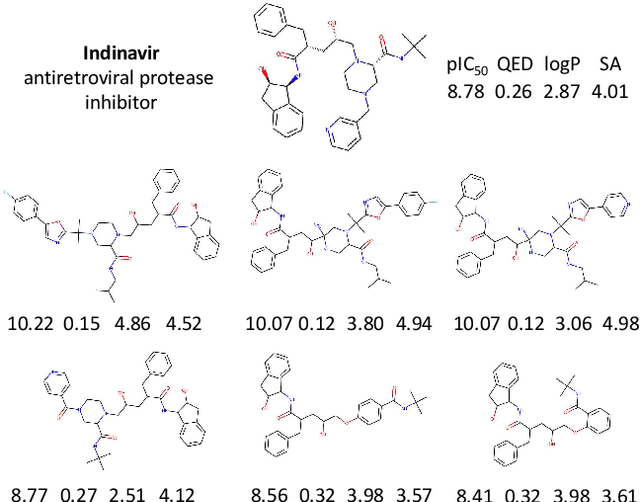
Design of new drug compounds with target properties is a key area of research in generative modeling. We present a small drug molecule design pipeline based on graph-generative models and a comparison study of two state-of-the-art graph generative models for designing COVID-19 targeted drug candidates: 1) a variational autoencoder-based approach (VAE) that uses prior knowledge of molecules that have been shown to be effective for earlier coronavirus treatments and 2) a deep Q-learning method (DQN) that generates optimized molecules without any proximity constraints. We evaluate the novelty of the automated molecule generation approaches by validating the candidate molecules with drug-protein binding affinity models. The VAE method produced two novel molecules with similar structures to the antiretroviral protease inhibitor Indinavir that show potential binding affinity for the SARS-CoV-2 protein target 3-chymotrypsin-like protease (3CL-protease).