 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards noise-robust speech inversion through multi-task learning with speech enhancement
Jan 20, 2026Recent studies demonstrate the effectiveness of Self Supervised Learning (SSL) speech representations for Speech Inversion (SI). However, applying SI in real-world scenarios remains challenging due to the pervasive presence of background noise. We propose a unified framework that integrates Speech Enhancement (SE) and SI models through shared SSL-based speech representations. In this framework, the SSL model is trained not only to support the SE module in suppressing noise but also to produce representations that are more informative for the SI task, allowing both modules to benefit from joint training. At a Signal-to-Noise Ratio of -5 db, our method for the SI task achieves relative improvements over the baseline of 80.95% under babble noise and 38.98% under non-babble noise, as measured by the average Pearson product-moment correlation across all estimated parameters.
Acoustic to Articulatory Speech Inversion for Children with Velopharyngeal Insufficiency
Sep 11, 2025
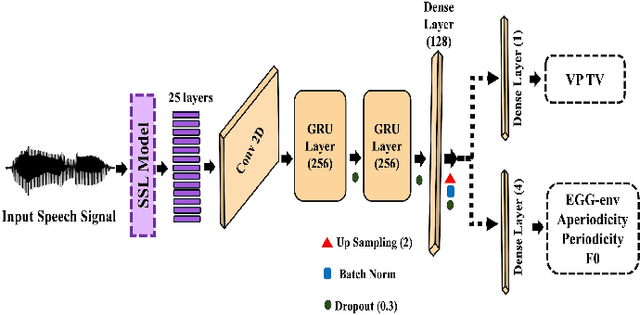
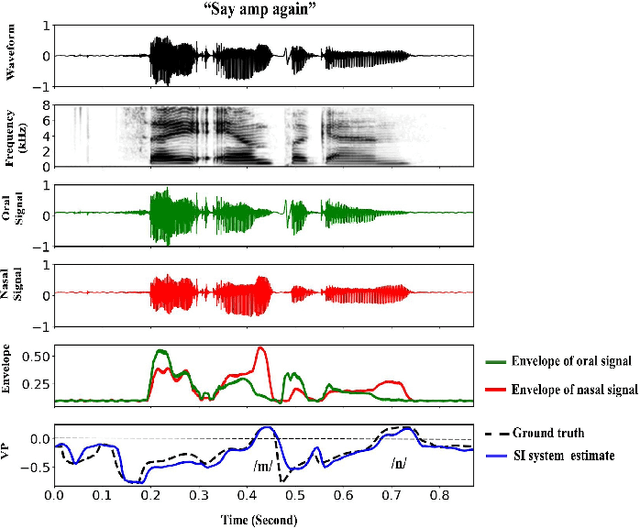
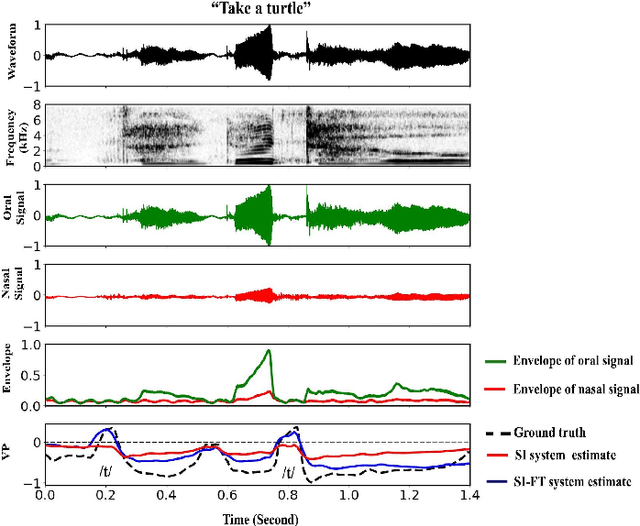
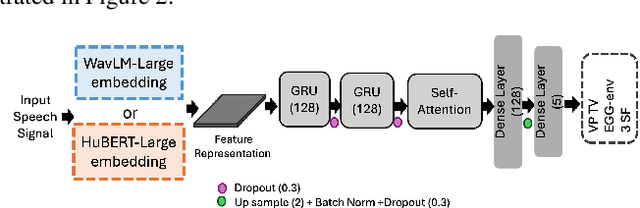
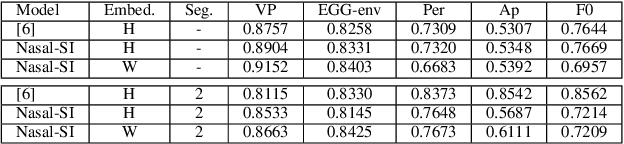
Traditional clinical approaches for assessing nasality, such as nasopharyngoscopy and nasometry, involve unpleasant experiences and are problematic for children. Speech Inversion (SI), a noninvasive technique, offers a promising alternative for estimating articulatory movement without the need for physical instrumentation. In this study, an SI system trained on nasalance data from healthy adults is augmented with source information from electroglottography and acoustically derived F0, periodic and aperiodic energy estimates as proxies for glottal control. This model achieves 16.92% relative improvement in Pearson Product-Moment Correlation (PPMC) compared to a previous SI system for nasalance estimation. To adapt the SI system for nasalance estimation in children with Velopharyngeal Insufficiency (VPI), the model initially trained on adult speech was fine-tuned using children with VPI data, yielding an 7.90% relative improvement in PPMC compared to its performance before fine-tuning.
Perceptual Ratings Predict Speech Inversion Articulatory Kinematics in Childhood Speech Sound Disorders
Jul 02, 2025



Purpose: This study evaluated whether articulatory kinematics, inferred by Articulatory Phonology speech inversion neural networks, aligned with perceptual ratings of /r/ and /s/ in the speech of children with speech sound disorders. Methods: Articulatory Phonology vocal tract variables were inferred for 5,961 utterances from 118 children and 3 adults, aged 2.25-45 years. Perceptual ratings were standardized using the novel 5-point PERCEPT Rating Scale and training protocol. Two research questions examined if the articulatory patterns of inferred vocal tract variables aligned with the perceptual error category for the phones investigated (e.g., tongue tip is more anterior in dentalized /s/ productions than in correct /s/). A third research question examined if gradient PERCEPT Rating Scale scores predicted articulatory proximity to correct productions. Results: Estimated marginal means from linear mixed models supported 17 of 18 /r/ hypotheses, involving tongue tip and tongue body constrictions. For /s/, estimated marginal means from a second linear mixed model supported 7 of 15 hypotheses, particularly those related to the tongue tip. A third linear mixed model revealed that PERCEPT Rating Scale scores significantly predicted articulatory proximity of errored phones to correct productions. Conclusion: Inferred vocal tract variables differentiated category and magnitude of articulatory errors for /r/, and to a lesser extent for /s/, aligning with perceptual judgments. These findings support the clinical interpretability of speech inversion vocal tract variables and the PERCEPT Rating Scale in quantifying articulatory proximity to the target sound, particularly for /r/.
Enhancing Acoustic-to-Articulatory Speech Inversion by Incorporating Nasality
Jun 10, 2025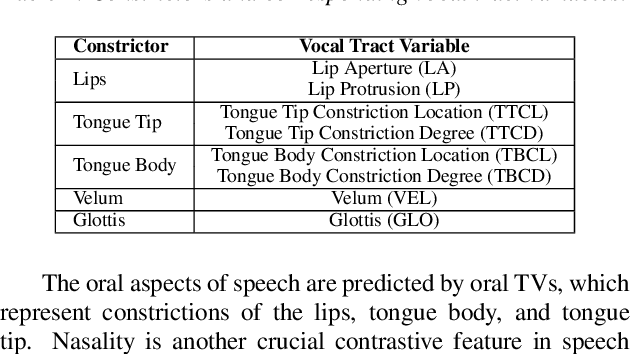
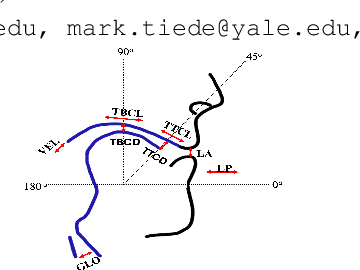
Speech is produced through the coordination of vocal tract constricting organs: lips, tongue, velum, and glottis. Previous works developed Speech Inversion (SI) systems to recover acoustic-to-articulatory mappings for lip and tongue constrictions, called oral tract variables (TVs), which were later enhanced by including source information (periodic and aperiodic energies, and F0 frequency) as proxies for glottal control. Comparison of the nasometric measures with high-speed nasopharyngoscopy showed that nasalance can serve as ground truth, and that an SI system trained with it reliably recovers velum movement patterns for American English speakers. Here, two SI training approaches are compared: baseline models that estimate oral TVs and nasalance independently, and a synergistic model that combines oral TVs and source features with nasalance. The synergistic model shows relative improvements of 5% in oral TVs estimation and 9% in nasalance estimation compared to the baseline models.
FT-Boosted SV: Towards Noise Robust Speaker Verification for English Speaking Classroom Environments
May 26, 2025Creating Speaker Verification (SV) systems for classroom settings that are robust to classroom noises such as babble noise is crucial for the development of AI tools that assist educational environments. In this work, we study the efficacy of finetuning with augmented children datasets to adapt the x-vector and ECAPA-TDNN to classroom environments. We demonstrate that finetuning with augmented children's datasets is powerful in that regard and reduces the Equal Error Rate (EER) of x-vector and ECAPA-TDNN models for both classroom datasets and children speech datasets. Notably, this method reduces EER of the ECAPA-TDNN model on average by half (a 5 % improvement) for classrooms in the MPT dataset compared to the ECAPA-TDNN baseline model. The x-vector model shows an 8 % average improvement for classrooms in the NCTE dataset compared to its baseline.
Multimodal Biomarkers for Schizophrenia: Towards Individual Symptom Severity Estimation
May 21, 2025Studies on schizophrenia assessments using deep learning typically treat it as a classification task to detect the presence or absence of the disorder, oversimplifying the condition and reducing its clinical applicability. This traditional approach overlooks the complexity of schizophrenia, limiting its practical value in healthcare settings. This study shifts the focus to individual symptom severity estimation using a multimodal approach that integrates speech, video, and text inputs. We develop unimodal models for each modality and a multimodal framework to improve accuracy and robustness. By capturing a more detailed symptom profile, this approach can help in enhancing diagnostic precision and support personalized treatment, offering a scalable and objective tool for mental health assessment.
Analyzing the Impact of Accent on English Speech: Acoustic and Articulatory Perspectives
May 21, 2025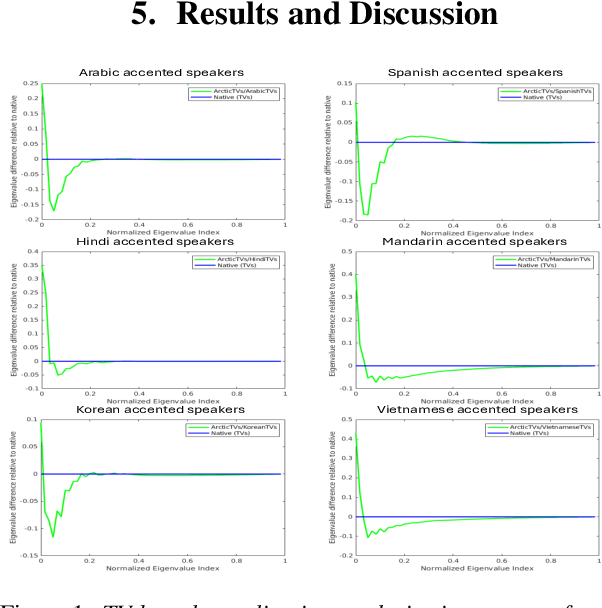
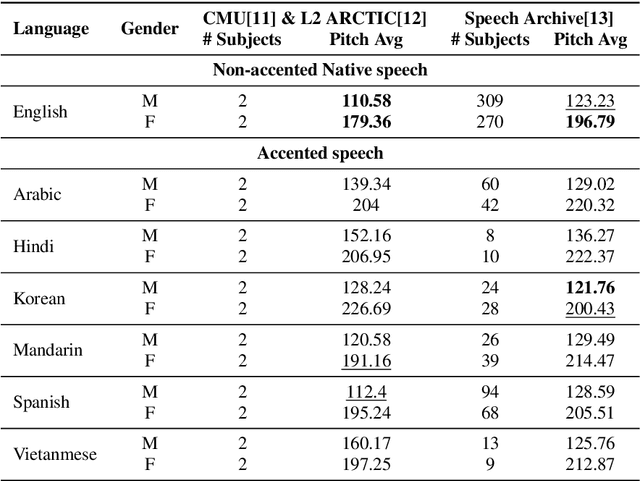
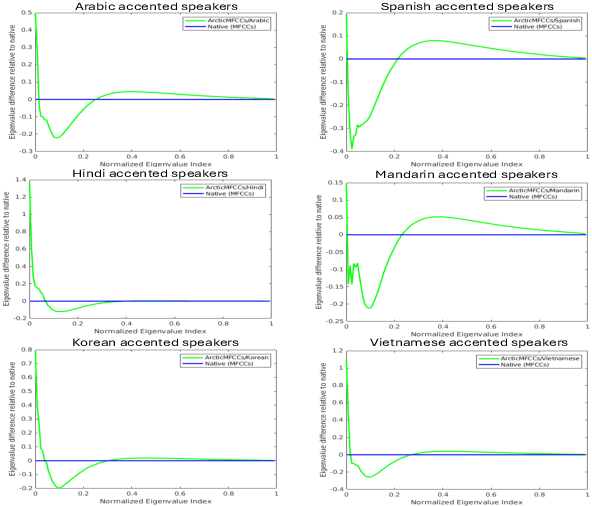
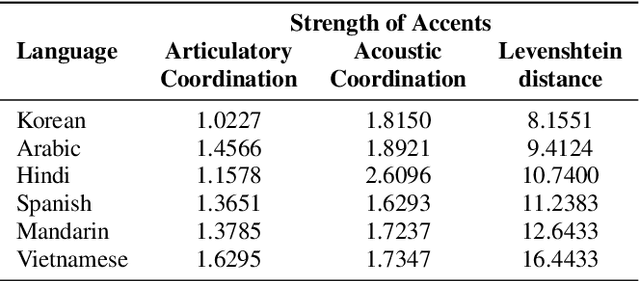
Advancements in AI-driven speech-based applications have transformed diverse industries ranging from healthcare to customer service. However, the increasing prevalence of non-native accented speech in global interactions poses significant challenges for speech-processing systems, which are often trained on datasets dominated by native speech. This study investigates accented English speech through articulatory and acoustic analysis, identifying simpler coordination patterns and higher average pitch than native speech. Using eigenspectra and Vocal Tract Variable-based coordination features, we establish an efficient method for quantifying accent strength without relying on resource-intensive phonetic transcriptions. Our findings provide a new avenue for research on the impacts of accents on speech intelligibility and offer insights for developing inclusive, robust speech processing systems that accommodate diverse linguistic communities.
From Weak Labels to Strong Results: Utilizing 5,000 Hours of Noisy Classroom Transcripts with Minimal Accurate Data
May 20, 2025Recent progress in speech recognition has relied on models trained on vast amounts of labeled data. However, classroom Automatic Speech Recognition (ASR) faces the real-world challenge of abundant weak transcripts paired with only a small amount of accurate, gold-standard data. In such low-resource settings, high transcription costs make re-transcription impractical. To address this, we ask: what is the best approach when abundant inexpensive weak transcripts coexist with limited gold-standard data, as is the case for classroom speech data? We propose Weakly Supervised Pretraining (WSP), a two-step process where models are first pretrained on weak transcripts in a supervised manner, and then fine-tuned on accurate data. Our results, based on both synthetic and real weak transcripts, show that WSP outperforms alternative methods, establishing it as an effective training methodology for low-resource ASR in real-world scenarios.
Speech-Based Estimation of Schizophrenia Severity Using Feature Fusion
Nov 20, 2024



Speech-based assessment of the schizophrenia spectrum has been widely researched over in the recent past. In this study, we develop a deep learning framework to estimate schizophrenia severity scores from speech using a feature fusion approach that fuses articulatory features with different self-supervised speech features extracted from pre-trained audio models. We also propose an auto-encoder-based self-supervised representation learning framework to extract compact articulatory embeddings from speech. Our top-performing speech-based fusion model with Multi-Head Attention (MHA) reduces Mean Absolute Error (MAE) by 9.18% and Root Mean Squared Error (RMSE) by 9.36% for schizophrenia severity estimation when compared with the previous models that combined speech and video inputs.
Self-supervised Multimodal Speech Representations for the Assessment of Schizophrenia Symptoms
Sep 15, 2024



Multimodal schizophrenia assessment systems have gained traction over the last few years. This work introduces a schizophrenia assessment system to discern between prominent symptom classes of schizophrenia and predict an overall schizophrenia severity score. We develop a Vector Quantized Variational Auto-Encoder (VQ-VAE) based Multimodal Representation Learning (MRL) model to produce task-agnostic speech representations from vocal Tract Variables (TVs) and Facial Action Units (FAUs). These representations are then used in a Multi-Task Learning (MTL) based downstream prediction model to obtain class labels and an overall severity score. The proposed framework outperforms the previous works on the multi-class classification task across all evaluation metrics (Weighted F1 score, AUC-ROC score, and Weighted Accuracy). Additionally, it estimates the schizophrenia severity score, a task not addressed by earlier approaches.