 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealClass: A Framework for Classroom Speech Simulation with Public Datasets and Game Engines
Oct 01, 2025The scarcity of large-scale classroom speech data has hindered the development of AI-driven speech models for education. Classroom datasets remain limited and not publicly available, and the absence of dedicated classroom noise or Room Impulse Response (RIR) corpora prevents the use of standard data augmentation techniques. In this paper, we introduce a scalable methodology for synthesizing classroom noise and RIRs using game engines, a versatile framework that can extend to other domains beyond the classroom. Building on this methodology, we present RealClass, a dataset that combines a synthesized classroom noise corpus with a classroom speech dataset compiled from publicly available corpora. The speech data pairs a children's speech corpus with instructional speech extracted from YouTube videos to approximate real classroom interactions in clean conditions. Experiments on clean and noisy speech show that RealClass closely approximates real classroom speech, making it a valuable asset in the absence of abundant real classroom speech.
SimClass: A Classroom Speech Dataset Generated via Game Engine Simulation For Automatic Speech Recognition Research
Jun 10, 2025

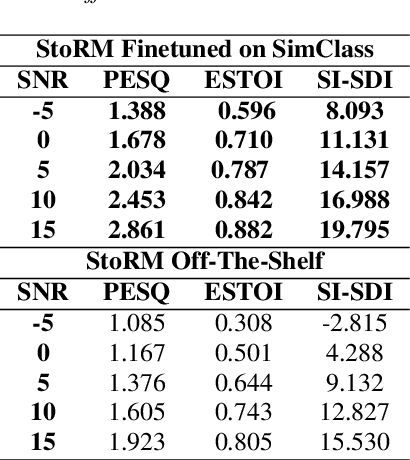
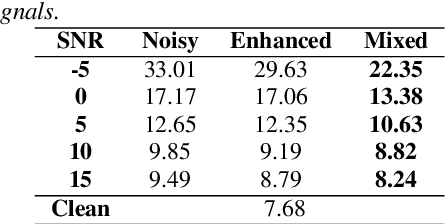
The scarcity of large-scale classroom speech data has hindered the development of AI-driven speech models for education. Public classroom datasets remain limited, and the lack of a dedicated classroom noise corpus prevents the use of standard data augmentation techniques. In this paper, we introduce a scalable methodology for synthesizing classroom noise using game engines, a framework that extends to other domains. Using this methodology, we present SimClass, a dataset that includes both a synthesized classroom noise corpus and a simulated classroom speech dataset. The speech data is generated by pairing a public children's speech corpus with YouTube lecture videos to approximate real classroom interactions in clean conditions. Our experiments on clean and noisy speech demonstrate that SimClass closely approximates real classroom speech, making it a valuable resource for developing robust speech recognition and enhancement models.
From Weak Labels to Strong Results: Utilizing 5,000 Hours of Noisy Classroom Transcripts with Minimal Accurate Data
May 20, 2025Recent progress in speech recognition has relied on models trained on vast amounts of labeled data. However, classroom Automatic Speech Recognition (ASR) faces the real-world challenge of abundant weak transcripts paired with only a small amount of accurate, gold-standard data. In such low-resource settings, high transcription costs make re-transcription impractical. To address this, we ask: what is the best approach when abundant inexpensive weak transcripts coexist with limited gold-standard data, as is the case for classroom speech data? We propose Weakly Supervised Pretraining (WSP), a two-step process where models are first pretrained on weak transcripts in a supervised manner, and then fine-tuned on accurate data. Our results, based on both synthetic and real weak transcripts, show that WSP outperforms alternative methods, establishing it as an effective training methodology for low-resource ASR in real-world scenarios.
Continued Pretraining for Domain Adaptation of Wav2vec2.0 in Automatic Speech Recognition for Elementary Math Classroom Settings
May 15, 2024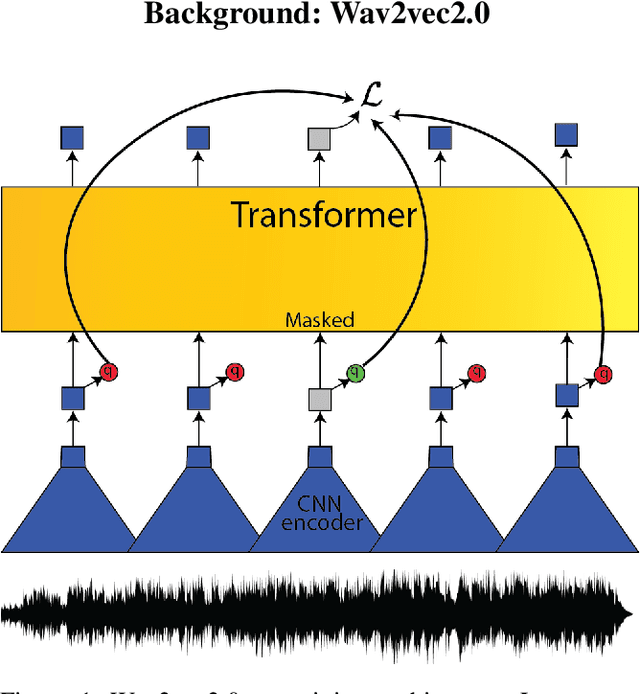
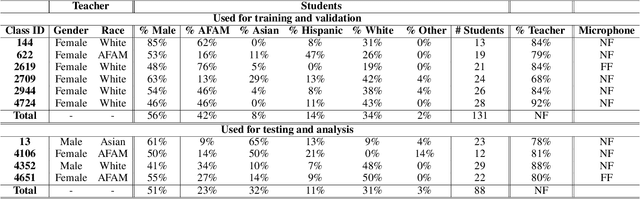
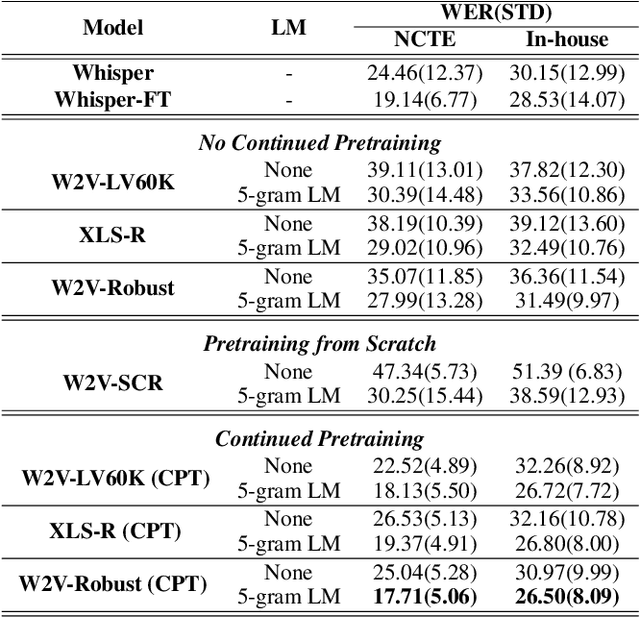
Creating Automatic Speech Recognition (ASR) systems that are robust and resilient to classroom conditions is paramount to the development of AI tools to aid teachers and students. In this work, we study the efficacy of continued pretraining (CPT) in adapting Wav2vec2.0 to the classroom domain. We show that CPT is a powerful tool in that regard and reduces the Word Error Rate (WER) of Wav2vec2.0-based models by upwards of 10%. More specifically, CPT improves the model's robustness to different noises, microphones, classroom conditions as well as classroom demographics. Our CPT models show improved ability to generalize to different demographics unseen in the labeled finetuning data.
Kid-Whisper: Towards Bridging the Performance Gap in Automatic Speech Recognition for Children VS. Adults
Sep 18, 2023



Recent advancements in Automatic Speech Recognition (ASR) systems, exemplified by Whisper, have demonstrated the potential of these systems to approach human-level performance given sufficient data. However, this progress doesn't readily extend to ASR for children due to the limited availability of suitable child-specific databases and the distinct characteristics of children's speech. A recent study investigated leveraging the My Science Tutor (MyST) children's speech corpus to enhance Whisper's performance in recognizing children's speech. They were able to demonstrate some improvement on a limited testset. This paper builds on these findings by enhancing the utility of the MyST dataset through more efficient data preprocessing. We reduce the Word Error Rate (WER) on the MyST testset 13.93% to 9.11% with Whisper-Small and from 13.23% to 8.61% with Whisper-Medium and show that this improvement can be generalized to unseen datasets. We also highlight important challenges towards improving children's ASR performance. The results showcase the viable and efficient integration of Whisper for effective children's speech recognition.
Improving Speech Inversion Through Self-Supervised Embeddings and Enhanced Tract Variables
Sep 17, 2023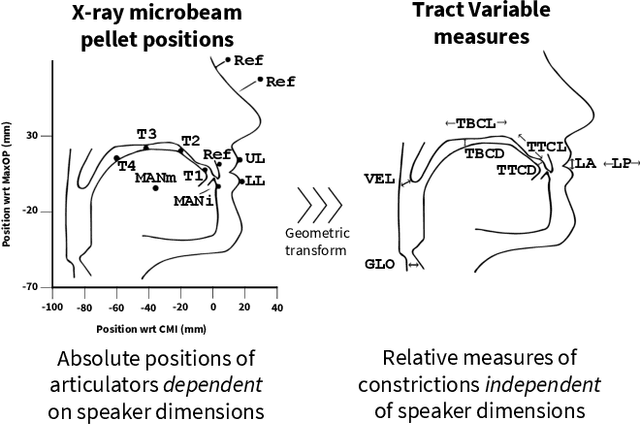
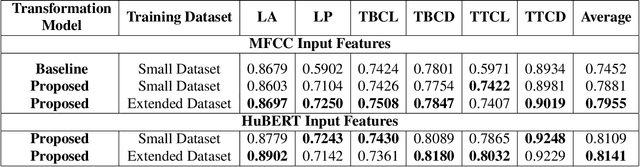
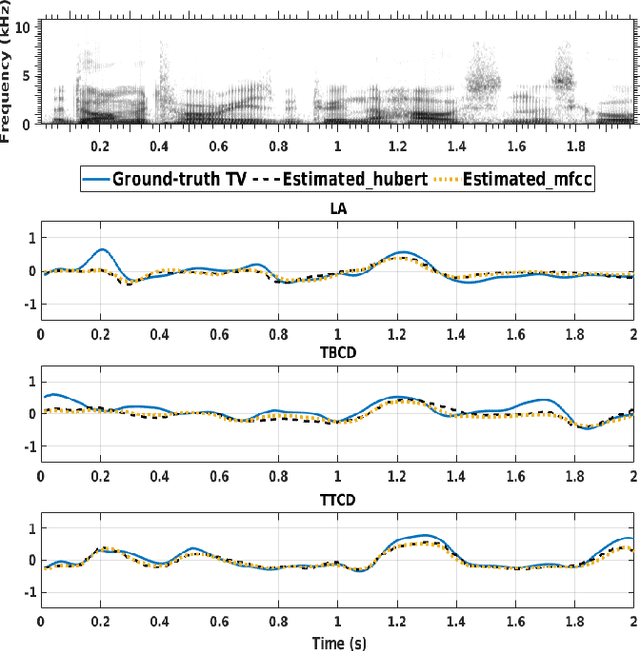
The performance of deep learning models depends significantly on their capacity to encode input features efficiently and decode them into meaningful outputs. Better input and output representation has the potential to boost models' performance and generalization. In the context of acoustic-to-articulatory speech inversion (SI) systems, we study the impact of utilizing speech representations acquired via self-supervised learning (SSL) models, such as HuBERT compared to conventional acoustic features. Additionally, we investigate the incorporation of novel tract variables (TVs) through an improved geometric transformation model. By combining these two approaches, we improve the Pearson product-moment correlation (PPMC) scores which evaluate the accuracy of TV estimation of the SI system from 0.7452 to 0.8141, a 6.9% increase. Our findings underscore the profound influence of rich feature representations from SSL models and improved geometric transformations with target TVs on the enhanced functionality of SI systems.
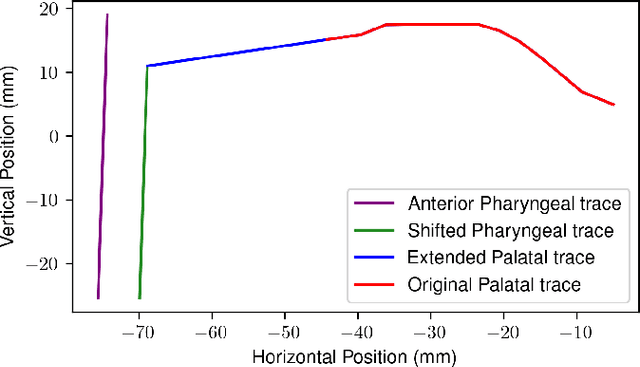
Enhancing Speech Articulation Analysis using a Geometric Transformation of the X-ray Microbeam Dataset
May 18, 2023


Accurate analysis of speech articulation is crucial for speech analysis. However, X-Y coordinates of articulators strongly depend on the anatomy of the speakers and the variability of pellet placements, and existing methods for mapping anatomical landmarks in the X-ray Microbeam Dataset (XRMB) fail to capture the entire anatomy of the vocal tract. In this paper, we propose a new geometric transformation that improves the accuracy of these measurements. Our transformation maps anatomical landmarks' X-Y coordinates along the midsagittal plane onto six relative measures: Lip Aperture (LA), Lip Protusion (LP), Tongue Body Constriction Location (TTCL), Degree (TBCD), Tongue Tip Constriction Location (TTCL) and Degree (TTCD). Our novel contribution is the extension of the palate trace towards the inferred anterior pharyngeal line, which improves measurements of tongue body constriction.
Masked Autoencoders Are Articulatory Learners
Oct 27, 2022
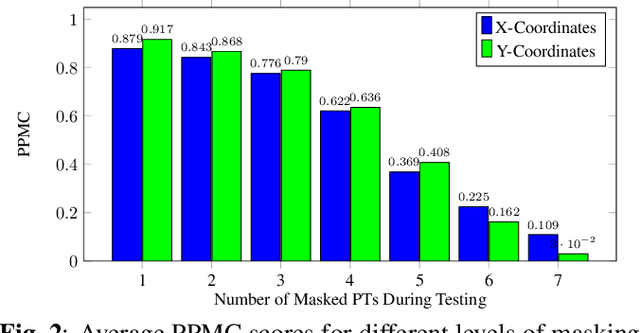


Articulatory recordings track the positions and motion of different articulators along the vocal tract and are widely used to study speech production and to develop speech technologies such as articulatory based speech synthesizers and speech inversion systems. The University of Wisconsin X-Ray microbeam (XRMB) dataset is one of various datasets that provide articulatory recordings synced with audio recordings. The XRMB articulatory recordings employ pellets placed on a number of articulators which can be tracked by the microbeam. However, a significant portion of the articulatory recordings are mistracked, and have been so far unsuable. In this work, we present a deep learning based approach using Masked Autoencoders to accurately reconstruct the mistracked articulatory recordings for 41 out of 47 speakers of the XRMB dataset. Our model is able to reconstruct articulatory trajectories that closely match ground truth, even when three out of eight articulators are mistracked, and retrieve 3.28 out of 3.4 hours of previously unusable recordings.
Audio Data Augmentation for Acoustic-to-articulatory Speech Inversion using Bidirectional Gated RNNs
May 25, 2022
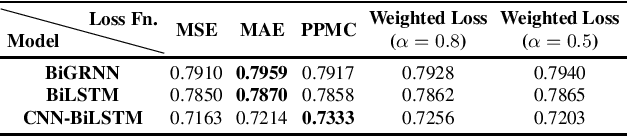
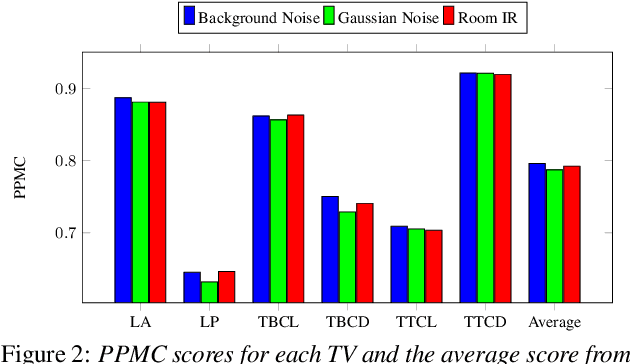
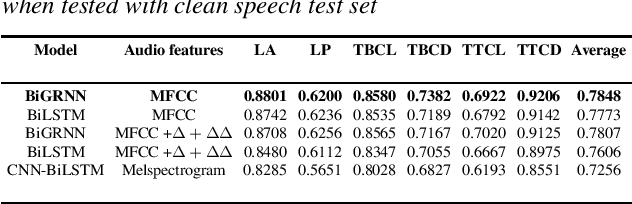
Data augmentation has proven to be a promising prospect in improving the performance of deep learning models by adding variability to training data. In previous work with developing a noise robust acoustic-to-articulatory speech inversion system, we have shown the importance of noise augmentation to improve the performance of speech inversion in noisy speech. In this work, we compare and contrast different ways of doing data augmentation and show how this technique improves the performance of articulatory speech inversion not only on noisy speech, but also on clean speech data. We also propose a Bidirectional Gated Recurrent Neural Network as the speech inversion system instead of the previously used feed forward neural network. The inversion system uses mel-frequency cepstral coefficients (MFCCs) as the input acoustic features and six vocal tract-variables (TVs) as the output articulatory features. The Performance of the system was measured by computing the correlation between estimated and actual TVs on the U. Wisc. X-ray Microbeam database. The proposed speech inversion system shows a 5% relative improvement in correlation over the baseline noise robust system for clean speech data. The pre-trained model, when adapted to each unseen speaker in the test set, improves the average correlation by another 6%.